自动编码器模型是从大量数据中训练基础模型的基础。 我们谈论的是数百亿个训练样本,就像互联网的很大一部分一样。
有了这么多数据,雇用人类来标记所有这些数据以告诉模型其目标是什么在经济上是不可行的。 因此,人们想出了许多聪明的想法来从训练示例本身[自动]导出训练目标。
最直接的想法是仅使用训练数据本身作为目标。 这个实践练习展示了这个想法。
然后,人们尝试隐藏训练数据的某些部分,并使用那些缺失的部分作为目标。 这称为掩蔽,这就是当今LLM的训练方式。
然后,人们尝试将文本和图像配对并互相使用作为目标。 这称为“对比”学习。 这是 OpenAI 著名的 CLIP 模型中的 C(对比),它是所有多模态基础模型的基础。
让我们从基础的——自动编码器开始。
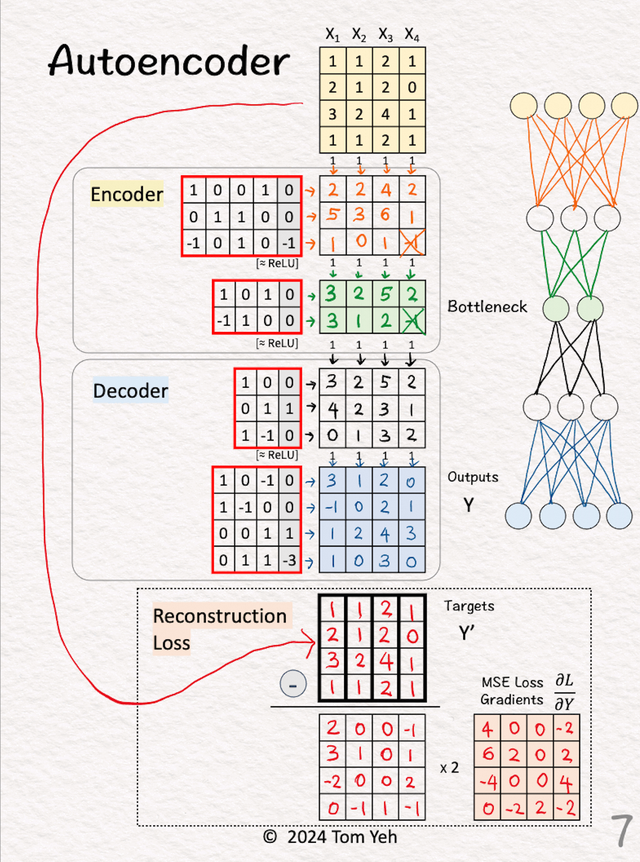
