全文约2500字;
阅读时间:约7分钟;
听完时间:约14分钟;

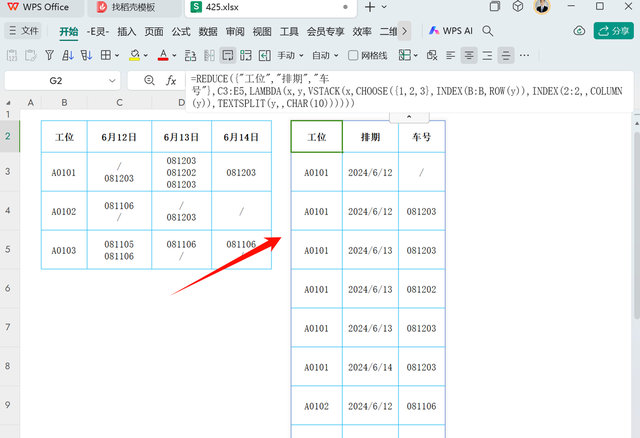
在生产计划的排程过程中,有时会采用一种特殊的“三维”数据表来安排任务,这种视图能够展示更丰富的信息层面,从而使用户能捕捉到更多细节。不过,这种做法也不可避免地牺牲了某些便捷性,比如快速数据分析、数据汇总和过滤等功能。鉴于此,在设计这类复杂表格时,为了加速数据的分析流程,创建与之匹配的一维转换表不失为一个高效策略——即将“三维”数据转换成易于分析的一维格式,进而实施数据分析。这种方法,即“三维转一维”,再从一维基础上进行深入分析,大大提升了工作效率。
 案例展示
案例展示让我们通过一个具体示例来阐述如何设计一个自动化的“三维转一维”表格。首先,审视一下原始的“三维”表格结构,以表一为例:在B列,我们记录了排程的工位信息,例如B3至B5单元格分别列出工位代码{"A0101";"A0102";"A0103"}。横向来看,C2至E2列代表了不同日期,依次是6月12日、13日和14日。表格的核心内容位于这些行列的交叉点上,比如D3单元格,它可能包含如下车号序列:081203、081202及081203,各个车号间使用换行符分隔。若某工位在特定日期未安排车辆,则相应单元格会被填入“/”表示无排程。
将上述复杂的“三维”表格转换为一维格式时,主要难点在于处理交叉单元格中包含的多车号信息,这些信息需被分开并精确匹配到各自的工位与日期上。解决此问题的一个方法是,首先运用TEXTSPLIT函数结合CHAR(10)来识别并拆分每个单元格内部的车号序列(利用换行符作为分隔)。
随后,利用诸如OFFSET和CHOOSE这样的函数组合,来更准确地重构数据,确保每个独立车号都能正确关联到其原始的工位和日期记录。这样,我们就能够有效地将复杂数据转变为易于管理和分析的一维表格形式。
 分离车号
分离车号首要步骤是将单元格中的车号逐一拆分出来,利用它们之间的换行符作为分隔标准进行分离。在适当的单元格中输入以下函数实现这一操作:
=TEXTSPLIT(C3,,CHAR(10))
该函数的解释如下:
TEXTSPLIT函数是WPS中用于按指定分隔符拆分文本字符串的工具。
C3是指定需要拆分的单元格,即包含多个车号的源数据所在位置。
CHAR(10) 指定了分隔符为换行符(在ASCII码中,10代表换行),用来识别并分割单元格内的不同车号。
通过执行此函数,原来合并在一起的车号将依据换行符号被分开,为后续构建一维表格并关联每个车号到具体工位和日期打下基础。
 构建数组
构建数组在处理这三维数据时,车号经分离后形成的序列构成了一个新的、独立的一维数据列,与之相匹配的,还需为每个车号明确其对应的“工位”和“日期”。简言之,车号数组中的每个元素都需要有相应数量的工位和日期与之配对。为此,在适当的位置应用以下函数构造这一关系: =CHOOSE({1,2,3},B3,TEXTSPLIT(C3,,CHAR(10)),C2)
此公式利用CHOOSE函数,通过指定的顺序(序号)从一系列值中选取数据,构建一个结构化的一维数组。具体参数意义如下:
第1参数:序号数组 {1,2,3} 分别指代“工位”、“车号”、“日期”这三个维度的顺序。
1 对应选取的值为工位信息。
2 对应选取的值为经过TEXTSPLIT处理后得到的车号序列。
3 对应选取的值为日期信息。
第2参数:B3 单元格的内容,代表工位号,此为单个元素。
第3参数:使用TEXTSPLIT(C3,,CHAR(10))来拆分C3单元格中的车号,生成一个车号数组。例如,结果是 {"/", "081203"},其中"/"表明某个工位在某日没有排程或有一个排程。
第4参数:C2 单元格的日期,如“6月12日”。
