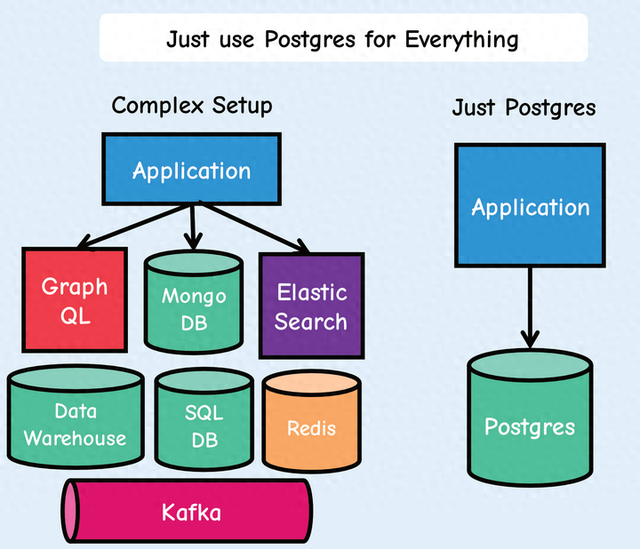
曾经流传已久的简单美的架构思想已经被到处卷的现代IT给抛弃了。系统变得越来越大,分系统越来越多,架构越来与复杂,出现问题排查越来越难。那么回归简单不好么?关键是怎么实现成了一个问题,今天我们就介绍一个以Postgres为基础的,简化堆栈、减少移动部件、加快开发速度、降低风险并的方法,那就是“用Postgres取代一切”!这种方法特别适合一些刚刚开始的初创公司和还在探索优化架构的那些组织。
简单来说就是用Postgres取代几乎所有的后端数据库和数据缓存层,其中包括Kafka、RabbitMQ、Mongo和Redis。这可以让每个应用程序都更易于开发、扩展和操作。移动部件较少可以让开发人员把精力和时间不要放在这些不提供价值或仅复制现有功能(前端)的部件上,而为把精力和时间都卷在全力为客户提供价值的部件上来。
 概述
概述一切都使用Postgres!
使用Postgres代替Redis进行缓存,并使用UNLOGGED表和TEXT作为JSON数据类型。使用存储过程或使用ChatGPT为编写它们,为数据添加和强制执行到期日期,就像在Redis中一样。
使用Postgres 作为cron在特定时间执行操作,例如发送邮件,并使用pg_cron将事件添加到消息队列。
消息队列使用Postgres的SKIP LOCKED来是先,而不用Kafka。或者可以用Golang的River作业队列。
Postgres Timescale作为数据仓库。
Postgres pg_analytics结合Apache Datafusion使用作为内存OLAP,可以实现高性能查询。
Postgres使用带有JSONB将Json文档存储在数据库中,对它们进行搜索和索引,而不用Mongo。
使用Postgres进行地理空间查询。
使用Postgres代替Elastic进行全文搜索。
使用Postgres在数据库中生成JSON,无需编写服务器端代码,直接交给API。
使用Postgres进行pgaudit审计
如果需要,将Postgres与 GraphQL适配器结合使用来提供GraphQL。
一切都使用Postgres!
数据缓存在Postgres中可以使用缓存表,来做为数据缓存:
CREATE UNLOGGED TABLE cache (id serial PRIMARY KEY,key text UNIQUE NOT NULL,value jsonb,inserted_at timestamp);CREATE INDEX idx_cache_key ON cache (key);与普通表的唯一区别是UNLOGGED关键词。至于列,使用的是JSONB值,但可以使用任何适合需要的值,例如text, varchar或者hstore。还包括inserted_at列,该列将用于缓存失效。还创建一个索引以获得更好的读取性能。
当然缓存服务应该具有的功能应该包括:缓存条目的过期。在PostgreSQL中可以通过创建一个定期删除旧行的存储过程:
CREATE OR REPLACE PROCEDURE expire_rows (retention_period INTERVAL) AS$$BEGINDELETE FROM cacheWHERE inserted_at < NOW() - retention_period;COMMIT;END;$$ LANGUAGE plpgsql;CALL expire_rows('60 minutes'); -- This will remove rows older than 1 hour为了定期调用这个expire_rows程序。可以使用PostgreSQL的另一个大法宝pg_cron。
可以通过以下方式安排过程调用:
-- 创建一条每小时执行的定期任务SELECT cron.schedule('0 * * * *', $$CALL expire_rows('1 hour');$$);如果不想为此安装扩展,那么也可以编写一个每次插入行时运行的触发器:
CREATE OR REPLACE FUNCTION expire_rows_func (retention_hours integer) RETURNS void AS$$BEGINDELETE FROM cacheWHERE inserted_at < NOW() - (retention_hours || ' hours')::interval;END;$$ LANGUAGE plpgsql;CREATE OR REPLACE FUNCTION expire_rows_func_trigger() RETURNS trigger AS$$BEGINPERFORM expire_rows_func (1);RETURN NEW;END;$$ LANGUAGE plpgsql;CREATE TRIGGER cache_cleanup_triggerAFTER INSERT ON cacheFOR EACH ROWEXECUTE FUNCTION expire_rows_func_trigger();显然,实际的到期/清除时间表取决于数据和用例。
