本文旨在介绍 XJDR 在一个名为 Entropix 的新项目中开发的推理新方法。
Entropix 试图通过在不确定时更聪明的采样方法,来提升模型的推理能力。
需要注意的是,目前 Entropix 尚未进行大规模评估,因此在实际效果上还不明确。但它确实引入了一些具有前景的技术和思维模型来改进推理。
一瞥不确定性采样是指在可能的词元分布(即 logits)中选择下一个词元的过程。通过观察这个分布,可以判断模型对预测结果的信心程度。
以下是模型对下一个词元的高置信度预测示例:
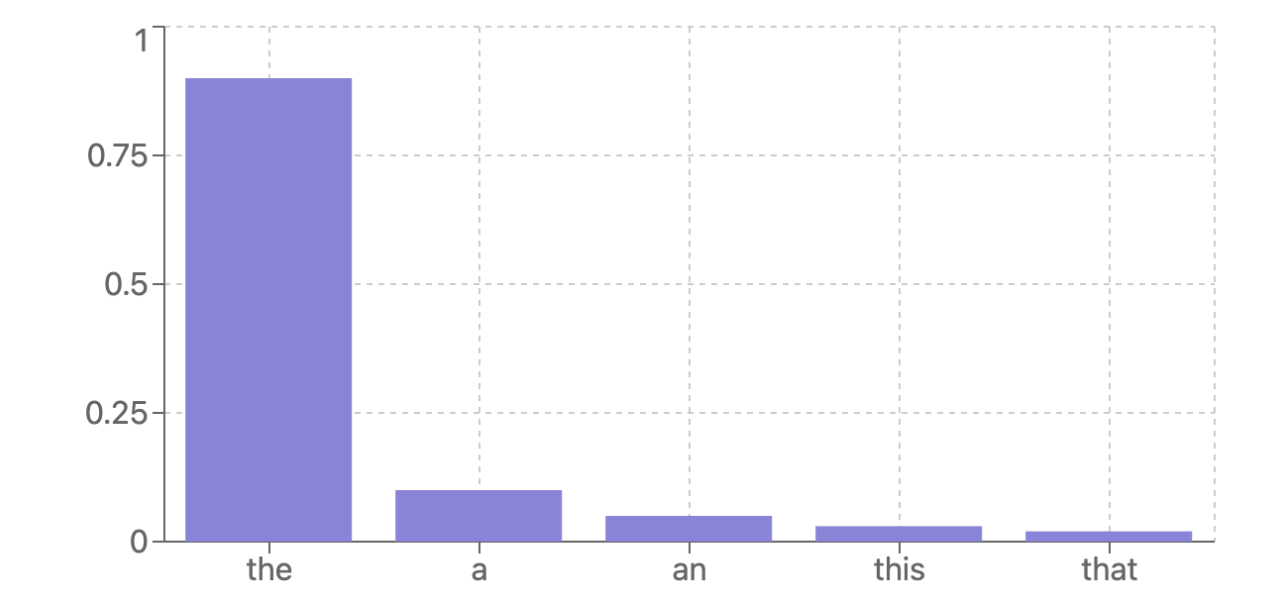
但在现实中,模型并不总是对自己的预测充满信心。你经常会遇到这样的情况:
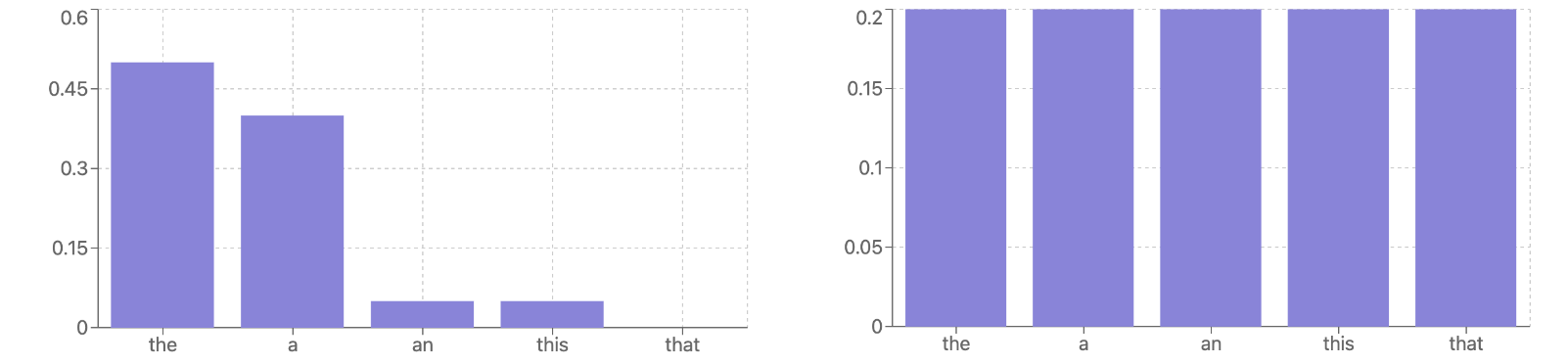
在这些情况下,模型表现出不确定性。
Entropix 提供了一种使用自适应采样的方法,帮助模型在不确定时做出更好的决策。
不确定性意味着什么,它是否重要?logits 中的不确定性可能由许多不同的原因引起,且并不总是有害的。
原因可能包括:
词元为同义词或等价(如“good”与“great”)
存在分支路径(如 AI 可以用 Java 或 C 语言编写程序)
AI 确实不确定如何应对(它处于“分布之外”的情况,即在训练数据中未见过)
Entropix 建议,根据不确定性的不同,应使用_不同的方法_选择下一个词元。
那该如何实现呢?首先,我们需要衡量不确定性。
熵与变熵Entropix 使用的核心工具是两个衡量不确定性的指标:熵和变熵。
熵衡量预测的 logits 之间的差异程度,即对最可能结果的确定性。在低熵情况下,我们对某些 logits 比较确定;在高熵情况下,logits 的分布更为均匀,我们的确定性则更低。
变熵是一种不同的熵指标,用于反映不确定性的“形状”。高变熵表明某些值显著不同于其他值。
▼ 数学解释

结合这两个指标,我们得到 4 种可能的状态:
低熵、低变熵:一个非常集中的分布(唯一高度可能的结果)。
低熵、高变熵:存在几个分散的高峰的分布。
高熵、低变熵:一个均匀或近乎均匀的分布。
高熵、高变熵:分散且不均匀的分布。
基于熵与变熵的自适应采样现在我们有了这些不确定性指标,可以根据具体情况执行不同类型的采样。
低熵、低变熵
这种情况通常是理想状态。模型不仅对第一个选择很有把握,而且对后续可能的选择也有信心。通常,这意味着列表已按顺序排列。
在这种情况下,自适应采样建议使用标准的最大值采样,即选择概率最高的词元。
低熵、高变熵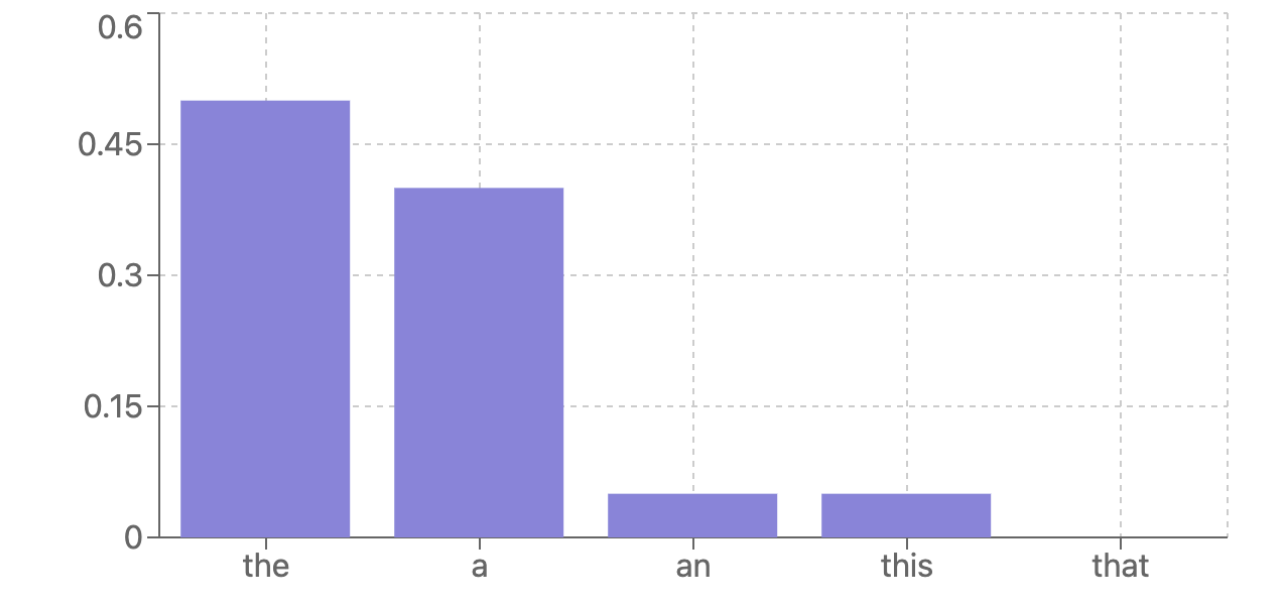
在这种情况下,模型对几个选项的预测概率都很高。
这种情况比较棘手,可能代表一个全新的输出分支,或者仅仅是几个同义词的选择。
