一直“沉默”的苹果突然爆出在人工智能研究上取得了重大突破。
多模态大模型MM1上周,苹果的研究团队在arxiv.org上发布了一篇题为《MM1: Methods, Analysis & Insights fromMultimodal LLM Pre-training》的研究论文。

在论文的摘要中,苹果的研究团队表示:“我们证明,对于大规模多模态预训练,使用图像标题、交错图像文本和纯文本数据的仔细组合对于在多个基准上实现最先进的少数镜头结果至关重要。“
摘要还提到:“得益于大规模的预训练,MM1具有增强的上下文学习和多图像推理等吸引人的特性,可实现少量的思维链提示。”这表明其能够使用少量“思维链”提示对多个输入图像进行多步推理,同时也意味着其多模态大模型有可能解决需要基础语言理解和生成的复杂、开放式问题。
根据论文的介绍,MM1具有三种大小:30亿、70亿和300亿参数。研究人员利用这些模型进行实验,找出影响性能的关键因素。
有趣的是,图像分辨率和图像标记的数量比视觉语言连接器的影响更大,并且不同的预训练数据集可以显着影响模型的有效性。“我们证明,图像编码器、图像分辨率和图像标记计数具有重大影响,而视觉语言连接器设计的重要性相对则相对较小。”
研究团队采用“Mixture of Experts”架构和“Top-2 Gating”方法精心构建了MM1。这种方法不仅在预训练基准中产生了优异的结果,而且在现有的多模式基准上也转化为强大的性能。即使针对特定任务进行微调后,MM1模型仍保持有竞争力的性能。
“通过扩展所介绍的方法,我们建立了MM1,这是一个多模态模型系列,参数多达300亿,由密集模型和混合专家模型(MoE)变体组成,在预训练指标上达到了最高水平,并在一系列既定的多模态基准上经过监督微调后获得了具有竞争力的性能。”
测试表明,MM1-3B-Chat和MM1-7B-Chat型号的性能优于市场上大多数类似尺寸的竞争对手。这些模型在VQAv2(基于图像和文本的问答)、TextVQA(基于图像的文本问答)和 ScienceQA(科学问答)等任务中尤其出色。
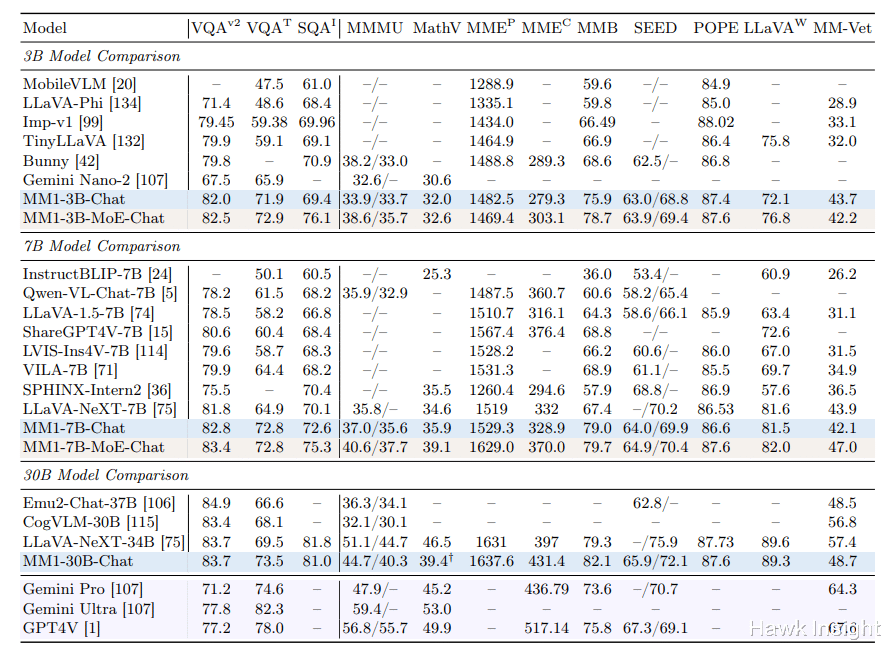
然而,MM1的整体性能还没有完全超越谷歌的Gemini或OpenAI的GPT-4等全球顶尖模型。虽然MM1可能还不是绝对的领导者,但它仍然是苹果在人工智能领域的重大飞跃。
正如苹果研究人员所说,MLLM(多模态大语言模型)已经成为继传统 LLM(大语言模型)之后“基础模型的下一个前沿”,并且它们“实现了卓越的功能”。
苹果的“奋力追赶”MM1研究发布之际,苹果一直在加大对人工智能的投资,以追赶谷歌、微软和亚马逊等科技企业。这些企业在将生成式人工智能功能集成到其产品中方面已经取得了领先地位,相比之下,苹果却迟迟拿不出具有竞争力的成果。
有消息人士称,苹果正在开发一个名为“Ajax”的大型语言模型框架,以及一个内部称为“Apple GPT”的聊天机器人。目标是将这些技术集成到Siri、Message、Apple Music和其他应用程序和服务中。例如,人工智能可用于自动生成个性化播放列表,协助开发人员编写代码,或进行开放式对话和任务完成。
“我们将人工智能和机器学习视为基础技术,它们几乎是我们推出的每一款产品中不可或缺的一部分。”苹果首席执行官蒂姆·库克(Tim Cook)在最近的财报电话会议上对分析师表示,“我不会详细说明它是什么……但可以肯定的是,我们会投资,我们会投入相当多的资金,我们会负责任地去做,而且随着时间的推移,你会看到产品的进步,而这些技术正是产品的核心。”

他还在电话会上表示,“我们很高兴能在今年晚些时候分享我们正在进行的人工智能工作的细节。”因此,许多人推测苹果有可能在今年6月份的全球开发者大会上,推出新的人工智能功能和开发者工具。
与此同时,苹果研究实验室推出的Keyframer动画工具和性能增强等较小的人工智能进展也表明,苹果正在默默进步。