作业调度用Redis做为数据缓存层或者用于协调后台作业队列(以及一些有限的原子操作)是现代架构中常见的方式,但是实际上这些都可以使用PostgreSQL来实现,且效率比Redis更好。
作业调度
Redis最常见的用途是协调从Web服务到后台程序池的作业调度。比如希望记录执行某些后台作业的愿望(可能需要一些输入数据),并确保只有众多后台工作人员之一会接手它。 Redis对此有所帮助,因为它为其数据结构提供了一组丰富的原子操作。
PostgreSQL 9.5中新发布了一个功能SKIP LOCKED选项为SELECT ... FOR ...。当指定此选项时,PostgreSQL将忽略任何需要等待锁释放的行。
从后台工作者的角度考虑这个例子:
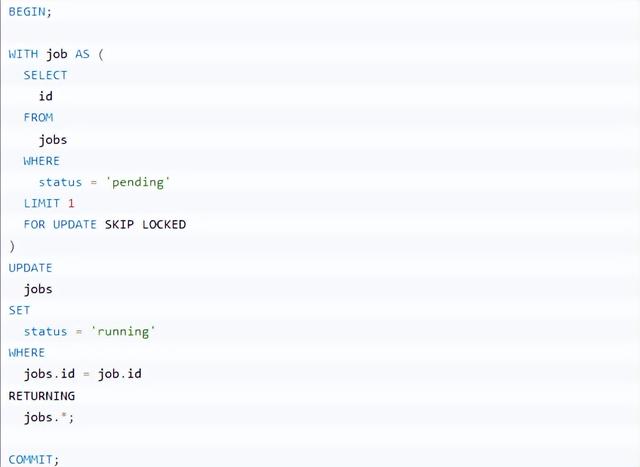
通过指定FOR UPDATE SKIP LOCKED,对于从返回的任何行隐式获取行级锁 SELECT。 此外,因为指定SKIP LOCKED,该语句不可能阻塞另一个事务。如果还有其他作业可供处理,则会返回该作业。由于行级锁,不必担心运行此命令的多个工作程序会接收同一行。
应用程序锁
假设有一个与第三方服务的同步例程,并且只希望在所有服务器进程中为任何给定用户运行该例程的一个实例。这是Redis另一个常见应用:分布式锁定。
PostgreSQL也可以使用其咨询锁来实现这一点。建议锁允许利用PostgreSQL 内部使用的相同锁定引擎来实现自己的应用程序定义的目的。
发布/订阅
例如,假设需要通知用户有一条新消息可供阅读。或者可能希望在数据可用时将数据流式传输到客户端。通常,Web套接字是这些事件的传输层,而Redis 则充当发布/订阅引擎。
从PostgreSQL 9开始,PostgreSQL开始支持LISTEN和NOTIFY声明。任何PostgreSQL客户端都可以订阅(LISTEN)到特定的消息通道,它只是一个任意字符串。当任何其他客户端发送消息时(NOTIFY)在该频道上,所有其他订阅的客户端都将收到通知。或者,可以附加一条小消息。对于使用Rails和ActionCable的通许,可以直接调用PostgreSQL替换。
TimescaleDB
TimescaleDB构建在PostgreSQL之上的时间序列数据库。它旨在处理大量带有时间戳的数据,并为时间序列数据提供高效且可扩展的查询性能。
TimescaleDB针对存储和查询时间序列数据进行了优化,扩展了PostgreSQL,提供专门针对时间序列数据管理的附加特性和功能,例如自动时间分区、优化索引和压缩。
TimescaleDB采用分布式超表架构,根据时间间隔对数据进行分区,从而能够随着时间的推移高效查询大量数据。它还为时间序列数据提供高级分析和可视化功能,包括连续聚合和窗口函数。
pg_analyticspg_analytics是个用于加速Postgres分析性能的扩展,安装pg_analytics Postgres可实现比Elasticsearch快8倍的性能。pg_analytics直接在Postgres 内加速分析查询,pg_analytics是Postgres中分析的嵌入式解决方案,无需提取、转换和 将(ETL)数据加载到另一个系统中。
常规Postgres表(称为堆表)按行组织数据。虽然这对于操作来说是有意义的 数据,对于分析查询来说效率低下,分析查询通常从数据的子集中扫描大量数据 表中的列。ParadeDB引入了一种新的表,称为parquet表。parquet表的行为与常规 Postgres表类似但通过Apache Arrow使用面向列的布局并利用 Apache DataFusion 对面向列的数据进行了优化。这意味着用户可以在面向行和列的存储之间进行选择表创建时间。
Arrow和Datafusion通过Postgres API的两个功能与Postgres集成:表访问方法和执行器hook。表访问方法寄存器parquet带有Postgres目录的表并处理数据 操作语言 (DML) 语句,例如插入。执行器hooks拦截查询并将其重新路由到 DataFusion,它解析查询,构建最佳查询计划,执行它,并将结果返回到 Postgres。
数据使用Parquet持久保存到磁盘,Parquet是一种用于面向列的数据的高度压缩文件格式。Parquet、ParadeDB 压缩数据的能力是常规Postgres和Elasticsearch的5倍。
CREATE EXTENSION pg_analytics;-- 创建一个parquet表CREATE TABLE t (a int) USING parquet;INSERT INTO t VALUES (1), (2), (3);SELECT COUNT(*) FROM t;JSONB
