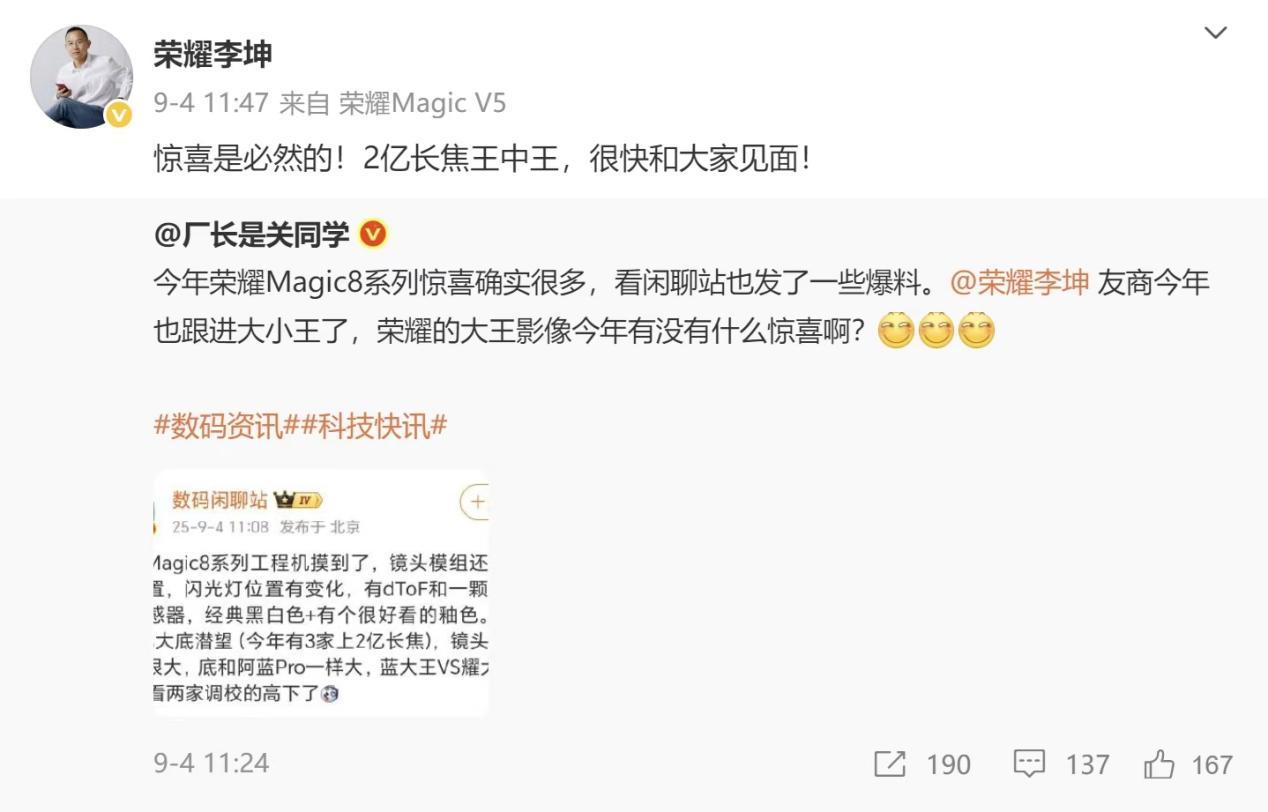
荣耀终端旗舰手机产品经理李坤发文爆料!“夜神”技术将随Magic8正式亮相,还点明该机配备“两亿长焦王中王”,一场夜拍实力对决即将开启。从这份信息来看,Magic8的影像表现值得期待,尤其是2亿像素长焦镜头的加入,不仅会实现“拍得远”的突破,更能让远景画面清晰度大幅提升。一直以来,荣耀在手机影像领域就有不错口碑,此次Magic8更是软硬件双管齐下:更强的硬件基础搭配自研软件优化,让夜拍能力再升级。无论是拍城市夜景还是星空,既能保证画面清晰、色彩真实,还能有效抑制噪点,呈现干净通透的成像效果。对追星族来说,用它拍明星演唱会,轻松捕捉偶像清晰瞬间。而且Magic8的亮点不止影像,还将在系统流畅度、AI功能等方面带来全面突破,有望解锁全新使用体验,这样的旗舰机型,确实让人满心期待。

![北汽这次看来真的想明白了,“地表最强的产品经理”[doge]享界s9t新品发布会](http://image.uczzd.cn/3294637828172172140.jpg?id=0)