本月的更新,模型视图中新增了一个“值筛选行为”的功能,这篇文章就带来理解一下它的作用。在介绍值筛选行为之前,首先来了解一下DAX运行的一个底层机制:Auto-Exist。
理解Auto-Exist
DAX 底层运行有一种自动筛选机制,被称为Auto-Exist,旨在减少无效组合的计算负担。当同一表中的多个列被用于筛选时,DAX 会自动排除不存在的值的组合,来达到优化性能的效果。
以下面这个简单的数据来说明,这是同一个表的三列数据:

如果要查看每年每个产品的客户数量,可以这三列直接拉个如下的矩阵,年度放入【行】、产品放入【列】、客户放入【值】(聚合方式选择计数):

假如想计算所有产品的客户数,写个度量值如下:
客户数 全部产品 =
CALCULATE(COUNTROWS('表'),ALL('表'[产品]))
并用年度列和产品列添加两个切片器,如果选择2023年和2024年,计算结果是6,这个结果是正常的,从上面的矩阵也可以看出来(2023年 4+2024年2)。

在此基础上,产品切片器选择B,结果也还是6:

这个结果也是正常的,毕竟在度量值中,已经把产品的筛选通过ALL函数清除了。
如果将产品切片器从B切换到C ,理论上来说也不会受影响,结果还应该是6,但是事实上结果却变成了4:

这是怎么回事呢?
这就是Auto-exist在起作用,在这个例子中,我们用年度和产品两个字段来筛选数据,两个筛选器会自动合并为一个筛选器,并剔除无效的组合,2024年是没有C产品的,就是无效组合,所以它自动去除了,计算结果只有2023年的客户数量4。
按照正常的逻辑,在度量值中已经将产品列的筛选清除了,该字段不应该对结果产生影响,如何让它保持这个逻辑而不启用Auto-Exist机制呢?
这就是本月更新的值筛选行为要解决的问题。
值筛选行为
为了解决Auto-Exist带来的潜在问题,本月更新提供了对值筛选行为的控制选项。
在模型视图的属性窗格中,用户可以在【值筛选器行为】选择以下三种行为:
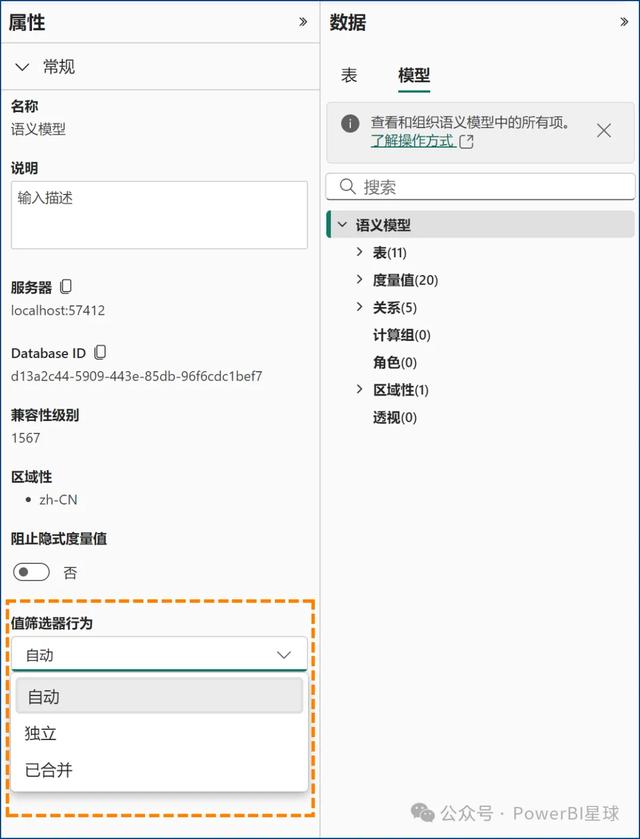 自动:这是当前的默认设置,启用Auto-Exist。以后结束此预览时,设置为“自动”的模型将默认使用"独立"。独立:强制关闭Auto-Exist,同一表的多个筛选器保持独立。合并:强制启用Auto-Exist,同一表的多个筛选器合并为一个。
自动:这是当前的默认设置,启用Auto-Exist。以后结束此预览时,设置为“自动”的模型将默认使用"独立"。独立:强制关闭Auto-Exist,同一表的多个筛选器保持独立。合并:强制启用Auto-Exist,同一表的多个筛选器合并为一个。通过选择适当的值筛选行为,用户可以更好地控制数据模型的计算结果。
对于上面的例子,如果设置为"独立",年度列和产品列就变成了两个独立的筛选器,它会考虑2024年的客户数量,所有产品的客户数将按预期返回6,而不会受到Auto-Exist的影响。

理解DAX中的Auto-Exist机制和值筛选行为,我们可以更好地控制数据模型的计算逻辑,避免意外的结果。
除了利用“值筛选行为”来控制Auto-Exist行为,其实更有效的做法是优化模型,通过维度表建立星型模型,不同类型的筛选器来自于不同的维度表,就不会出现多个筛选器来自一个表的情况,也就能从根本上避免Auto-Exist引起的问题。
PowerBI星球的最新版内容合辑,值得你收藏学习:
.
