
作者:陈璐,霍智鑫,张杰
01
引言
Cloud Native
随着万物互联时代的到来,智能终端设备的数量急剧增加,伴随而来的是海量数据的生产和处理需求。在这样的背景下,边缘计算的兴起也为云计算创造了更多可能性。将云上丰富的能力延伸到边缘,云与边紧密结合,通过中心云对分散的边缘设备进行统一交付、运维、管控,是云计算发展的重要趋势。
与此同时,大模型引领的新一轮 AI 热潮正迅速蔓延到边缘领域。更强大的边缘算力,更轻量的模型,更丰富的落地场景,AI 任务作为一种新型的工作负载已经被纳入到了边缘计算的范畴中。然而边缘计算与 AI 的结合既提升了边缘侧的智能化水平,也极大地增加了在边缘环境中管理运维计算资源的复杂性。
为了帮助用户打造云边协同一体的 AI 平台,ACK Edge 与云原生AI套件的联合解决方案应运而生。通过 ACK Edge 将云上完整的 AI 平台能力下沉至边缘。用户不仅可以统一管理分散在多个地域的异构资源,在边缘侧进行实时推理,还能利用云端资源进行模型的训练和优化,同时云边协同的能力使得模型与数据在云边之间无缝互通,从而大大提升了整体的 AI 工程效率。
02
背景
Cloud Native
2.1 ACK Edge:边缘计算的坚固底座
ACK Edge[1]是一款提供标准 Kubernetes 集群云端托管,支持边缘计算资源、业务快速接入、统一管理、统一运维的云原生应用平台,能够帮助用户快速实现云边一体协同。面向云端,通过 ACK Edge,用户可以直接享受到阿里云丰富的云上生态能力,如网络、存储、弹性、安全、监控、日志等。面向边缘,ACK Edge 针对边缘场景面对的复杂的环境,提供了边缘节点自治、跨网域容器网络方案、多地域工作负载和服务管理等一系列的支持来解决边缘场景的痛点问题。
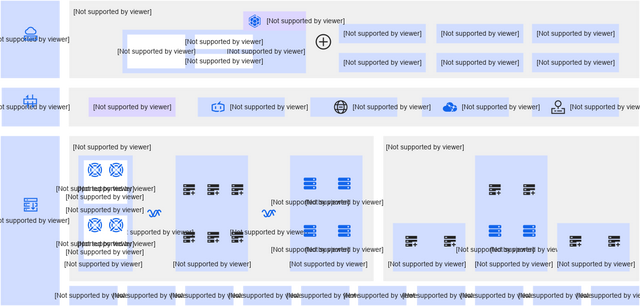
2.2 云原生 AI 套件:赋能边缘的智能引擎
云原生 AI 套件[2]是 ACK 提供的全栈云原生 AI 技术和产品方案。使用云原生 AI 套件,用户可以充分利用云原生架构和技术,在 Kubernetes 容器平台上快速定制化构建 AI 生产系统,并为 AI/ML 应用和系统提供全栈优化。向下封装对各类异构资源的统一管理,向上提供标准 Kubernetes 集群环境和 API,以运行各核心组件,实现资源运维管理、AI 任务调度和弹性伸缩、数据访问加速、工作流编排、大数据服务集成、AI 作业生命周期管理、AI 制品管理、统一运维等服务;再向上针对 AI 生产流程中的主要环节,支持AI数据集管理,AI 模型开发、训练、评测,以及模型推理服务等。

03
AI 套件 on ACK Edge 的使用场景
Cloud Native
ACK Edge 整合了云上云下的算力资源,统一管理于一个 K8s 集群。在此基础上,云原生 AI 套件面向 AI 平台的开发运维团队,助力其高效、低成本地构建 AI 基础设施。而且 AI 套件将功能封装成命令行和控制台工具,直接供上层的数据科学家和算法工程师使用。
以下是 AI 套件在 Edge 集群中使用场景的简要概述[3]。
3.1 多地域异构资源的统一管理
通过 ACK Edge,用户可以在一个 K8s 集群中统一管理分散的线下计算资源。Edge支持丰富的边缘侧资源类型接入,覆盖了主流的 GPU,CPU,OS 型号。边缘节点通常通过公网或者专线的方式接入到云上集群中。考虑到在边缘不稳定的网络环境,Edge 提供了边缘节点自治的能力。即使在网络断联的情况下,它也能保障离线边缘节点上业务的持续运行,并且允许运维人员在断网时介入在不依赖云端控制面的情况下执行一系列紧急运维动作。另外,为了解决云边协同架构下云边通信带来的的流量成本问题,Edge 支持节点/节点池级别的流量复用,与原生 Kubernetes 集群相比减少了 50% 以上的云边管控流量。
当使用一个 ACK Edge 集群来管理多个地域的节点时,不同地域的节点通常处于不同的网络平面,互相之间网络不连通。针对这类场景,Edge 提供了一套兼容 CNI 的跨域容器网络通信方案 raven,支持跨地域的容器网络通信。如果需要管理多个地域的应用,Edge 还支持多地域应用分发,多地域服务暴露的能力,大大减轻了多地域场景的管理负担。

