全文约2500字;
阅读时间:约8分钟;
听完时间:约16分钟;

在日常的PMC生产计划工作中,分析含有合并单元格的数据表并进行多条件求和是一项较为棘手的任务。如下图所示,以B列为例,它垂直列示了产品A、B各自的日使用量,且指明这些产品属于“L/R”(左侧/右侧)。这里,A4:A5单元格是合并的,意在表示A4行代表“L”,A5行代表“R”,B列同样存在这样的合并情况,后续还有C列、D列等涉及产能的信息。
同时,这些产品的日使用量在水平方向上也采用合并单元格的形式展现。具体来说,D2:E2为一个合并单元格,表示的是4月17日;F2:G2则是另一个合并单元格,代表4月18日。紧接着的行如D3:E3则标注了这些合并单元格的数据维度——“日使用量”与“状态”。这样,数据表形成了一个由日期、班次(通过L/R标识)、产品以及状态这四个维度交织的复杂区域。例如,我们可以得知4月17日,A班在左侧(L)的产品日使用量为25,其状态标记为备用。
 需求分析
需求分析针对上述复杂的“四维”数据结构,我们的分析目标明确为:“汇总各产品在不同日期的日使用量,并以二维表格形式展示。”简而言之,就是要完成从四维到二维信息的转化处理。
具体实施时,首先需在垂直方向上对产品进行去重,确保每个产品仅出现一次。水平方向上,则应设置日期作为单独的一列,而与之交错的区域则用来汇总各产品的日使用量。汇总时,需把“备用”和“在线”两种状态,二者汇总统计。
实现这一目标的主要挑战在于如何有效处理合并单元格的问题。一旦成功分离这些合并单元格,接下来就可以运用筛选函数结合列函数,根据设定的条件(如特定产品和日期)来准确求和,从而达成数据的二维汇总展示。
 去除合并
去除合并首先,针对原始表格中含合并单元格的区域进行处理,在适当的位置输入以下公式:
=SCAN("", B4:B7, LAMBDA(X, Y, IF(Y = "", X, Y)))
函数说明如下:
我们关注的范围是B4到B7的合并单元格,这些单元格虽然外观上显示数据为间隔的{"A";空值;"B";空值},但实际上需要连续填充。
利用SCAN函数进行迭代处理,其中:
初始值 X 被设定为一个空字符串(表示为""),而非其他值。
Y 代表序列B4至B7中的每一个单元格值。
SCAN函数依据Lambda函数的逻辑逐步执行:每当遇到Y为空(意味着遇到了合并单元格的视觉“空白”部分),就保留前一个非空值X;如果Y非空,则直接返回当前的Y值。
经过该公式的计算,我们会在垂直方向上获得一个已消除合并效果的数组结果:{"A";"A";"B";"B"},从而为后续的数据分析奠定了基础。
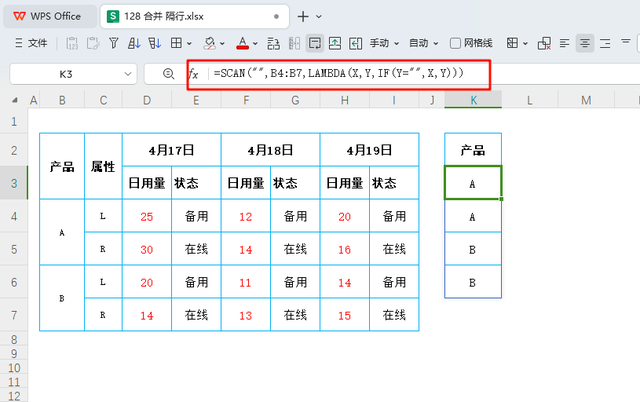 二维数据:
二维数据:为了将复杂的四维数据转换为二维格式,我们首先着手整理两个关键方向的数据。在垂直方向上,开始于K2单元格,输入标题“产品”。紧接着,在K3单元格中,应用以下公式来进行初步的数据处理:
=DROP(SORT(UNIQUE(B4:B7)),1)
公式说明如下:
该公式旨在从B4至B7的范围内剔除重复项,仅保留唯一的“产品”名称。
UNIQUE函数用于选取该范围内的唯一值,但由于合并单元格可能导致出现看似空白实为0的情况,
接着,通过SORT函数对这些唯一值进行排序,确保数值0(代表视觉上的空白合并单元格)排在最前面。
最后,使用DROP函数并指定参数1,目的是移除排序后位于首位的0或空白项,确保结果列表干净、准确地只包含不同的产品名称。

至于水平方向,我们安排的是日期序列,鉴于日期遵循明确的模式。原始四维数据涵盖3天的时间跨度,因此,采用以下简洁公式即可横向生成日期序列:
=SEQUENCE(,3,"2024-4-17")
函数说明如下:
此公式按行(水平方向)生成一个包含3个元素的序列,起始日期设定为“2024年4月17日”,由于未指定步长,默认增量为1,从而直接产出从4月17日至4月19日连续三天的日期。如果实际数据时段超出了这个范围,只需简便地调整序列的长度数值,例如改为30,即可得到从4月17日起往后的连续30天日期序列。
 筛选数据:
