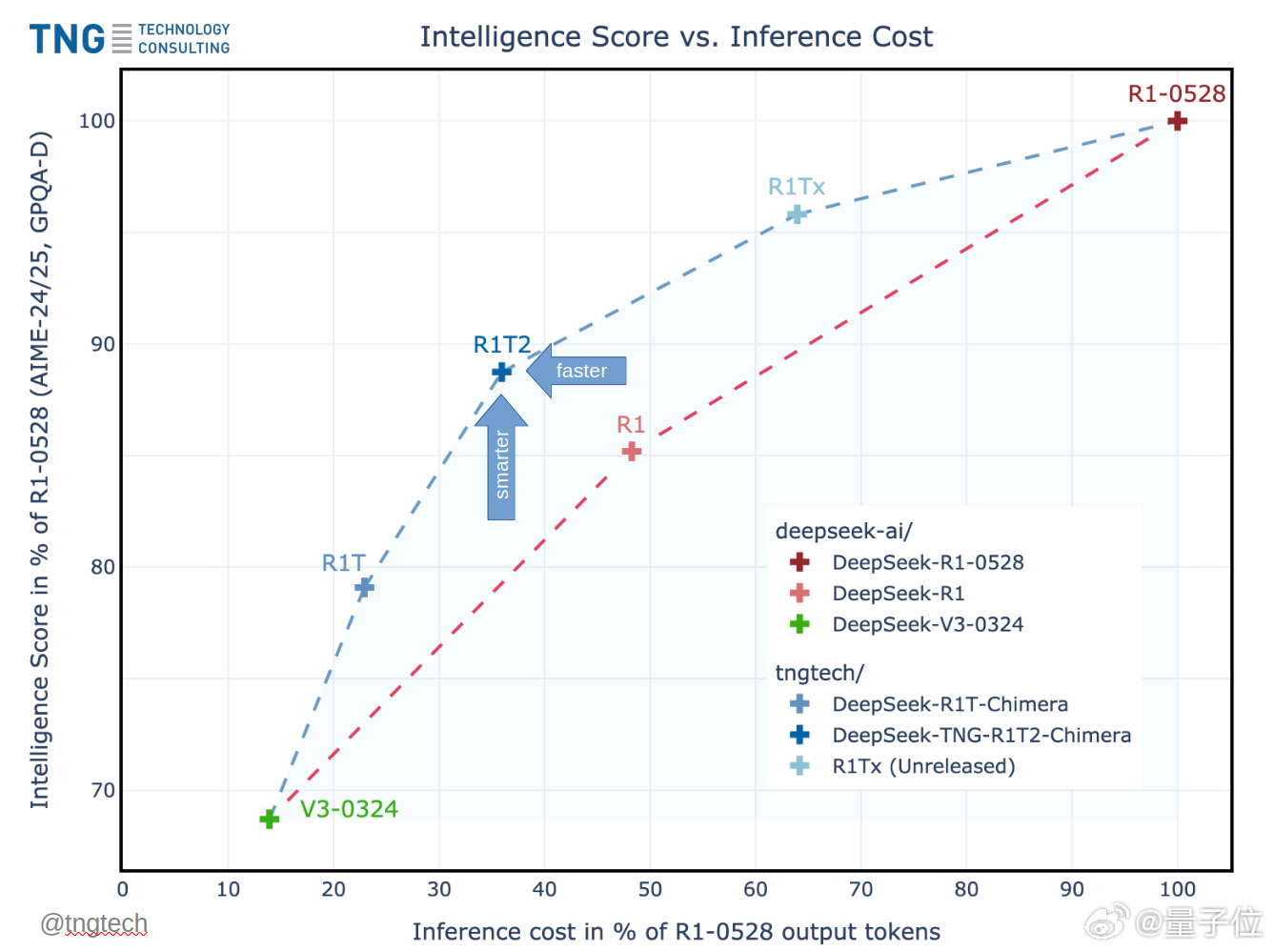
DeepSeek迎来性能增强DeepSeek优化版性能暴增
德国公司TNG在DeepSeek的基础上,创新性提出了AoE(Adaptive Expert)架构,其优化版本DeepSeek-TNG R1T2 Chimera,使DeepSeek推理效率提升了200%,而且还比R1-0528节省了约40%的输出token!
那么问题来了,AoE架构是什么?
AoE架构通过对多个预训练模型的权重张量进行插值,实现了新的子模型生成,整个过程几乎不需要重新训练,极大地节省了计算资源。
简单理解就是,AoE架构是一种让多个大模型合作的方式。
如果我们把大模型想象成“专家”,每个专家擅长不同领域的工作。AoE方法通过拼接这些专家的优点,创建出一个新的“超级专家”,并且避免了重头训练。
就像你请来了几个领域的大咖,借助他们的知识和经验来快速解决问题,而不是让每个大咖都从头开始准备。
AoE架构的优化主要体现在选择性合并上。
它并不盲目将所有模型的部分拼接在一起,而是通过选择那些最有效的、最具代表性的部分(就像从不同专家的答案中挑选出最有价值的),确保最终的“超级专家”既强大又高效。
一个意外的发现是,AoE方法的合并非常稳定。
即使在深度达到671B参数的规模时,所有合并模型都能稳定运行,展示了该方法的强大适应性。
无论是V3-0324还是R1作为父模型,所有的合并变体都能正常工作,展现出AoE架构的高容错性,为未来LLM的发展提供更多可能。
Hugging Face地址:
AoE架构论文: