家人们,还记得之前给大家介绍的OpenAI安全团队的翁荔吗~
翁荔,掌管OpenAI安全,北大才女,刚刚宣布离职
她离职后的第一个大动作,引发了全网的热议!
瓮荔发了一篇万字博客,分析了强化学习中奖励黑客(Reward Hacking)的问题,即智能体(Agent)利用奖励函数或环境中的漏洞来获取高奖励,而并未真正学习到预期行为。

瓮荔在博客中强调了黑客行为在大语言模型的RLHF训练中的潜在影响呼吁更多研究关注理解和缓解这一问题:
“在我看来,这是现实世界部署更多自主AI模型应用的主要障碍。”
接下来,和奶茶一起看下瓮荔在博客里面的干货吧~

博客链接:https://lilianweng.github.io/posts/2024-11-28-reward-hacking/
什么奖励黑客?瓮荔介绍:
奖励黑客(Reward hacking)是指强化学习(RL)智能体利用奖励函数中的缺陷或模糊之处来获得高奖励,而没有真正学习或完成预期任务的现象。
而这种行为之所以存在是因为两个原因:
强化学习的环境往往并不完美准确定义奖励函数本质上就是一个具有挑战性的问题随着大语言模型在广泛任务中的泛化能力不断提升,以及RLHF(基于人类反馈的强化学习)成为对齐训练的事实标准方法,在大语言模型的RL训练中的奖励黑客已经成为一个关键的实际挑战。例如,模型学会修改单元测试以通过编码任务,或者回答中包含模仿用户偏好的偏见。
而且,这些情况使非常令人担忧真实存在的问题,很可能是大语言模型在更自主的实际应用场景中部署的主要障碍之一。
过于关于这个问题的大多数工作都是很理论化,主要集中在定义或证明奖励黑客的存在。然而,对实际缓解措施的研究确实是灰常有限的~
背景知识在强化学习中,奖励函数不仅定义了任务本身,而且其设计方式对学习效率和准确性有着重大影响。设计一个强化学习任务的奖励函数往往被比喻为一种“暗艺术”。
这种复杂性来源于多种因素:
如何将宏大目标分解为小目标?奖励是稀疏还是密集?如何衡量函数设计是否成功?不同的选择可能导致学习动态的优劣,包括难以学习的任务或容易被操纵的奖励函数。在如何进行奖励塑造的研究领域,有着悠久的历史。早在1999年Ng等人就探讨了如何在马尔可夫决策过程(MDPs)中修改奖励函数,以保持最优策略不变。他们发现线性变换是有效的。给定一个MDP:

如果可创建一个变换后的MDP:

而且:

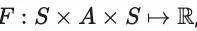
就可以引导学习算法更加高效。对于一个实值函数,对于所有的状态和动作对可以计算:

这将确保折扣后的奖励总和最终为零。如果是一个基于势能的塑造函数,那么它既充分又必要地保证了和共享相同的最优策略。
然后再假定:


并且如果我们进一步假设,其中是吸收状态,那么对于所有的状态和动作对:

这种奖励塑造的形式允许将启发式规则融入奖励函数中,以加速学习过程,同时不影响最优策略的实现。
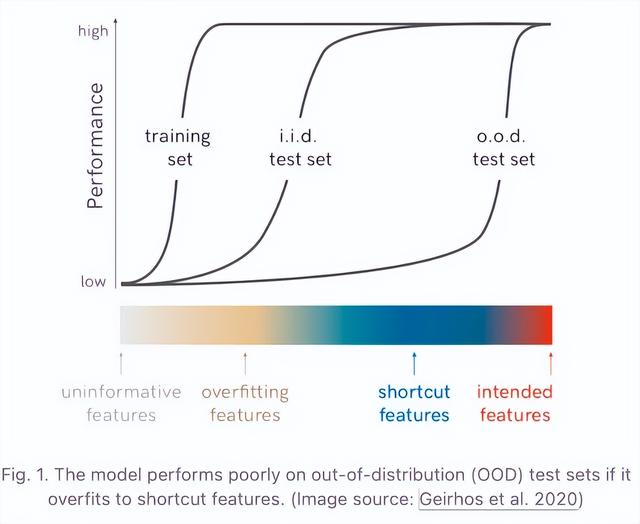
与奖励黑客攻击相关的概念还有一个是伪相关,也可以叫做捷径学习。
伪相关或捷径特征可能导致分类器无法按预期进行学习和泛化。例如,如果所有狼的训练图像都包含雪,那么一个用于区分狼和哈士奇的二元分类器可能会过度拟合到雪景背景的存在。
近年来,奖励黑客还有了很多相关的类似研究:
奖励黑客行为奖励腐败奖励篡改规格游戏目标鲁棒性目标泛化错误奖励误规范奖励黑客在现实中的例子瓮荔还列出了强化学习任务中的奖励黑客的实例:
一个经过训练以抓取物体的机械手臂,可能会学会通过将手臂置于物体和摄像头之间来欺骗观察者。一个旨在最大化跳跃高度的智能体可能会利用物理模拟软件中的一个漏洞,以达到不切实际的高度。在一个骑自行车到达目的地的任务中,智能体在接近目标时会获得奖励。结果,智能体可能会学会在目标周围绕小圈,因为在远离目标时没有受到惩罚。在一个足球游戏的环境中,当智能体接触到球时,会获得具有自我强化反馈的奖励。这种奖励函数可能会导致奖励被放大和扭曲,从而破坏了原始的设计意图,例如导致赢家通吃的广告投放算法。此外,确定智能体优化行为的确切奖励函数通常是不可能实现的,因为在固定的环境中可能存在无限多的奖励函数与任何观察到的策略一致。
2016年Amin和Singh两位研究人员将这种不可识别性的原因分为两类:
表示型 :在某些算术操作下(例如,重新缩放),一组奖励函数在行为上保持不变。实验型:观察到的行为不足以区分两个或多个奖励函数,这些函数都能合理化智能体的行为(在这些函数下,行为都是最优的)。为什么会出现奖励黑客?根据 Amodei 等人2016 年的研究,奖励黑客的产生可归因于以下几方面:
环境状态和目标的不可观测性 现实中的环境状态和目标通常难以完全观测,这使得设计的奖励函数无法完美表征环境真实情况。奖励函数的不完善为智能体在优化过程中出现偏差提供了可能。系统复杂性 系统越复杂,越容易受到攻击,尤其是在允许智能体执行可改变环境状态的代码时。这种自由度可能被智能体用于寻找奖励函数中的漏洞。抽象概念的奖励定义困难 涉及抽象概念的奖励函数在学习和表述上存在困难。例如,人类价值观或复杂的伦理准则难以用简单的数值化目标来描述,从而导致奖励函数与实际目标出现偏离。强化学习目标的内在矛盾 强化学习的核心目标是高度优化奖励函数,这种高度优化与设计良好的实际目标之间存在内在冲突。这种冲突可能导致智能体过度专注于奖励最大化,而忽视更广泛的目标。奖励函数歧义性 一个特定的智能体行为可能与多个奖励函数相一致,因而很难准确识别其真正优化的目标函数。理论上,在缺乏完备信息的情况下,精准判断奖励函数几乎是不可能的。解决方法翁荔表示虽然研究界都证实了奖励黑客现象的存在,但是只有很少的研究团队在解决这个问题。目前只有三种做法:
改进强化学习算法Anthropic创始人Dario Amodei在2016年发表的论文《Concrete Problems in AI Safety》提到了一些解决的方向:
对抗性奖励函数:将奖励函数本身视为一个自适应智能体,它能够适应模型发现的新技巧,即那些奖励值高但人类评分低的情况。模型前瞻:可以基于预期的未来状态给予奖励;例如,如果智能体要替换奖励函数,就会得到负面奖励。对抗性掩盖:我们可以遮蔽、掩盖模型的某些变量,使智能体无法学习到能够黑客攻击奖励函数的信息。谨慎工程:通过谨慎的工程设计可以避免某些类型的系统设计奖励攻击;例如,将智能体沙箱化以隔离其行为与奖励信号。奖励上限:这种策略是简单地限制最大可能的奖励,可以有效防止智能体通过黑客攻击获得超高回报策略的罕见事件。反例抵抗:提高对抗鲁棒性应该有助于提高奖励函数的鲁棒性。多重奖励组合:组合不同类型的奖励可以使其更难被黑客攻击。奖励预训练:我们可以从(状态,奖励)样本集合中学习奖励函数,但这取决于监督训练设置的好坏,可能会带来其他问题。RLHF依赖于此,但学习到的标量奖励模型很容易学到不期望的特征。变量无差异:目标是让智能体优化环境中的某些变量而不是其他变量。陷阱机制:可以故意引入一些漏洞,并设置监控和警报,以便在发生奖励攻击时发现。
在以人类反馈作为智能体行为批准的强化学习设置中,Uesato等人(2020)提出使用解耦批准来防止奖励篡改。如果反馈是基于(状态,行为)的,一旦这对组合发生奖励篡改,我们就永远无法获得该状态下该行为的未被污染的反馈。解耦意味着收集反馈的查询行为与在现实世界中采取的行为是独立采样的。反馈在行为在现实世界中执行之前就已收到,从而防止行为污染其自身的反馈
检测奖励黑客行为想象一下,我们有一个任务,就是要找出那些不按规则行事的“黑客”。这就像是在玩一个游戏,游戏里有一些规则,但是有些人不遵守这些规则。我们的任务就是找出这些不守规则的人。
我们有一些已经标记好的游戏记录,这些记录告诉我们哪些行为是正确的,哪些是错误的。我们还有一个“可信策略”,它告诉我们什么是正确的行为。我们的目标是建立一个工具,这个工具可以帮助我们区分正确的行为和错误的行为。
为了做到这一点,我们可以比较两种策略:一种是我们知道是正确的“可信策略”,另一种是我们想要检测的“目标策略”。我们可以通过比较这两种策略的行为差异来建立一个分类器,这个分类器可以帮助我们判断一个行为是否异常。
然后,我们可以测试这个分类器的准确性,看看它是否能准确地找出那些不守规则的行为。但是,我们发现不同的分类器在不同的任务中表现不同,而且在我们测试的所有强化学习环境中,没有一个分类器能达到60%以上的准确率(AUROC是一个衡量分类器性能的指标)。
 分析RLHF数据。
分析RLHF数据。通过研究训练数据是如何影响模型对齐的结果,可以获得关于数据预处理和收集人类反馈的有用见解,这样就能降低模型出现“奖励黑客”问题的风险。
今年,哈佛大学和 OpenAI 的研究人员合作发表了一篇名为《SEAL:Systematic Error Analysis For Value ALignment》的论文。
他们提出了一套评估指标,用来衡量数据样本的特点在模型构建和对齐人类价值观方面的有效性。他们在 HHH-RLHF 数据集上进行了系统的错误分析,以实现价值对齐(SEAL)。