在这种情况下,我们可以选择“分支”,即同时预测两个 logits,观察它们的后续路径并在某个节点后比较结果。实现分支的方法有很多,可以另文详述。
根据分支的结果,我们可以采取不同的操作。如果两个分支的置信度相近(通过它们的熵和变熵来衡量),但内容不同,我们可以将其转化为一个问题询问用户。
高熵、低变熵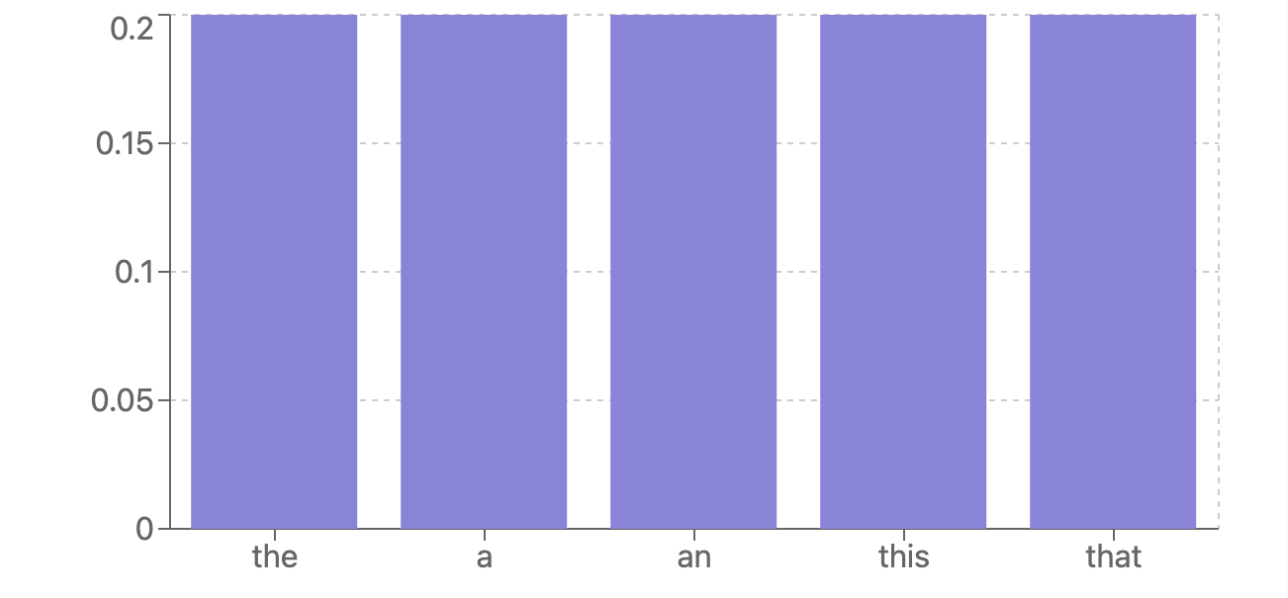
这种状态表示模型可能的低置信度。它可能遇到了完全不认识的内容,或所有选项之间可能是可互换的。
此时的最佳做法是帮助模型进入更高置信度的状态。Entropix 建议在此使用**“思考”词元**作为下一个词元,例如“Wait..”。
思考词元是我们插入到输出中的一个词元,以使模型意识到在给出答案之前需要花更多计算时间来思考。
例如,如果模型预测 “The capital of Germany is Paris” 但不确定,可以插入一个思考词元,预测为 “The capital of Germany is Paris… Wait, no, it’s actually Berlin”。
高熵、高变熵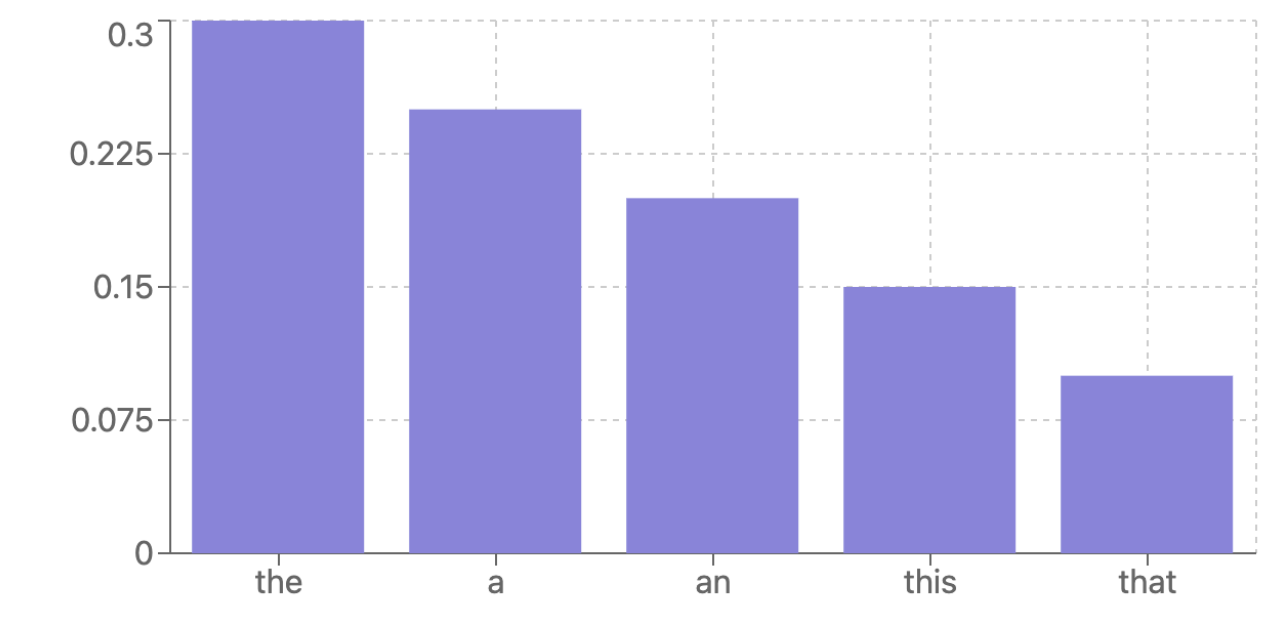
此时模型没有明显的偏好,但对某些输出比其他更确定。这种情况很难处理。可以理解为任意选项可能都是合理选择(例如它们互为同义词),因此可以随机选择一个(即增加采样温度)。