PostgreSQL中支持JSON 列类型——JSONB。它允许JSON对象直接存储在表的行中。
CREATE TABLE cc_jsonb (id serial NOT NULL PRIMARY KEY,data jsonb);INSERT INTO cc_jsonb (data) VALUES ('{"name": "CC", "count": 12, "Date": "2024-07-09T12:14:01", "extra": "some text"}');INSERT INTO cc_jsonb (data) VALUES ('{"name": "DD", "count": 23, "Date": "2024-07-09T15:17:01"}');SELECT data->>'name', data->>'Date' FROM cc_jsonb WHERE (data->'count')::int > 12将JSON文档添加到PostgreSQL表仅比将文档添加到MongoDB集合稍微复杂一些。PostgreSQL需要使用CREATE TABLE语句来先创建文档的目标。
在查询JSON文档中的数据时,MongoDB提供了两种方法:用于简单查询的find 和aggregate用于更复杂情况的。
在PostgreSQL中,可以使用SQL语法来执行MongoDB中需要聚合框架的连接和分组操作,SQL语法更直观、更高效。
在PostgreSQL中,可以创建一个“GIN”(通用倒排索引)索引来索引JSONB对象中的所有属性,或者可以使用“表达式”索引来在特定JSONB元素上创建索引。
CREATE INDEX ccjsonb_path_ops_idx ON cc_jsonb USING GIN (data jsonb_path_ops);SELECT * FROM cc_jsonb WHERE data @> '{"name":"First"}'::jsonbSELECT * FROM cc_jsonb WHERE data @@ '$.count > 15'修改JSON文档时,MongoDB 提供了许多运算符,允许更新文档中的特定元素。 在PostgreSQL中,可以将值设置或附加到JSONB中的现有元素,但对于任何重要的事情,可能需要选择整个JSONB,在应用程序代码中对其进行操作,然后使用新对象更新JSONB列。
PostgreSQL拥有许多MongoDB中所没有的高级功能。SQL方言实际上比MongoDB支持的SQL领先数十年,事务支持明显更加成熟,并且对语句级并行性和高级索引选项的支持也很有吸引力。
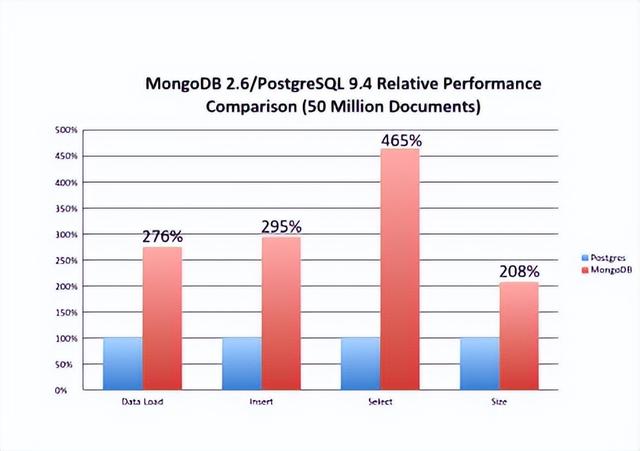
在性能方面持续有来和MongoDB的基准测试,基于一些案例PostgreSQL性能要高4倍以上。
 全文搜索
全文搜索在很多架构中,需要借助第三方的像Solr和ElasticSearch,不光架构复杂,还需要处理分词、索引和查询方面的事情。而使用Postgres中全文搜索可是自带的标配。许多项目都可以很好地使用 Postgres 全文搜索和其他内置扩展,例如三元组搜索(pg_trgm)。
假设有个电影表movies,其结构如下:
create table movies (id bigint primary key generated by default as identity,title text not null,original_title text not null,overview text not null,created_at timestamptz not null default now());给其增加一个字段用户存储全文关键字
add column fts_doc_engenerated always as to_tsvector ('english', title || ' ' || original_title || ' ' || overview) stored;然后再创建一个GIN索引加速搜索:
create index movies_fts_doc_en_idxon moviesusing gin (fts_doc_en);Postgres全文搜索支持更多的功能,例如对搜索结果进行排名的功能,限于篇幅此处只是简单地使用演示(更多可以以后专门文章介绍)
select * from movies where doc_en @@ websearch_to_tsquery('english', 'Avengers');总结限于篇幅,我们本文只能列举一些常见的且已经被广泛证明了Postgres可以做得很多好的功能,当然还有更多部分也值得探索,可以参考Postgres文档,以后有机会我们也可以分功能详细进行介绍。