前言,智算中心建设的大背景下,大家对“算力”的关注度空前高涨,对于“算力”而言专业性也非常强的,详细了解“算力”的各类知识点对于“智算领域”从业者而言很有必要,我举几个例子,你知道我国智算的规模和增速吗?通算&超算&智算三者有何区别?主流GPU卡H100有多个算力“数值”(FP16、FP32等)怎么理解?还有“稀疏矩阵算力”是啥意思?等等,今天我们结合大家比较关心的问题展开聊聊!

一、什么是算力
算力顾名思义是“计算能力”的缩写,指的是IT设备的计算能力,在以“智算中心”、 “数字经济”以及“东数西算”等国家政策导向驱动下, “算力”相关话题近两年热度非常高,大家对算力的关注度也持续攀升。
二、算力的规模
2023年中国智算市场规模5097亿元 , 随着各地智算产业的投入建设、 大模型在边缘侧及端侧的算力需求释放 , 2028年市场规模或将达到3.4万亿元 , 五年复合增长率达到46.3% ,在语言语音模态规模加成最为显著。

三、智算时代-算力需求的特点
智算特征一句话总结训练算力集中高密部署 ,推理算力贴近客户快速交互
训练:需要较高计算性能及海量数据 ,集群内网络时延性能要求高 , 需要集中高密部署;耗电量大 ,无需靠近最终用户,电力供应充足、 能源成本低的蒙贵甘宁等西部区域数据中心有一定优势,每个算力集群建议控制在50m以内,典型的训练GPU卡英伟达H100,单卡700W,每台H100 NVlink八卡机功率10.2kw;推理:需要低时延、 高弹性的计算,需要与模型实时交互,可部署在贴近用户的数据中心, 当前主要集中在训推一体的京津冀、 长三角、 大湾区等重点区域。目前典型推理GPU卡-英伟达RTX4090,单卡450W,每台4U八卡的服务器功率约4.5kw;四、算力的分类和单位

算力分类:从狭义的角度进行的统计,目前和信息技术有关的一切,其实都可以笼统称为算力领域,算力及服务的时代,除了狭义上的算力,还包括存储的存力、网络的传输能力、算法的能力等等。
算力单位:通常采用 FLOPS(Floating Point Operations Per Second)表示每秒钟能够完成的浮点运算或指令数,例如一台计算机每秒钟可以完成 10 亿次浮点运算,那么FLOPS值就是1GFLOPS(1 Giga FLOPS)。

除了FLOPS还有其他多种不同的衡量方法,归纳如下:
(1)MIPS(每秒钟执行的百万指令数);(2)DMIPS(Dhrystone每秒钟执行的百万指令数);(3)OPS(每秒操作次数,Operations Per Second);(4)Hash/s(每秒哈希运算次数,Hash Per Second)等。五、算力的统计标准
信通院发布了《中国算力发展智算白皮书》,作为权威机构的材料,对如何衡量“基础算力”、“智能算力”和“超算算力”给出了明确的解释,电子版的资料下载方式见文末。

结论归纳:与智算中心或者AI相关(默认是FP16)、超算HPC(默认是FP64)、部分情况为了便于统计,会统一换算为FP32(目前见到的不多),通常都会备注清楚。
六、算力精度-FP32、FP16等
标准的FP英文全称是Floating Point,是IEEE定义的标准浮点数类型。由符号位(sign)、指数位(exponent)和小数位(fraction)三部分组成。和FP类似的还有TF32(全称Tensor Float 32),是英伟达提出的特殊的数值类型,用于替换FP32,当然也有google提出的BF16(Brain Float 16),FP16也叫float16,全称是Half-precision floating-point(半精度浮点数),在计算机的角度是用16位二进制来表示的。


不同算力精度可执行的任务对比分析:

FP32和FP64都是二进制表示的,为了让“计算机”看懂,那么和十进制的数值如何转换呢?以FP32为例,我们将9.625这个十进制转换为FP32精度格式的二进制,具体计算方式如下:

七、算力的“计算”公式
1、CPU算力计算公式:
Flops=【CPU核数】*【单核主频】*【CPU单个周期浮点计算能力】
以6348 CPU为例,支持AVX512指令集,且FMA系数=2,

所以CPU每周期算力值为:

Intel 6348 CPU的双精、单精度算力的计算结果如下:

2、GPU算力计算公式:
GPU 峰值算力的测算公式为:
峰值计算能力= GPU Core 的运行频率*GPU SM 数量*单个SM一个时钟周期内特定数据类型的指令吞吐量*2