同时,结合 AI 套件提供的GPU 共享调度、GPU/CPU 拓补感知调度能力,Edge 管理异构资源的能力得到了进一步的增强。比如,原生 Kubernetes 仅支持以 GPU 整卡粒度为单位调度,任务容器会独占 GPU 卡。如果任务模型比较小(计算量、显存用量),就会造成 GPU 卡资源空闲浪费。GPU 共享调度能力,可以按模型的 GPU 算力和显存需求量,将一块 GPU 卡分配给多个任务容器共享使用,大大提升了 GPU 资源的利用效率。
另外,AI 套件也提供了丰富的节点视角和应用视角的 GPU 监控指标,帮助用户了解云上/云下整个集群的 GPU 资源使用情况、健康状态、工作负载性能等,从而实现对异常问题的快速诊断、优化 GPU 资源的分配、提升资源利用率等。

3.2 混合云 AI 任务调度与弹性
针对 AI 分布式训练等典型批量任务类型,ACK Edge 的调度器扩展了 Kubernetes 原生调度框架,支持实现多种典型批量调度策略,包括 Gang Scheduling(Coscheduling)、FIFO Scheduling、Capacity Scheduling、Fair sharing、Binpack/Spread 等。除了以 Pod 为单位的任务类型的作业调度,AI 套件还支持任务队列维度的工作流编排和管理能力。

在资源分散分布的混合云环境中,ACK Edge 调度器提供的自定义资源优先级调度(resource policy)能力,支持在线上线下混合部署业务时优先使用线下 IDC 资源,IDC 资源不够时再使用云上资源,在保障业务高可用的同时极大提升了线下资源的使用效率,发挥出混合云的优势。同时,该能力还可以与弹性节点池的能力协同使用,在弹性训练和弹性推理等业务场景中,实现动态扩缩容。
3.3 AI 数据编排与加速
作为数据密集型应用的代表,AI 应用的工作流程通常会涉及大量的数据生产和消费。尤其是在计算和存储分离的混合云环境中,数据的访问延迟和远程拉取数据产生的网络带宽往往会成为 AI 应用的性能瓶颈。AI 套件提供的数据编排和加速系统 Fluid,通过数据亲和性调度和分布式缓存引擎加速,实现数据和计算之间的融合,从而加速计算对数据的访问。具体而言,Fluid 既可以用来加速云上访问 IDC 中自建存储系统,为云上的 AI 模型训练增效;也可以帮助边缘节点拉取存储在云上 OSS 中机器学习模型,为边缘的 AI 推理加速。

另外,AI 应用通常会把依赖库与框架一起打包到容器镜像中,镜像体积动辄数十 GB 大小,在大规模批量部署时,AI 镜像的分发效率也成为 AI 业务的一大痛点。借助于阿里云容器镜像服务 ACR 提供的镜像按需加载与 P2P 加速分发的能力,能够减少 95% 以上的镜像下载时间,大幅提高应用部署速度。
3.4 AI 作业生命周期管理
构建于 ACK Edge 之上,AI 套件的组件提供了一套简单易用的基于 Kubernetes 标准接口(CRD)和 API,以供 AI 平台的开发和运维人员使用。同时,考虑到日常使用 AI 平台的数据科学家和算法工程师可能并不熟悉 Kubernetes 的语法和操作,AI 套件面向 AI 作业生命周期,还提供了一整套完整的命令行工具 Arena、SDK 以及开发/运维 Web 控制台,屏蔽底层基础设施的复杂性,降低用户的使用负担,实现真正的开箱即用。


04
总结
Cloud Native
值得一提的是,无论是 ACK Edge 还是云原生 AI 套件,两个产品都与开源社区建立了广泛且深入的联系,阿里云容器服务团队深度参与并共建了包括 Kubeflow, OpenYurt,Fluid,Arena 在内的等诸多知名开源项目。ACK Edge 与云原生 AI 套件的联合实践,为边缘场景注入了强大的 AI 任务处理能力,通过高度集成与优化,实现了从基础设施到应用层的全栈智能化升级。这一组合方案不仅解决了混合云场景下分散的异构资源管理和高效利用的问题,而且提供了一整套开放且完整的 AI 平台解决方案,引领了边缘 AI 的新范式。
相关链接:
[1] ACK Edge 集群 Pro 版介绍
https://help.aliyun.com/zh/ack/ack-edge/user-guide/introduction-to-professional-edge-kubernetes-clusters
[2] 云原生 AI 套件概述核心功能
https://help.aliyun.com/zh/ack/cloud-native-ai-suite/product-overview/cloud-native-ai-suite-overview
[3] 在 Edge 集群使用 AI 套件
https://help.aliyun.com/zh/ack/ack-edge/user-guide/cloud-native-ai-suite-overview