如下图,计算每门课的平均成绩,即计算每列数据的均值,结果保留两位小数,显示在导入数据的下面一行。输出修改后的表数据,并在同目录下另存为“修改后的考试成绩”。添加代码注释。
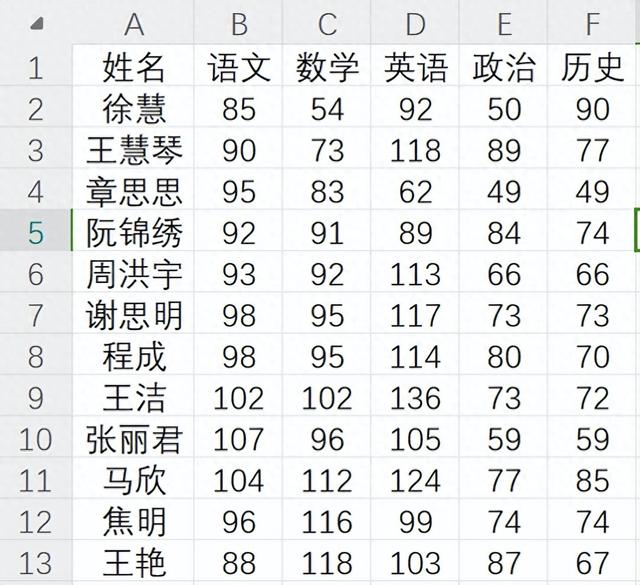
图1.原始数据表
文心一言提示词打开百度“文心一言”,输入提示词:“你是pandas专家,文件路径为:D:/Samples/考试成绩.xlsx。该Excel文件的第一个工作表中A-F列为给定数据。用pandas导入Excel文件的数据,将“姓名”列作为索引列,引擎为"openpyxl"。使用导入的数据,计算每门课的平均成绩,即计算每列数据的均值,结果保留两位小数,显示在导入数据的下面一行。输出修改后的表数据,并在同目录下另存为“修改后的考试成绩”。添加代码注释。”
显示结果如下:
作为pandas专家,我会按照您的要求编写代码,并添加必要的注释来解释每一步的操作。以下是完成您所描述任务的Python代码:
import pandas as pd# 定义文件路径file_path = 'D:/Samples/考试成绩.xlsx'# 使用pandas读取Excel文件,将“姓名”列设置为索引列,并指定引擎为"openpyxl"# 注意:这里假设“姓名”列位于A列,即第一列df = pd.read_excel(file_path, index_col='姓名', engine='openpyxl')# 计算每门课的平均成绩(即每列数据的均值),结果保留两位小数average_scores = df.mean(axis=0).round(2)# 将计算得到的平均成绩作为新行添加到DataFrame的底部,这里使用reindex重置索引,# 并填充NaN值(如果需要的话),以确保新的平均成绩行在正确的位置df_with_averages = df.reindex(df.index.tolist() + ['平均成绩']).fillna(average_scores)# 输出修改后的表数据print(df_with_averages)# 另存为新的Excel文件,在同一目录下保存为“修改后的考试成绩.xlsx”output_file_path = 'D:/Samples/修改后的考试成绩.xlsx'df_with_averages.to_excel(output_file_path, engine='openpyxl')代码解释:
导入pandas库并使用pd作为别名。定义一个字符串变量file_path,存储Excel文件的路径。使用pd.read_excel函数读取Excel文件,并将“姓名”列设置为索引列。index_col='姓名'指定了索引列的名称,engine='openpyxl'指定了读取Excel文件时使用的引擎。使用df.mean(axis=0)计算DataFrame中每列的平均值,axis=0表示沿着行的方向(即列的平均值)。然后,使用round(2)方法将结果保留到两位小数。为了将平均成绩添加到DataFrame的底部,我们使用reindex方法重置索引,并添加一个新的索引标签“平均成绩”。fillna(average_scores)用于填充新添加的“平均成绩”行中的NaN值,用计算得到的平均成绩替换。使用print函数输出修改后的DataFrame,以检查数据。最后,使用to_excel方法将修改后的DataFrame保存为新的Excel文件,文件名为“修改后的考试成绩.xlsx”,保存在与原始文件相同的目录下。请注意,这段代码假设“姓名”列位于Excel文件的A列,并且没有其他列标题或额外的数据需要处理。如果实际情况有所不同,您可能需要根据实际的Excel文件结构对代码进行适当调整。
Python编辑器运行
图2.Python运行结果

图3.新生成的数据文件