前言
从23年开始,我们团队开始前端错误监控方向的开发。经历了一些列的迭代和发展,从监控SDK、上报、数据治理、看板集成、APM自研可视化初步完成了一条完整且适合B站前端监控。
截止目前(2024.08.01),前端监控在B站85%以上的业务线,1700+项目中运行。今年初APM平台的落地接入了210+的项目,5月新推出的一键告警配置功能也达到了300+。

本文中,我会介绍我们一系列的迭代、发展过程中,B站前端错误监控初步落地的解决方案和我们团队积累的一些经验。也介绍一下B站前端监控的大致链路。
为什么要自建监控?
一提到错误监控,大部分前端开发者都会想到 `Sentry`,那么我们为什么不使用 Sentry呢?其中最重要的原因就是更适合B站完整的数据链路和可定制化能力,例如:
方便使用自研上报的SDK,分业务和技术上报通道,兼容多种历史版本的上报脚本。方便团队清洗、过滤数据从而得到多维度的数据分析、错误追溯。方便团队对聚合指标分析、可视化大盘、一键告警,链路追踪、直接对接内部平台等等。SDK
B站前端监控sdk(bili-mirror,后简称mirror),在1年多的迭代后主要的功能分布如下图所示,下面会从几个功能点大致介绍一下上报SDK的能力,以及一些简单的代码。

js-sdk的功能点
错误捕获
前端的JS错误监控本质并不复杂,浏览器已经提供了全局的捕获异常方案
// 同步异常window.addEventListener('error',(error)=>{// 分析错误->上报})// 异步异常window.addEventListener('unhandledrejection',(rejection)=>{// 分析错误->上报})捕获到错误仅仅是相关工作的第一步,对于不同类型的错误解析、处理、过滤、是否重复等问题都需要一一去解决。
顺带提一下,同步错误我们可以使用window.onerror和 window.addEventListener('error')
mirror使用了后者的原因有两点:
addEventListener不像window.onerror会被重新覆盖addEventListener可以处理静态资源错误且触发优先级高于window.onerror错误处理
获得整体错误对象后,mirror做的第一步就是区分错误类型。
通过window.addEventListener('error',fn)捕获到的错误分为2种:'JS运行错误’ 和 ‘资源加载错误’, 下面是mirror的区分方法。
export const handleJsError = ev =>{ const target = ev.target if (!target || (ev.target && !ev.target?.localName)) { // JS运行错误 } if(target?.localName){ // 资源加载错误 }}// promise 错误export const handlerRejection=ev=>{}针对资源加载错误
通过 `localName` 来区分具体资源的类型,
通过`src` or `href` 来确认资源加载失败的地址
形成 需要上报的数据集合
JS错误和异步错误
解析错误使用了第三方插件 `error-stack-parser` ,开启gzip后只有2.2kb的解析库,获取一些详细的错误信息,比较值得推荐直接使用。
let stackFrame = ErrorStackParser.parse(!target ? ev : ev.error)[0] // 错误文件、行号、列号、源文件、堆栈等等let { fileName, columnNumber, lineNumber, source } = stackFrameconst stack = source ? JSON.stringify(source.split('').join('').split('./')) : ''最后整理好数据格式后,接下来就是一些过滤的配置。
错误过滤
在错误收集中,常会遇到几个问题。
如果避免重复上报相同的错误而导致不必要的资源浪费?如果根据业务从不同维度去屏蔽错误,例如ua、js屏蔽、rejection屏蔽,特定message屏蔽等等。监控sdk都会面临的一个问题,海量的数据上报,导致错误数据都是亿级别的量级,所以首先我们需要认清一个问题。
用户一次会话中,产生了同一个错误,那么将同一个错误多次上报是没有意义的用户在不同会话中,产生了同一个错误,将同一个错误多次上报是有意义的
mirror也是借鉴了一些参考后,决定选择一种生成唯一id的方法,利用了原生的 window.btoa(https://developer.mozilla.org/zh-CN/docs/Web/API/btoa),来实现唯一id的功能,来确保会话中相同的错误不会多次上报。
// 生成唯一错误idexport function getErrorId(val) { return window.btoa(decodeURIComponent(encodeURIComponent(val)))}// 是否上报过同类型错误的idconst getIsReportId = error => { const id = getErrorId(error?.message || error?.fileName) const even = item => item === id if (ERROR_ID.some(even)) { console.warn(`Duplicate error, not reported,${error?.message}`) return false } else { ERROR_ID.push(id) return true }}在业务定制化维度方面,对接了内部kv平台。下发不同配置的逻辑会有默认配置和业务配置深度合并的策略,形成一个整体项目的配置在不同的维度进行过滤上报的功能。我们也有权限级别最高的顶层配置来保障业务配置错误后的临时管控策略。
... // 拉取配置信息 // 合并配置 let config = deepMerge(baseConfig, pageConfig) // 合并顶层配置 config = deepMerge(config, topConfig) return new Promise((resolve,reject)=>{ // 定义配置,初始化的一部分 })合并后的kv会返回一个JSON对象,在约定好的key值中去配置对应的过滤信息,mirror会读取这些信息完成业务的定制化操作。
let errorData_resource = handleResourceError(ev) // 如果资源目标为空则过滤 if (!errorData_resource || !errorData_resource.message.trim().length) return const filterListResource = options?.config?.white?.resource const isFilterResource = handlerFilter(errorData_resource, filterListResource) const isFilterUa = handlerFilterUa(options?.config?.white?.ua) // ua命中过滤,不上报 if (isFilterUa) return // 对应配置过滤 if (isFilterResource) return // 唯一id判断 if (!getIsReportId(errorData_resource)) return // 上报资源错误上报前置过滤示例
白屏检测
在前端开发中,往往头疼的就是白屏了。特别是现在SPA项目的盛行,前端的白屏变得更为复杂和棘手。往往我们在上线过程中,无法得知是何种情况出现了白屏。
白屏检测的方案
在调研白屏检测的方案中,我们发现大致有以下4种选择
检测节点是否渲染 + onError的监听Mutation Observer 监听DOM的变化关键点采样对比H5 或者native的 canvas绘图和容器截图检测第一种原理很简单,在SPA流行的今天,DOM一般挂载在某个根节点之下(比如)。在白屏发生后(异常发生后),节点下的DOM被卸载,所以在onerror触发后,去检测节点是否挂载,是简单明了的。但是可能只是特别适合SPA项目,只观测一个根节点也是比较粗暴的。
第二种方法的劣势比较明显,需要根据实际情况来确认阈值。设置的时间太短可能出现误判的情况,设置的时间太长会影响页面的性能 。
第四种的话 利用canvas或者是 native容器截图,从性能影响和实现复杂度上都比上面3种的优先级要低一些,对于骨架屏的支持度也会是个问题。
最终还是确认了采用第三种关键点采样的方法,来实现白屏检测。
白屏检测的实现
关键点采样对比,利用的就是 document.elementsFromPoint(x,y) (https://developer.mozilla.org/en-US/docs/Web/API/Document/elementsFromPoint)这个函数返回特定坐标点下的HTML元素数组。
在各种社区、文章中其实已经有不少介绍利用这个API完成白屏检测的文章,方案很多,例如:【垂直选取】、【交叉选取】、【垂直交叉选取】、【页面网格深度采集】等等。
mirror选择了比较普遍的垂直选取。大致的原因是我们觉得白屏的检测在确保准确度、复杂度和性能消耗之间我们需要一个平衡点。 垂直选取的策略适用于大多数业务。

垂直选取示意
for (let i=1; i<=9;i+=2){ const xElements = document.elementsFromPoint((window.innerWidth * i) / 10, _global.innerHeight / 2) const yElements = document.elementsFromPoint(_window.innerWidth / 2, (_global.innerHeight * i) / 10)}获取垂直选点的代码示例
从垂直可以延伸出上文所说的交叉、垂直交叉等等方案,本质是一样的,区别在于页面获取更多的点位,返回的是这个点的dom层级,经过一些列的遍历后可以寻找是否有对应的class或者id、标签等等。
页面网格深度采集更类似于把整体页面分为多个相同的块,利用DOM层级深度来显示页面的复杂度和某个模块是否正常运行。

这个检测的功能更适用于一些特定的场景和复杂业务的特殊定制化需求,我们也是有别的团队的同学基于mirror给出的生命周期插件入口完成了拓展功能。
白屏的修正机制
在第一次检测白屏的情况出现时,浏览器的整体渲染可能还没有完成,特别是移动端页面。用户糟糕的网络环境、关键JS资源或接口还没有返回的情况都是导致页面白屏的可能原因。这时我们就需要一个轮询检测机制,去检测白屏的正确性。这个就是修正机制

修正机制的大致示意图
请求错误
mirror内部提供了一个固定封装的上报api状态的方法,一般在普通的axios项目中可以利用对应的Success和Error的钩子去上报api的请求状态。之前我们团队产出的《统一请求库》中也封装了对应的中间件。在内部使用时已经可以自动收集上报数据了。
我们在统计接口错误率维度的时候往往需要针对每一条请求发送一条上报,再接入实际业务中我们发现,一条请求一次tech上报的消费过于“昂贵”。所以针对正常请求和错误请求做了区分:
正常请求:在mirror中聚合了所有成功请求,在一些可配置的时间内(可以kv配置聚合度时间)固定聚合发出请求成功的数量,来减轻数据测消费和清洗的压力。
错误请求:在api请求异常或者设置code为异常值后,mirror会立即上报请求相关信息,其实也包括trace_id,api地址,参数,响应等等作为后续可以查看完整链路的索引。

这样我们在大量的减少实时上报api数据的同时也保障了可以比较准确的去计算API的接口成功率,对于错误会实时上报处理,方便后续追踪。
SDK 插件机制 —— 以生命周期插件为例
为满足整体 B 站不同业务线的诉求(上文提及的网格深度)以及有效控制 SDK 的体积大小这两项需求,mirror 具备生命周期插件功能便成为势在必行之事。
生命周期插件功能具有诸多优势。首先,它能够灵活地满足不同业务线的特定需求,通过 before 和 after 两个生命周期节点,可以针对不同类型的事件进行个性化的功能注入,极大地提高了 mirror 的适应性和可扩展性。其次,对于业务接入而言,其复杂度较低、成本较小,使得开发人员能够更加高效地集成和使用 mirror。再者,利用 Promise 完成前置和后置操作,确保了操作的有序性和可靠性,提升了系统的稳定性和性能表现。
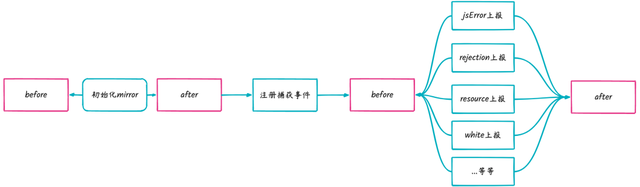
生命周期节点
在充分考量复杂度与业务接入成本后,mirror 的整体生命周期针对不同类型的事件设置了 before 和 after 这两个生命周期节点,以便注入相应的额外功能。整体通过 Promise 来完成前置和后置操作。在 mirror 的文档中,设有简单的代码实例,规定类似 “before” 和 “after” 的钩子,并根据不同的 type 类型完善逻辑。最后,将实例化后的对象传入 mirror,便会在对应的节点自动执行。
下面是一个常见的自定义过滤一些业务特定错误使用的case:
// 一些错误过滤const errorFilterList = ['some-ignore-message']class MirrorXxPlugin { mirrorHandleBefore(type, data) { return new Promise(resolve => { if (type === 'error' || type === 'unhandledrejection') { const isMatch = errorFilterList.some(str => data?.message?.includes(str)) resolve(!isMatch) } else if(type==='resource'){ // 可以执行任意业务定制逻辑 resolve(true) }else { resolve(true) //true继续执行,false中止执行后续 } }) } mirrorHandleAfter() { return Promise.resolve() }}const mirrorFilterPlugin = new MirrorXxPlugin()// 实例对象放入mirror配置中即可离线、行为日志
离线、行为日志是mirror今年上半年主要完成的一项功能点。主要功能在于记录用户网页的操作日志,存储在不同的地方。那么在记录用户网页中操作的逻辑是可以共用的,mirror现在可以支持记录的行为有:
各种类型的错误(js\rejection\resource\white)页面状态(载入、刷新、关闭、tab切换)事件监听(history路由、hash路由、click点击,滚动高度)请求记录 ( 请求成功或者失败)行为日志:存在本地,当堆栈满后且没有任何错误的情况下,清除堆栈继续记录。行为日志不记录页面状态。