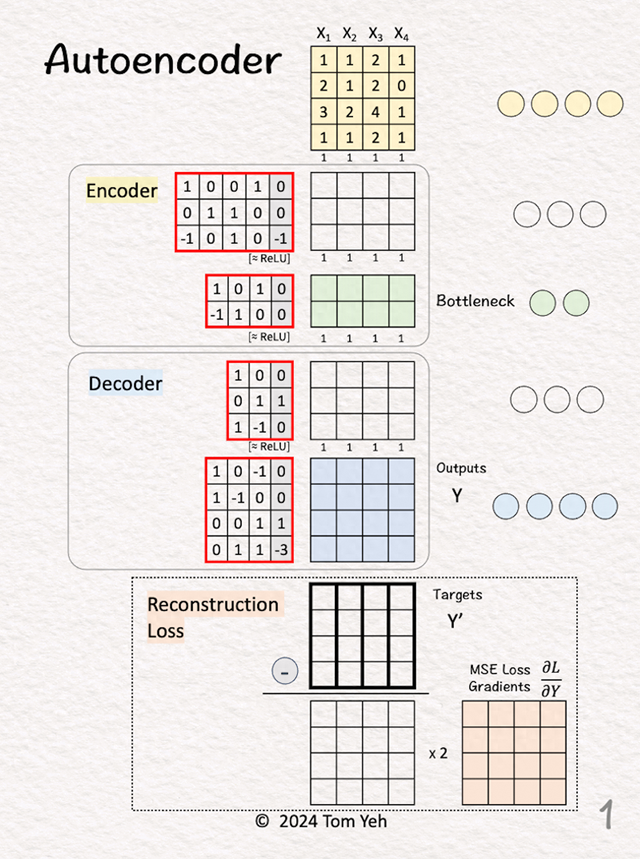
1.输入输入是4个样本的,4维的
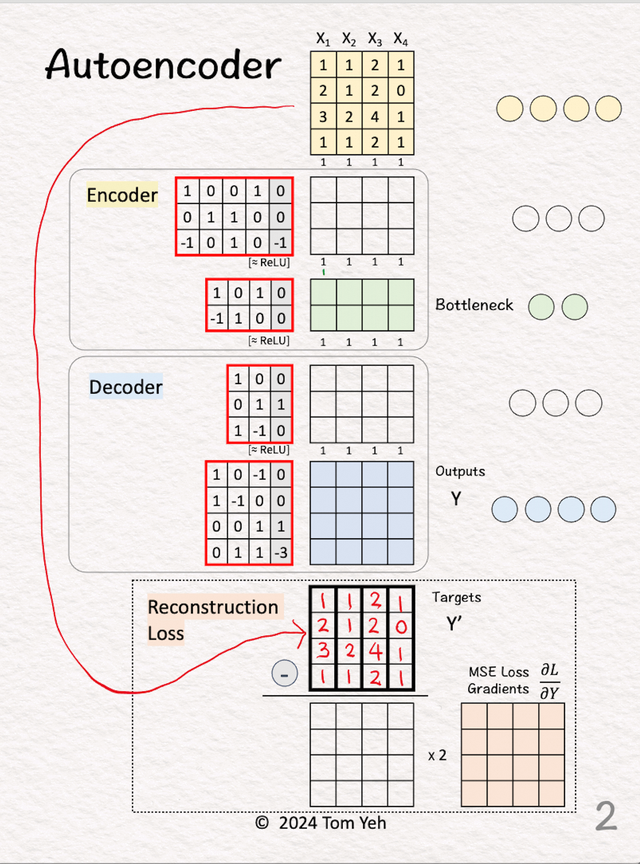
 2.得到训练的target
2.得到训练的target直接将复制一份得到,这个就是我们的训练目的,我们就是要不断的训练Encoder和Decoder部分,让其可以从 变换到(X自身)
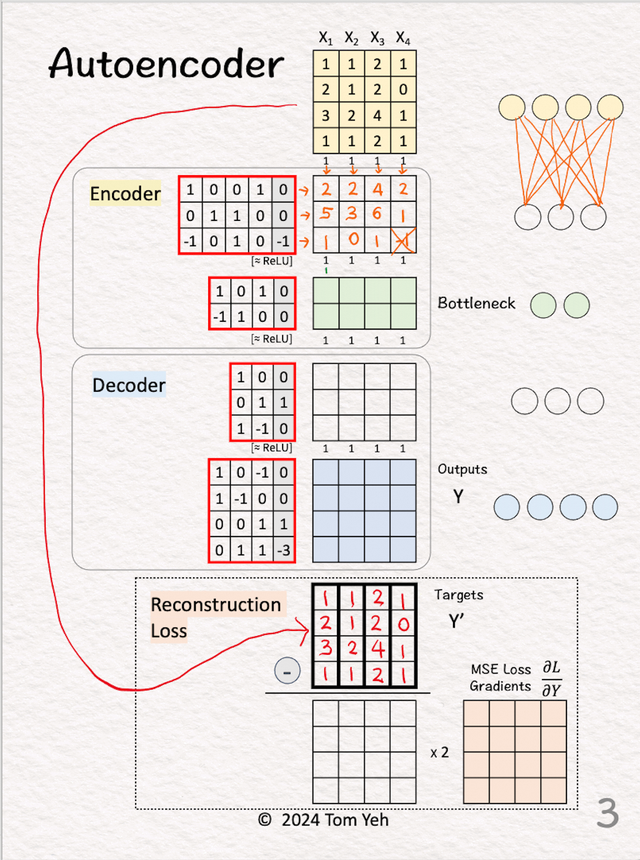
 3.编码器的第一层
3.编码器的第一层将输入与权重和偏差相乘。应用 ReLU。
 4.编码器的第二层
4.编码器的第二层将特征与权重和偏差相乘。应用 ReLU。注意这层的输出已经比输入维度少了(4维变成了2维)
 5.解码器第一层