图21. (左图) 特征印记(pre-) 和 (post-) 是通过对奖励值进行固定效应线性回归计算得出,将奖励值(橙色)和(蓝色)对特征进行回归分析。总体而言,对齐训练对无害性和助人性等正面特征给予奖励,对色情内容或侵犯隐私等负面特征进行惩罚。(右图) 特征印记是通过对奖励偏移量进行线性回归计算得出。奖励偏移量定义为对齐训练前后奖励向量之间的角度。训练过程优化了模型对目标特征的敏感度。值得注意的是,无害性特征通过被选中和被拒绝的条目("is harmless ©“和"is harmless ®”)都在奖励模型中留下印记,而助人性特征仅通过被拒绝的条目(“is helpful ®”)留下印记。
SEAL引入了三个指标来衡量数据对对齐训练的有效性:
特征印记(Feature imprint)指的是特征的系数参数,用于估算在其他因素保持一致的情况下,具有该特征与不具有该特征的条目之间的奖励分数增加值。
对齐阻抗(Alignment resistance)是指奖励模型(RM)未能匹配人类偏好的数据对的百分比。研究发现,在HHH-RLHF数据集中,超过1/4的情况下RM会抵制人类偏好。
对齐稳健性(Alignment robustness)衡量对齐在输入被干扰(通过重写情感、口才和连贯性等干扰特征)时的稳健程度,可以分离出每个特征和每种事件类型的影响。
结语翁荔大佬在离职后的大动作确实引人注目!

她聚焦于强化学习中的一个关键问题——奖励黑客(Reward Hacking)。这一问题涉及到智能体(Agent)利用奖励系统或环境漏洞来获得高额奖励,而并没有真正掌握预期的行为。
翁荔呼吁业界加大研究力度,以更好地理解和缓解这一问题。此外,她也坦言这篇研究不易完成~(奶茶看的也非常不易呜呜,请看官大老爷们给个三连!)

同时也有不少来自OpenAI的前同事对此表示推荐和支持。

奶茶将继续期待翁老师的新动作~~