离线日志:存入indexDb中,根据用户的操作顺序记录每一步操作,有一定的条数上线和大小控制,堆栈满后进一出一原则。
行为日志与离线日志在获取数据方面采用统一封装,但也存在一定区别:行为日志采用自动收集上报机制,主要作用在于收集与错误是否有关联的操作日志;而离线日志则是记录全部日志,在业务需要时主动上报收集。
具体而言,行为日志存储于 localStorage 中,默认初始化堆栈为 10 条(可通过键值对配置)。当堆栈满且无任何错误时,将清除堆栈并继续记录,但行为日志不记录页面状态。行为日志适用于快速定位和分析与错误相关的用户操作场景,比如当系统出现特定错误时,可以通过错误前后的相关请求和操作日志的情况进行关联,从而更好地理解错误产生的原因和上下文,有助于开发人员进行针对性的修复和优化。
离线日志则存入 indexDb 中,按照用户的操作顺序记录每一步操作,当堆栈满后遵循进一出一原则,整体大小控制在 3M 以内。离线日志主要应用于需要全面记录用户操作历史的场景,例如在进行用户行为分析、业务流程优化或者故障排查时,可以借助离线日志获取详细的用户操作序列,以便深入了解用户的使用习惯和系统的运行情况。


行为日志和离线日志的记录
数据支持
我们可以按以下层次划分数据开发结构,按层次顺序讲解一些是支持方面遇到的问题和思路。
数据采集:各种采集数据的方法上文都有介绍,此处略。数据存储:除了业务数据(pv上报、业务埋点)走业务通道链路外(公司标准链路,不做额外改造),大部分数据都走技术链路,主讲技术链路的改造。数据服务:从数据库到BI展示之间的一些数据处理,主讲数据治理和一些奇妙的字段选取。数据应用:下游平台主要涉及4个,行文会提一下平台调研选取。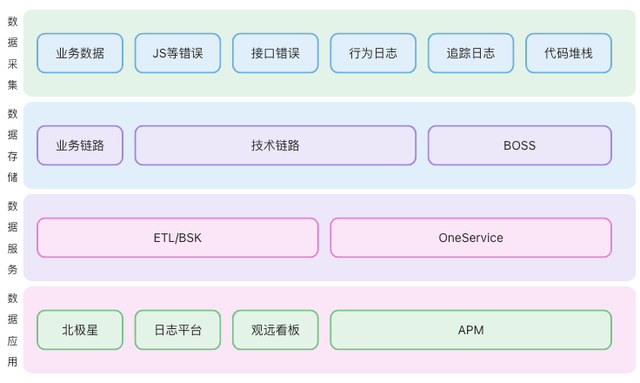
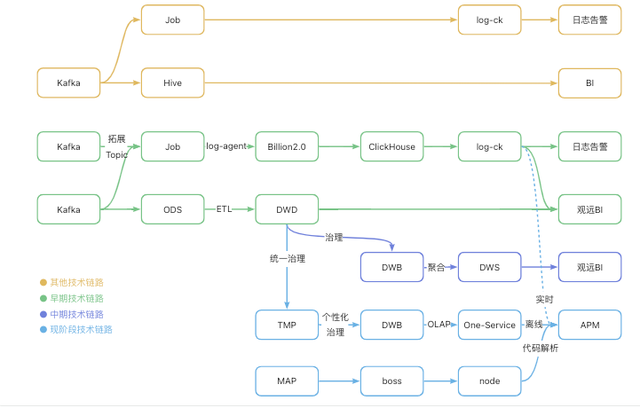
技术链路改造
除了业务数据(pv上报、业务埋点)走业务通道链路外(公司标准链路,不做额外改造),大部分数据都走技术链路。
其他技术链路
在已有的技术链路中,数据都是由 Kafka 接收, 一条链路写入到 ES 中接入 ops-log,另一条链路写入 Hive 接入观远 BI。我们评估后发现,这条技术链路缺少扩展Topic能力,以及服务 Job 没有能力执行控制策略,如流量控制等。
早期技术链路
因此在早期技术链路中,在对已有技术链路低成本迁移的基础上,经过一个服务 Job 接入日志平台 log-agent ,加入了Billion2.0日志系统,来解决上述问题。Billion2.0日志系统使用了 clickhouse 作为底层的查询引擎,速度更快。这条技术链路实时数据延迟在5分钟内,离线数据则是小时级。同时,从不同ODS(源数据)抽取、处理,将数据存在一个便于读取的DWD表中。观远BI直接读取DWD表,看板加载时会对数据做计算。
中期技术链路
中期,随着业务接入,观远看板出现开屏卡顿的问题,研究发现是”数据量太大,超出看板计算能力“。于是,我们采取了一些数据治理方法,在DWD后面增加一些数据治理方法(得到DWB数据基础表),并将离线计算移动到观远上游bsk中(得到DWS汇总表)。
现阶段技术链路
现阶段,我们将数据治理拆分成两步,先根据共性统一处理得到临时表TMP,再根据不同指标特征处理得到新的数据基础表DWD;接入OneService平台取代离线计算,这样的好处在于落库的高维特征能够灵活输出给APM,避免离线计算降维。APM是我们自研的数据可视化平台,通过node服务还能够接其他平台的数据。
从0到20的可视化平台
数据可视化,是所有自建项目的必经之路。我们的决定是分几步走:有0、0到1、1到100。