运行频率的单位为 GHz,一个时钟周期内特定数据类型的指令吞吐量单位为FLOPS/Cycle,其中不太好理解是后面2项;
①、单个SM一个时钟周期内特定数据类型的指令吞吐量,与英伟达每一代的GPU架构设计有关,与基于标准CUDA Core还是通过Tenser core加速也有关,在不同精度的表现也都不一样,具体如图(图片来自网络);
②、公式里面的“2”是因为Tensor Core融合了乘和加的指令,每次执行指令会计算一次乘法和一次加法,视作两次浮点运算所以乘以2;

以A100为例进行FP64和FP16 Tenser core的算力计算:
①、FP64 Tenser core的峰值算力为:
1.41x108x64x2≈19492GFlops,换算成T为19.5Tflops,与彩页里的官方公布的算力数值一致。
②、FP16 Tenser core的峰值算力:1.41x108x1024x2≈311869GFlops,换算成T为312TFlops,同样也和彩页里的数值一致。
③、稀疏算力对应的“周期内特定数据类型的指令吞吐量”是标准Tenser core下的2倍,所以算力也是2倍的关系。

八、GPU算力的综合指标
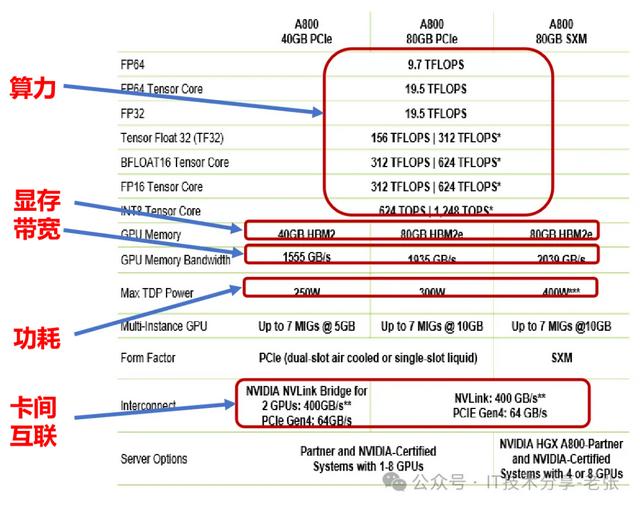
评价1张GPU卡算力如何,不能单看“算力”值,还有显存大小、显存类型、显存带宽、功耗、卡卡互联等都和“算力性能”密切相关。
芯片指标
定义分析
算力
GPU执行浮点运算的能力,通常以TFLOPS(每秒浮点操作次数)为单位衡量。高计算能力对科学计算、模拟和深度学习等计算密集型任务至关重要。它能加速模型训练、数据分析以及复杂模拟的处理速度。
显存
是GPU用于存储数据和纹理的专用内存,与系统内存(RAM)不同,显存具有更高的带宽和更快的访问速度。显存的大小和性能直接影响GPU处理大规模数据的能力。
显存带宽
作为GPU与显存之间数据传输的桥梁;显存带宽=显存位宽x显存频率
功耗
指单位时间内的能量消耗,反映消耗能量的速率,单位是瓦特(W)。
卡间互联
NVIDIA® NVLink™ 是世界首项高速 GPU 互联技术,与传统的 PCIe方案相比,能为多 GPU间提供更快速的互联方案。
九、“稀疏”算力怎么理解
自 Ampere 架构开始, 随着 A100 Tensor Core GPU 的推出,NVIDIA GPU 提供了可用于加速推理的细粒度结构化稀疏功能。
该功能可以加速推理。由稀疏 Tensor Core 提供,这些稀疏 Tensor Core 需要 2:4 的稀疏模式。也就是说,以 4 个相邻权重为一组,其中至少有 2 个权重必须为 0,即 50% 的稀疏率。这种稀疏模式可实现高效的内存访问能力,有效的模型推理加速,并可轻松恢复模型精度。渐进式稀疏训练方法。腾讯机器学习平台部门 (MLPD) 利用了渐进式训练方法,简化了稀疏模型训练并实现了更高的模型精度。借助稀疏功能和量化技术,他们在腾讯的离线服务中实现了 1.3 倍~1.8 倍的加速。(网上数据)
十、GPU卡不同精度算力数值怎么理解
目前智算中心建设中,使用最多、讨论最多的依然是H100\H800型号的GPU和NvLink整机,但是还是有很多同学对H100 GPU卡的参数不清楚,智算中心以AI算力为主,该用哪个数值呢?和FP16相关的竟然有三个,我们设计方案时会采用FP16 Tenser加速的989TFPOPS,约1个P,个人简单总结如下:

来源:技术分享老张