5.解码器第一层通常解码器和编码器是一样对应的(矩阵的维度是转置的)。
将特征与权重和偏差相乘。应用 ReLU。
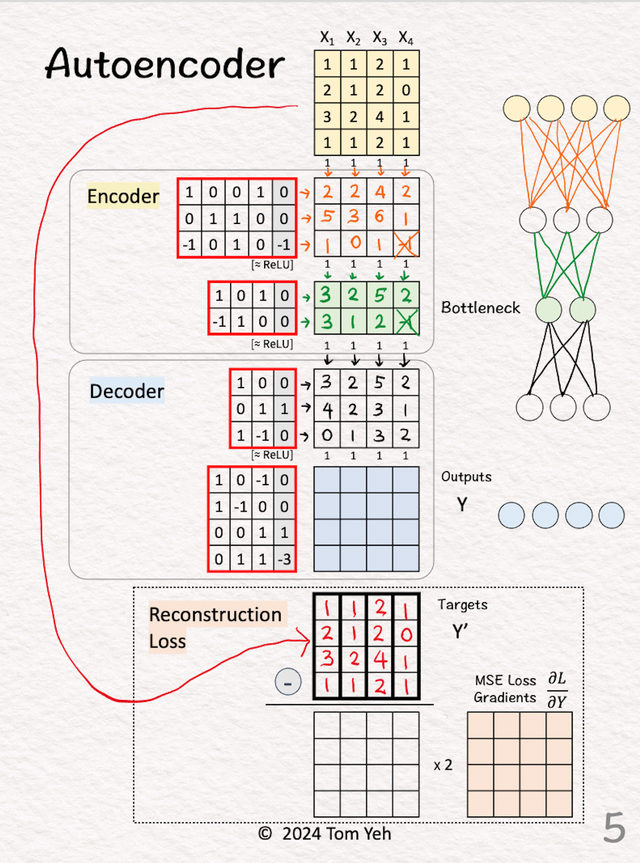 6.解码器的第二层
6.解码器的第二层将特征与权重和偏差相乘。输出 解码器根据简化的二维表示重建X的一轮尝试。
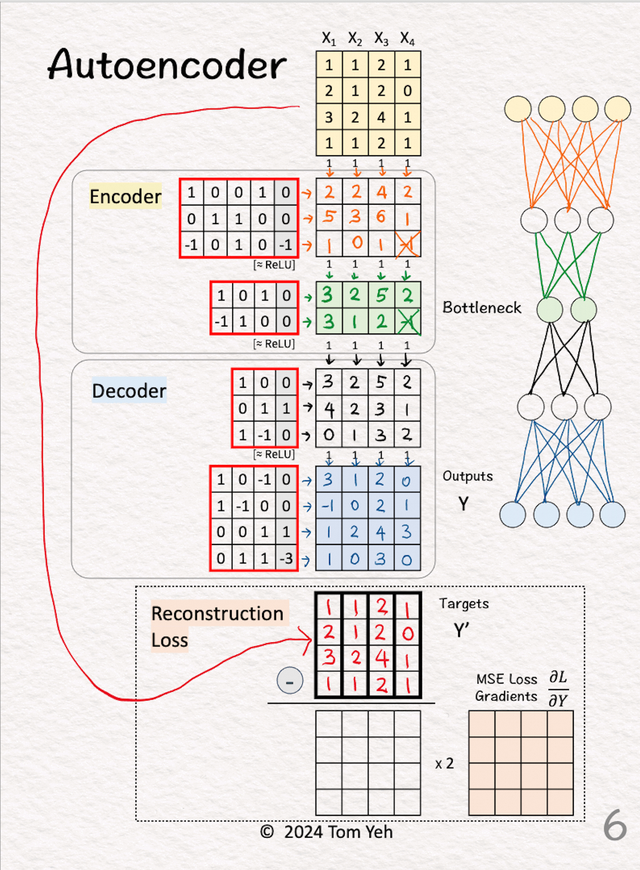 7.损失梯度和反向传播
7.损失梯度和反向传播计算输出 (Y) 和目标 (Y') 之间的均方误差 (MSE) 损失的梯度。公式为 2 * (Y - Y')。首先我们计算输出 (Y) - 目标 (Y')。其次,我们将每个元素乘以 2。这些梯度启动反向传播过程以更新权重和偏差。
反向传播过程会更新Encoder和Decoder中的红色框中的数字。