通过精心设计的参数列表,确保每个车号都有相应的工位和日期与之配对,形成完整的一维数据结构,以便于进一步的数据处理和分析。返回结果:{"A0101","/",45455;"A0101","081203",45455},如下图所示:
 参数转换
参数转换起初获得的结果局限于单一单元格,为了将其扩展至多行数据,我们采用REDUCE函数进行垂直堆叠。但在执行堆叠之前,必须先确定与B3单元格相对应的行号和列号,作为后续REDUCE操作中Y值序列定位的基础。观察数据布局可得,车号所在的行即代表车位行数,而日期所在列则指示了具体的列位置。举例来说,如果工位信息位于C3,则其对应的是第3行第2列;若位于D3,则属于第3行第3列。基于此逻辑,我们可以利用INDEX函数精确定位:
工位定位:=INDEX(B:B, ROW(C3)),此公式会返回所在行的工位编号,比如"A0101"。
日期定位:=INDEX(2:2, , COLUMN(C3)),用于获取与车号同列的日期信息,例如"6月12日"。公式代入:
=CHOOSE({1,2,3},INDEX(B:B,ROW(C3)),TEXTSPLIT(C3,,CHAR(10)),INDEX(2:2,,COLUMN(C3)))
效果如下图所示:
 执行堆叠
执行堆叠在完成前期准备工作后,接下来执行数据的垂直堆叠操作,使用REDUCE函数实现这一目标。请在适合的位置输入以下公式:
=REDUCE({"工位","排期","车号"},C3:E5,LAMBDA(x,y,VSTACK(x,CHOOSE({1,2,3},INDEX(B:B,ROW(y)),INDEX(2:2,,COLUMN(y)),TEXTSPLIT(y,,CHAR(10))))))
步骤说明:
初始值设定:{"工位", "日期", "车号"} 作为堆叠结果的表头行。
数组范围:C3:E5 指定了需要处理的车号区域,这一范围可根据实际排程的增减灵活调整。
LAMBDA函数应用:定义了一个匿名函数,其中:
x 代表累积器变量,初始化为表头,每次迭代中累积新的数据行。
y 代表当前迭代处理的单元格,即C3:E5范围内的每一个车号所在单元格。
在匿名函数内部,CHOOSE函数根据序号选择对应的值:
工位通过INDEX(B:B, ROW(y))根据y的行号动态获取。
日期通过INDEX(2:2, , COLUMN(y))根据y的列号动态获取。
车号则继续使用TEXTSPLIT(y, ,, CHAR(10))进行拆分。
VSTACK操作:在每次迭代中,VSTACK函数负责将新生成的一行数据(包括工位、日期和拆分后的车号)垂直堆叠到累积器x之上,逐步构建完整的、一维结构的表格数据。
通过上述公式,即可实现从复杂“三维”表格到有序一维表格的转换与堆叠,便于后续的数据分析与处理。
 最后总结
最后总结总之,面对生产计划排程中复杂且信息密集的“三维”数据表,采取有效的策略将其转换为一维表格,是提升数据处理效率与分析深度的关键。本文通过一个详实的案例,展示了如何利用WPS函数如TEXTSPLIT、CHOOSE、INDEX以及REDUCE等,系统性地解决了数据拆分、重组及堆叠的挑战,成功地将多维数据整合为易于操作和理解的一维格式。
此过程不仅强调了数据预处理的重要性,还突显了灵活运用现代电子表格软件高级功能以适应复杂数据分析需求的能力。通过“三维转一维”的自动化流程,我们不仅保留了原始数据的所有关键信息,还极大增强了数据的可访问性和分析灵活性,使得后续的统计汇总、筛选查找及可视化等工作变得直接而高效。
最终,这一解决方案不仅简化了数据分析师或生产计划制定者的日常工作,减少了手动处理的繁琐与出错概率,还为企业决策提供了更加坚实的数据支撑平台。实践证明,合理应用技术手段优化数据结构,是提升业务流程智能化水平和响应速度的有效途径,对于推动生产管理乃至整个组织的数字化转型具有重要意义。