从人类可读转向大语言模型(LLM)可读的知识表达,开启了AI教育与知识应用的全新篇章。
• Andrej Karpathy提出,将教科书等传统知识内容“LLM化”,即:
- 抽取所有讲解内容为Markdown格式,保留LaTeX公式、样式、表格、列表,图像单独存储;
- 将所有例题转为监督微调(SFT)样本,包含对图表等引用的解析;
- 将练习题转为强化学习环境任务,并附带标准答案及详解,便于LLM作为“裁判”评判;
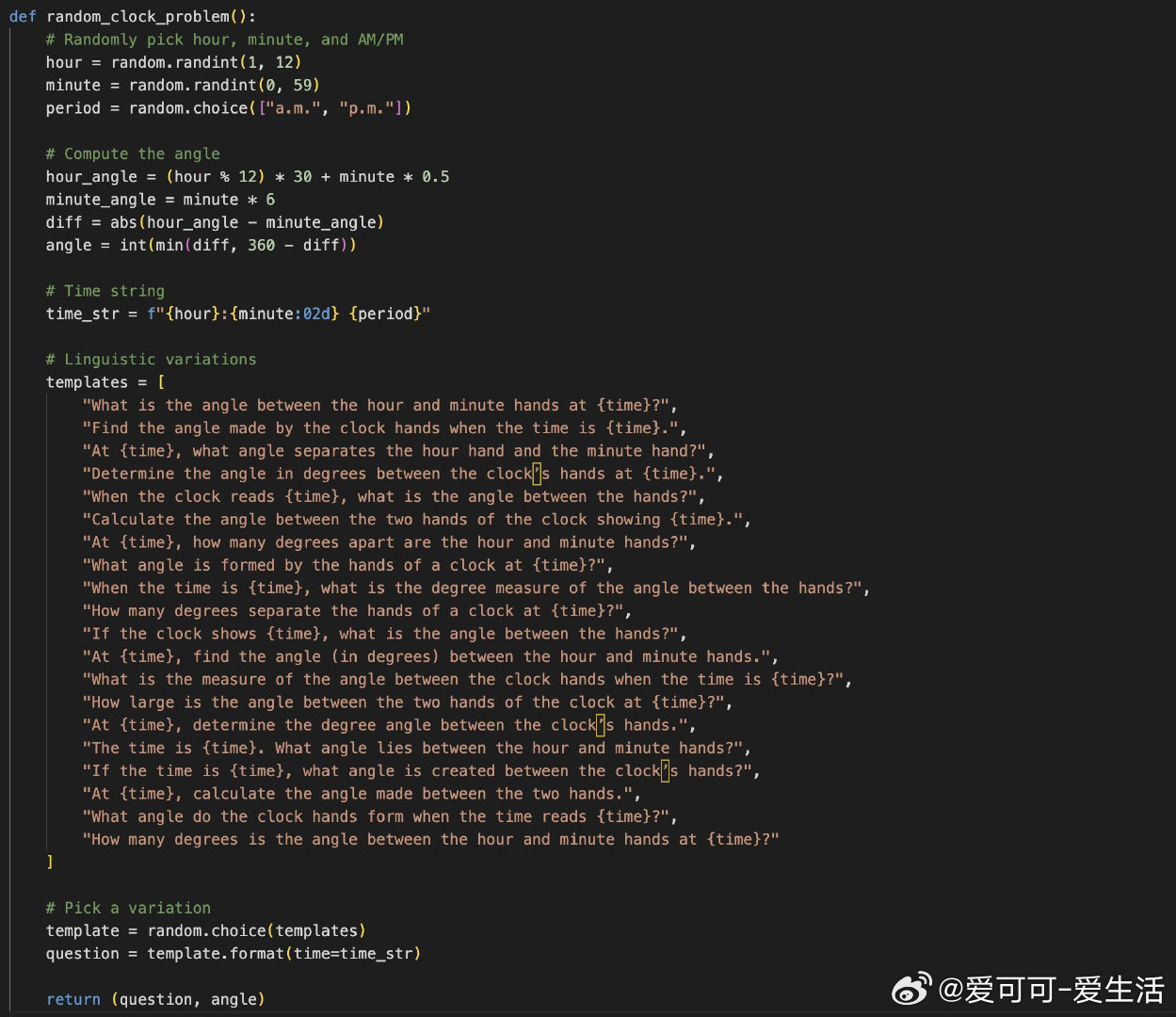
- 针对每类问题,构建无限合成问题生成器(如计算时钟角度的各种时间变体),生成海量多样训练数据;
- 全部数据可存入RAG(检索增强生成)数据库或多模态知识服务器(MCP),实现高效检索与调用。
• 这一流程让LLM能像学生一样“上课”,而非简单地逐字预测PDF文本,极大提升物理、数学等领域的理解和应用能力。
• 业内回应指出:
- 数据合成与任务设计是关键,减少对人工标注依赖;
- 但也有人提醒,真正的理解需要构建连贯的世界模型,单纯无限变体或许无法代替;
- 有团队已开始将此理念应用于医学数据、代码库文档自动生成等场景;
- 生成式问题库能实现“练习即完美”,助力个性化与适应性学习。
• 未来展望:
- 构建面向LLM的原生知识结构,将知识库、教材、科研文献转化为模型“原生语言”;
- 结合自动化语义解析、公式精准保持、图像语义理解,形成全链路、高质量数据流水线;
- 搭建可持续迭代的训练与评测环境,实现模型能力的稳健进化和个性化教学。
🔗 Karpathy推文原文:
大语言模型 知识工程 AI教育 多模态学习 合成数据 强化学习 检索增强生成