第一阶段,数据看板有就行。早期数据规模不大,在成本考虑上,建议借助一些第三方BI平台展示数据。这让我们节省精力、专注开发,成熟的BI平台也能帮助梳理思路。因此早期,我们直接将数据透传给观远看板,由看板端进行数据处理,敏捷开发。当时的看板也只有两个,性能看板和通用的错误看板。
第二阶段,从0到1开始建设合需的看板。这个阶段,有一定的数据积累,我们根据收到的业务情况,按需求优先级开发指标看板。到目前为止,观远看板已有8+,分别是性能、JS+Rejection错误、Resource错误、API错误、白屏错误、PV、项目详情、数据大观等。观远看板主要展示数据,其他功能会借助其他平台现有功能,以求快速建设生态圈。
第三阶段,开始自研数据可视化平台。这个阶段不能太急,自研平台对人力、成本的要求很高,还需要足够的数据积累和功能支持。
在上个阶段,基于观远看板我们也做了一些数据分析,比如城市浏览器聚集度分析、错误类型分析等,收到用户好评。同时,用户也提出了更多的需求,我们也提供了处理好的DWS汇总表,用户可以自己开发,我们也在观察用户的使用情况。
研究发现,初级数据需要用户自己发现错误、定位错误、分析怎么处理错误,而业务方期望能有更直观的数据指明错误、定位错误,并能够直接告诉他们怎么做,甚至是帮助他们完成操作。
BI平台也会有一些限制,业务方期望的KV配置、代码解析、告警配置等操作都要依赖其他平台,BI平台不好接入。除此之外,离线计算会对数据特征聚合计算,只能输出低维空间导致决策欠拟合。基于此问题,我们自研可视化平台APM,各种功能接入能力大大提升,并用OneService平台代替离线计算,它具有线上计算能力,能够根据参数灵活调整SQL,同时他还支持OLAP。
总结一下,数据可视化步子不能跨得太大,要合乎当前场景和需求。第三个阶段我们还在开发中,APM主要在做观远看板之外的能力建设,只能说完成了APM 20%的目标,后面还有很长的路要走。
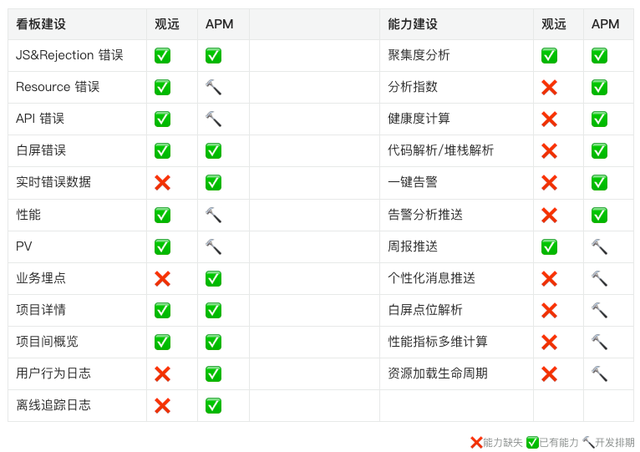
(现阶段)观远和APM的能力对比
收益颇丰的数据治理
遇到过两次瓶颈:第一次观远看板会遇到加载失败的问题,研究后发现是因为数据量太大,观远计算超时。于是我们采用了一些方法治理数据,并将计算任务迁移到观远上游处理,收益颇丰,将45亿/日的数据压缩到了2亿/日落库。第二次则是服务器占用问题,瓶颈主要在Kafaka等,所以主要操作是在采集阶段做一些处理,如聚合API上报、剪摘技术PV等方法。治理收益是原始数据80亿/日,处理后打到服务器只有20亿/日。
此处主要讲述第一次数据治理的操作:
筛选清洗:剔除脏数据,减少数据体积;处理字段,减小特征空间。特别地,有些字段的特征空间过于庞大,会导致欠拟合问题。针对这些字段,会做一些特殊处理,如接口会清洗api、page字段的参数,资源会清洗msg中的hash值。mid、ua、ip等用户信息和视频稿件信息的特征空间最庞大,前期服务器资源有限建议舍弃,或者提取其中的关键信息减小映射空间,如ua只拿浏览器版本设备型号,ip只拿城市运营商。
特征选取:选取主要特征。第一阶段是从业务案例中学习、打标,然后通过计算相关性和信息熵来粗筛(数据集不大,选用方法也比较简单)。为了更好地选取数据特征,我们需要更多的业务案例,也在鼓励业务方反馈使用情况。
第二阶段根据业务反馈调整字段,先后增加了国家城市、浏览器版本、视窗大小、发布版本等。最初的看板数据容量有限,特征越少、聚合效果越好、数据量越少,所以最初不得不舍弃了很多字段。
离线计算:将计算任务转移到bsk,减轻看板加载负担。前期只有计数聚合,各个看板还会有特殊处理,如性能指标要求计算百分位数、接口指标还要关心code中msg的分布。后期的计算任务更复杂,会统计当前错误聚集度最大的城市、浏览器、发布版本等,还会统计错误的最大日环比、最早出现日期等。
数据功能的进化之路
不积跬步、无以至千里。数据的积累,是功能的基础。
聚集度分析数值化
常见的聚集度分析是什么?