我们还可以像之前一样进行分支或插入思考词元。
分支与思考词元分支和思考词元是两种在不确定状态下进行更多计算的方法。
分支预测是指跟踪几个 logits,看看它们会引导出什么样的其他词元。这种方法通常称为 MCTS(蒙特卡罗树搜索),常见于大型语言模型中,但效果一般。分支的一个权衡是,它需要使用推理计算,但各分支的计算无法互相共享。
思考词元是在不确定状态下进行更多计算的一种方法,不需要牺牲计算资源去探索可能被舍弃的分支。插入“Wait…”会让 AI 意识到它可能犯了错误。
分支与思考词元的选择仍然是一个开放的研究课题,值得进一步探讨。
注意力熵值得注意的是,我们可以考虑其他的熵指标。Entropix 仅稍微使用它们来调整温度,但它们可能是有用的工具。
注意力熵 - 表示注意力头在特定词元上集中程度,与是否关注大量上下文词元相比。
注意力一致性 - 表示注意力头在关注同一词元的程度,与关注不同词元的情况相比。
如果注意力头的熵低且一致性高,这可以成为一个信号,使我们有信心采样概率最高的词元。低一致性可能表明不同的注意力头正在贡献不同的预测,此时可能值得进行分支。
这有用吗?Entropix 中的这些见解在很多方面都相对易于理解,也并非完全新颖,这让许多人感到意外。
即使评估未显示出显著的改进,推理时的技术仍然易于实验化,并可能成为开源开发者在没有巨额预算下提升推理效果的有前景方向。