pandas库可轻松地筛选出符合特定条件的数据,无需指定筛选的行和列。通过灵活运用pandas的筛选功能,我们能够高效、准确地获取到感兴趣的数据,本文将介绍以下几种方法,在不指定行列的情况下使用pandas进行数据筛选。
#导入数据,使用案例数据进行特定数据筛选DP_table=pd.read_excel(r'D:\JDNetDiskDownload\数据打包\经管训练营\电商销售数据-23年11月.xlsx', sheet_name='销售数据_清洗',#导入数据处理这个sheet表 dtype={'日期':'datetime64[D]'})DP_table#.head() 布尔索引
布尔索引这是最常见且直观的方法,通过条件来筛选数据。
DP_table[(DP_table['客户性别']=='女') & (DP_table['客户年龄']>61)][['区域','商品品类','销售数','销售额','利润']]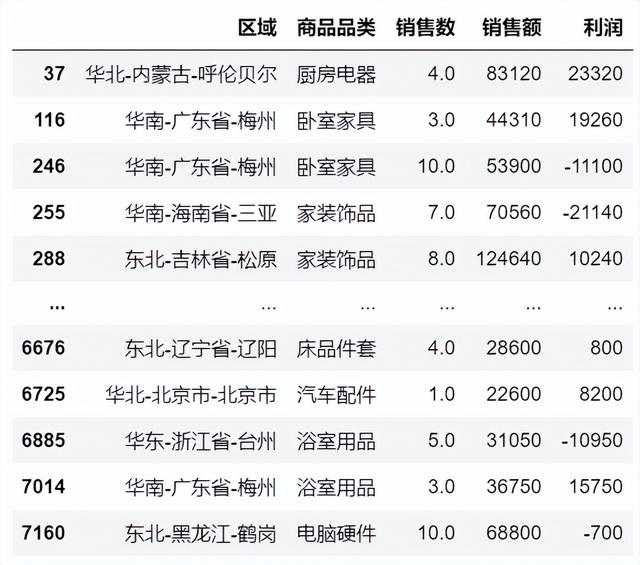 isin()方法
isin()方法当需要筛选特定列中包含某些特定值的行时,可以使用isin()方法。
DP_table[DP_table['商品品类'].isin(['床品件套', '家装饰品'])] loc和iloc方法
loc和iloc方法loc基于标签选择数据,而iloc基于整数位置选择数据。
#按照索引标签选择DP_table.loc[[0,2,4,6,8,10]][['区域','商品品类','销售数','销售额','利润']]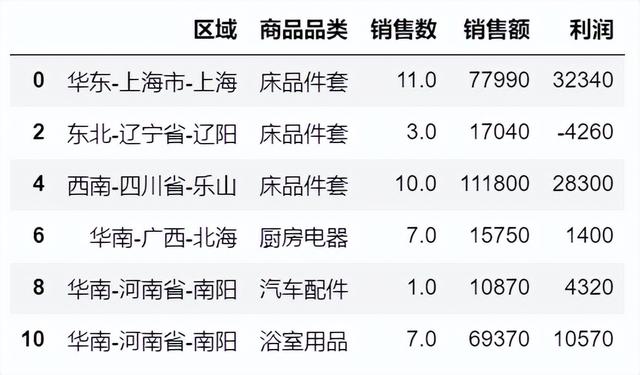 #选择特定列DP_table.iloc[:,[0,2,4]]
#选择特定列DP_table.iloc[:,[0,2,4]]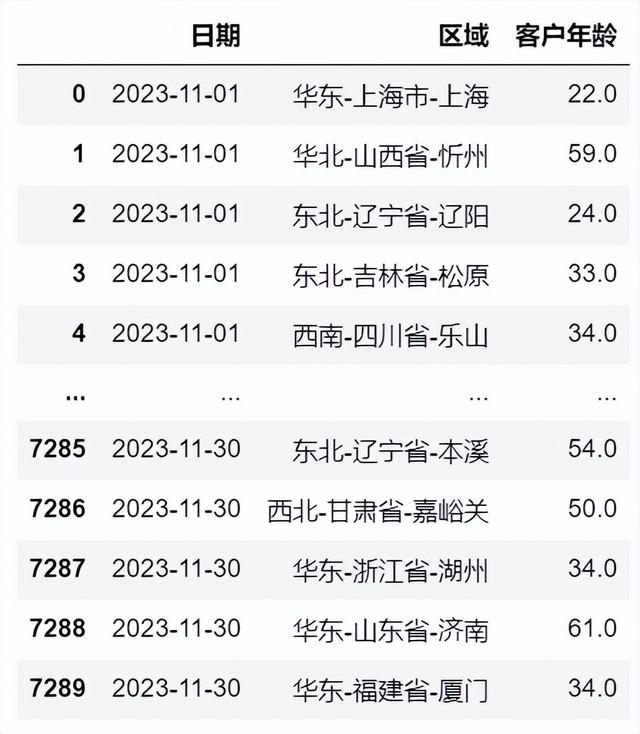 #选择连续列DP_table.iloc[:,0:4]
#选择连续列DP_table.iloc[:,0:4]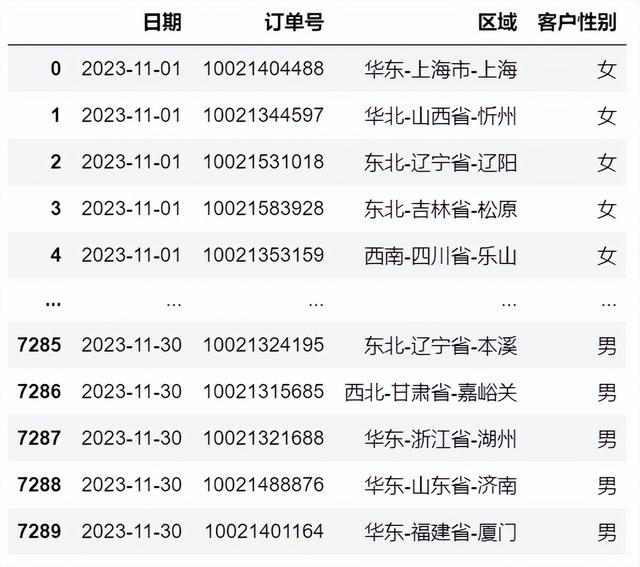 #选择特定行DP_table.iloc[[0,2,4,6],]
#选择特定行DP_table.iloc[[0,2,4,6],] #选择连续行DP_table.iloc[0:7,]
#选择连续行DP_table.iloc[0:7,] query()方法:
query()方法:你可以使用query方法基于一个或多个条件来筛选数据
DP_table.query('利润 > 300000') between()方法
between()方法这个方法用于筛选特定列中值在给定范围内的行。
DP_table[DP_table['日期'].between('2023-11-11', '2023-11-13')] 使用特定字符串方法
使用特定字符串方法对于字符串数据,pandas提供了许多用于筛选的方法,如str.contains(), str.startswith(), str.endswith()等。
DP_table[DP_table['区域'].str.contains('甘肃省')] DP_table[DP_table['区域'].str.startswith('西北')]
DP_table[DP_table['区域'].str.startswith('西北')] DP_table[DP_table['区域'].str.contains('兰州')]
DP_table[DP_table['区域'].str.contains('兰州')]
通过以上方法,可以在不指定行列的情况下,轻松实现pandas数据的筛选。这几种筛选方式具有很高的灵活性和实用性,让你在数据处理的过程中更加得心应手,如果你在代码实践过程中遇到问题,可在评论区留言,解决你的代码问题~