有一定数据分析或数据仓库经验的同学对这一模型早已耳熟能详。但我还想多说两句,星型数据模型就是为分析而准备的,因维度表围绕事实表构成的模型很像一颗星星而得名。(如下图)当然他还有一个孪生兄弟叫雪花模型(Snowflake), 雪花模型的唯一区别是再有层次机构数据时候,允许维度表组织成层次结构的一对多关系。而在星型模型中你需要将这个层次结构扁平化(后面讲到具体方法)。两种模型各有优劣,星型模型利于编写查询和统计函数,雪花模型在维度表很大的情况下可以节约空间,但编写查询会更复杂。
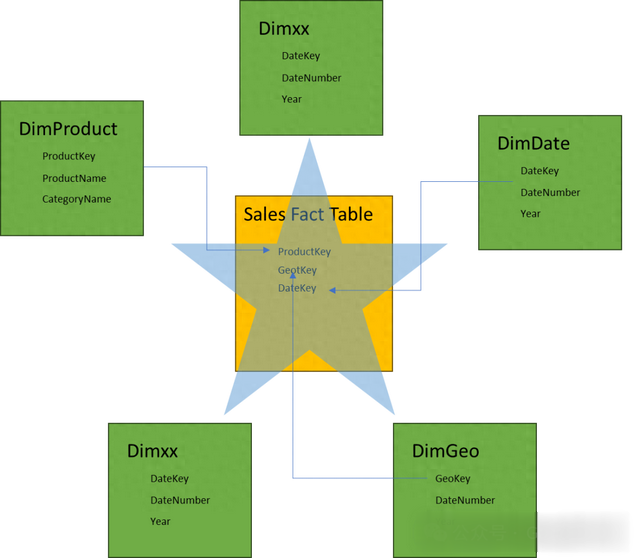
维度表就是用于分析数据的属性,例如产品,商店,销售员,销售时间等。这些可以用于分析的属性我们就可以把他称之为维度。
什么是事实表?(Fact)事实表顾名思义就是事实发生的事情的记录,例如你去超市购买了东西,打印出来的小票上面就是你购物的事实记录,反映在数据记录上就是一条订单信息,订单上的每一项商品所形成的记录我们称之为一条事实记录。
例如下图小票。这个顾客在2020-1-7日购买了可口可乐2.3L * 3瓶,总价17.70员,收银员为038。这样一条记录在数据库中我们就成为一条事实。

简单来讲就是这一条事实记录的无二义性的表述。
用文字表述的话就是:顾客abc,在,2020-1-7日,购买了,可口可乐2.3L,3瓶,共17.7元。
用表格表述的话就是:

我们把顾客Id,日期Id,产品Id唯一能组成一条记录的情况称之为粒度。粒度的粗细由维度属性的多少决定,粒度越细能够分析的情形就越多。例如,上表中我们可以把销售的商店信息增加进去,那么粒度就变细了。
如何生成星型模型?生成星型模型的过程一般被称为ETL(Extract-Transform-Load),既提取,转换,加载。
生成星型模型的第一步就要确认粒度。粒度确认好了,就可以从事务系统中导出维度表了。维度表制作好了,就可以使用联合查询来产生所需的事实表。(通常是使用SQL的联合查询)
维度表存在父子或层级结构怎么办?这是星型模型通常遇到的障碍之一,因为雪花模型直接沿用层次机构表就好了。
什么是层次结构?例如员工维度表中员工和经理的关系,产品维度表中产品和产品类型和产品子类型的关系,服务类型和服务子类型的关系,等等诸如此类。
在星型模型中通常需要将层级关系扁平化,我们举个例子,假设我销售一种产品,这种产品相关的类型和子类型。
我有一张产品类型表(ProductCategory)(类型Id,类型名称)
一张产品子类型表(ProductSubCategory)(子类型Id,类型Id,子类型名称)
一张产品表(Product)(产品名称,子类型Id)
扁平化的过程就是将他们进行联合查询,将层级结构的名称提取到最外层结构。
create view DimProduct( select p.类型名称,c.类型名称,s.子类型名称 from Product as p left join ProductSubCategory as s on p.子类型ID = s.子类型ID left join ProductCategory as c on c.类型ID = s.类型ID)完成了扁平化,在数据分析中就很容易通过类型,子类型进行筛选统计了。(扁平化最主要的目的就是使查询统计变得简单)
维度表中的自然键和代理键是什么意思及作用?自然键:就是事务系统中业务表的主键,例如在业务系统中有一个产品表Product具有一个唯一标识product_Id(可能是自增的),这个字段也需要放在维度表中,我们称之为自然键,其作用是跟踪业务系统中每一条记录,以便于更新维度表。
代理键:就是维度表中的主键(通常是自增的),这个主键唯一决定了维度表中的一条记录,例如维度表DimProduct中有ProductKey(代理键),ProductAlternateKey(自然键)。代理键主要用于与事实表进行关联。在事实表的联合查询中,通过自然键连接到维度表来获得这个代理键用于事实表中的维度键(维度ID)。这样就能最终产生满足要求的星型模型了。
维度表的挑战维度表主要包括两种常用的类型,既类型1和类型2. 类型1一般是业务系统中发生了更新那么在维度表中相对应的维度进行更新(替换)。
类型2表示的是值发生了变化需要保存历史。例如,A业务线的经理由Tony变为Aaron,那么我需要保留Tony并标记为历史,然后新增Aaron为其经理。那么维度表中A业务线的经理就有两条,一条是之前的,一条是当前的。这是常见的业务分析需要,例如需要对比A业务线在不同的经理上的成本和效益。
事实表的挑战事实表往往很大从数万,到数百万上千万,以至上亿至更多。加载数据表通常由两种方案,当数据量较少时候通常小于百万,可以采用全量加载的方式(一口气删除后进行加载,可以免去分辨哪些是新增,更新或删除的记录)。当数据量超过百万级,全量加载可能慢的不可能完成,所以需要采用增量加载。增量加载的完美方案往往需要依赖数据源的CDC(数据变更捕获)特性,如果没有这个特性,只能利用时间戳,或者最大ID的方式进行跟踪。(这种方案依然有不准确的隐患)
什么是数据清洗?就是将业务系统中的非标准数据或业务概念不一致的数据规范为分析需要的数据,同时去除不必要的数据,修正错误数据等的过程。
数据清洗往大了说是数据治理。
总结(良好实践)星型模型是最利于数据分析的模型。(弊端是维度表太大的例如数百万行可能会存在性能问题,但我至今没见过如此大的维度表)
需要将具有层次结构的维度表扁平化。
数据超过百万级时候,考虑对事实表进行增量加载。
数据清洗是个很大的话题。
总之,一个企业如果想充分利用数据资产并为决策提供帮助的话,必须严肃认真的对待数据分析模型,好的数据模型即为星型模型。花费一些人力和财力谨慎构建数据模型将为企业充分利用数据奠定强大的基础,而且会成为企业宝贵的数字财富。笔者这么多年从业经验,真正认识到并严肃对待数据建模及数据仓库的管理者少之又少,往往是IT根据业务需要,做几个报表,然后开发员人走茶凉,留下一堆不知道如何修改的报表。
数据建模及数据准备通常需要一个团队来进行,再节约成本也需要一个单独的角色来进行。并且进行数据准备的团队和个人,一定要为其提供数据保存的地方通常是成熟的数据仓库技术。
除非你的的业务需求很简单,你主动放弃建立企业的数字资产库,那么你可以随意。否则花费一定的人力财力建立企业的数据资产是非常值得一件事情。了解星型模型及如何构建他的知识,你的数据资产的价值就已经有了50%。