筛选数据:在确定了前两个维度的数据之后,可以应用以下公式进行筛选以满足这两个条件:
=FILTER(D4:I7,SCAN("",B4:B7,LAMBDA(X,Y,IF(Y="",X,Y)))=K3)
这一公式的功能解释如下:
显示区域:D4:I7 区域包含了日期对应的各产品的每日用量及状态(如“备用”、“在线”)的具体信息。
条件准备:通过 SCAN 函数处理B4:B7区域,以消除合并单元格的影响,生成一个连续的标签序列{"A";"A";"B";"B"},确保每个产品名与其下方的数据正确对齐。
条件值:参考单元格 K3 中的值,这里假设为“A”,作为筛选的基准。
因此,该公式的执行结果会显示出符合“A”产品标准的日用量及状态数据范围。
 按列汇总:
按列汇总:有了筛选出的数据,接下来便能轻易地按日期进行汇总求和。上述筛选公式得出的结果是一个结构化的数组:{25,"备用",12,"备用",20,"备用";30,"在线",14,"在线",16,"在线"},这样的数据排列规整,非常适合进一步的计算处理。
要实现按列求和,可采用如下公式:
=BYCOL(FILTER(D4:I7, SCAN("", B4:B7, LAMBDA(x, y, IF(y = "", x, y))) = K3), SUM)
这一公式的运作机制简述如下:
首先,利用先前设定的筛选条件,从原始数据范围 D4:I7 中提取与 K3(比如产品"A")匹配的行。
然后,通过 BYCOL 函数沿列方向对提取的数据进行操作,应用 SUM 函数计算每列的总和。
最终计算结果会体现出数值列的求和值,而针对文本(如“备用”、“在线”状态)列,求和自然得到0,从而得到结果为 {55,0,26,0,36,0},清晰展示了各列数字的汇总情况及忽略了文本信息的求和影响。
 日期汇总
日期汇总为完成最终的按日期汇总,考虑到实际需求是提取并汇总上述结果中的第1、第3和第5列等奇数列数据,可以应用以下公式来实现这一目的:
=INDEX(BYCOL(FILTER($D$4:$I$7,SCAN("",$B$4:$B$7,LAMBDA(X,Y,IF(Y="",X,Y)))=K3),SUM),SEQUENCE(,3,1,2))
此公式的详细解释如下:
首先,依旧利用之前的筛选逻辑,通过 FILTER 函数结合 SCAN 处理,确保只考虑与 K3 指定产品匹配的行数据。
接着,利用 BYCOL 和 SUM 函数按列求和,获得每列的总和数组。
接下来,运用 INDEX 函数与 SEQUENCE 函数的搭配,旨在选取特定列的汇总和。具体来说,这里利用 SEQUENCE 函数生成一个序列,起始于1,每次增加2,总共生成3个数字,以此来代表所需的第1、第3和第5列的列序。因此,SEQUENCE 实际上产出的是序列{1, 3, 5},指示了选取求和结果时关注的列位置。因此,此公式将输出所选产品在不同日期下,针对特定列(如日用量)的汇总数据。
 最后总结:
最后总结:综上所述,面对PMC生产计划中复杂且含有合并单元格的四维数据表,我们通过一系列精心设计的WPS公式策略,成功实现了数据的去合并、重塑与高效汇总。关键步骤包括利用SCAN函数去除垂直方向的合并单元格问题,应用UNIQUE、SORT、DROP函数整理产品列表,以及利用SEQUENCE函数生成日期序列,构建起清晰的二维框架。随后,通过FILTER函数配合SCAN处理结果,精准筛选符合条件的数据行,保证数据筛选的准确性。BYCOL与SUM函数的组合则巧妙地完成了按列的汇总求和任务,针对特定需求,INDEX与SEQUENCE的协作更是精确定位并提取了所需列的汇总信息,最终达成了“汇总各产品在不同日期的日使用量,并以二维表格形式展示”的核心目标。
这一过程不仅展现了WPS高级功能在处理复杂数据挑战中的强大应用潜力,还强调了逻辑思维与工具技巧结合的重要性。用户现在能够直观地查看和分析每个产品的日使用总量,无论是进行生产调度还是库存管理,都能够基于这份清晰的二维汇总表做出更加精准及时的决策。整个解决方案不仅优化了数据处理流程,提高了工作效率,还确保了数据汇总的准确无误,为企业的生产计划管理提供了坚实的数据支撑。