就是一个个饼图、柱状图。我们有城市、浏览器、分布版本等十几个饼图,业务全部看完后发现“xx城市占报错60%以上,这个错误有城市聚集”——从十几个请求到业务恍然大悟,这个链路可以更简单——请求一次,返回指标聚集度No.1,业务看数字即可。
除了常见的城市浏览器聚集度,根据业务需求,我们挖掘了新的特征:最早出现日期、是否突增、报错文件堆栈聚集度等。

以下是干的不能再干的SQL干货:
1. 查询聚集度第一:占比第一的sql其实不难,我们遇到的难点有几个:
十几个聚集度指标,十几次查询 → 希望合成一次查询看板支持多种查询条件 → 希望聚集度分析也支持业务:只想看聚集度高的指标 → 指标也支持过滤解决思路:先根据看板查询条件,得到一个查询表t_search;再多查询表做聚集度分析,t_num、t_agg_city等;最后将多个聚集度查询表合一,在此表上做聚集度过滤。
WITH t_search AS ( -- 条件查询 SELECT * FROM ${DWD表} WHERE log_date>="日期" -- 其他条件略),t_num AS ( -- 基于条件查询,统计上报次数 SELECT msg, COUNT(*) AS num_report FROM t_search GROUP BY msg),t_agg_city AS ( -- 基于条件查询,统计城市的聚集分布 SELECT msg, ip_city AS _name, COUNT(*) *1.0000 AS _num, -- 要计算占比,转换成小数 ROW_NUMBER() OVER ( PARTITION BY msg ORDER BY COUNT(*) DESC ) AS row_num -- 降序行号 FROM t_search GROUP BY msg, ip_city)-- 最终结果输出SELECT *, t_agg_city._num / t_num.num_report AS browser_max_ratioFROM t_numJOIN t_agg_city ON t_agg_city.msg = t_num.msg AND t_agg_ci.row_num = 1WHERE t_agg_city._num / t_num.num_report >= "查询条件2"2. 最早出现日期、最大日环比:先统计相邻两天的数据,再计算日环比,找出最大值,以及最小日期。
WITH t_day AS ( -- 统计当天的报错 SELECT msg, log_date, COUNT(*) AS num_report FROM t_search GROUP BY msg, log_date),t_yesterday AS ( -- 统计前一天的报错 SELECT msg, log_date, num_report AS n_today, IF (log_date = min(log_date) OVER ( PARTITION BY msg), num_report, LAG (num_report) OVER (ORDER BY msg, log_date)) AS n_yesterday FROM t_day),agg_day AS ( -- 计算:最大的日环比、最早出现的日期 SELECT msg, MAX((n_today - n_yesterday) * 1.0000 / n_yesterday) AS max_sudden, IF(MIN(log_date) = "查询日期", '', MIN(log_date)) AS min_date, COLLECT_LIST(MAP(log_date, n_today)) AS days_num -- 还可以把每日上报次数传给前端,画个小折线图 FROM t_yesterday GROUP BY msg)分析指数辅助决策
聚集度数值展示时,在使用过程中发现了几个小小地规律:
黑灰产利用脚本、爬虫等产生的错误 ,会具有几个特征:ip聚集、ua聚集、上报文件为脚本等。如果同时满足以上三个特征,很有可能不会是正常用户会出现的错误,这样的错误一般交由风控来处理,前端开发可以先去处理其他错误。一个新出现错误的危险程度远大于早已存在的。如果这个错误是近几天刚出现,而且上报暴涨,开发应该提高关注。如果这个日期有正好是发布版本的日期,且灰度版本号是最大的(暂未接入发布平台,默认最大的版本号为最新的),那必须提高警惕。有几种错误在APM平台修复速度最快,一个是支持soucemap的错误,另一个是有关联用户行为日志的错误。根据上面三种规律,我们挖掘出了新的高维特征:黑灰产指数、错误危险指数、建议修复指数,页面上简化为黑产、危险、修复,如下图。

未来进化之路
从图表到数值,再从数值到分析指数,看起来我们走了很远,实际上分析指数还有很多的数据可以结合,给业务提供更好的决策信息。
前面也提到soucemap的可行性是有一定误差的,后续的计划就是能够接入map数据库,提高soucemap可能性的精准度;同时也期望能够接入发布平台dejavu的数据库,结合发布信息更精准地去判断发布日期和当前线上版本(实验阶段不止一个版本);APM还有很多错误分析手段,比如离线追踪日志、一键告警,推荐修复指数还可以结合更多数据;很多错误之间是有关联性的,比如资源错误很可能是请求失败导致的,通过这种关联系也可以解决一部分问题;……这些数据,都是我们期望能够加入到分析指数的。
项目健康度算法
此算法的最初形态是”项目详情“,我们会把项目名下所有上报数据都罗列出来,但不够清晰有力,遇到一些问题。我们最终决定在现有数据的基础上,开发一个健康度指标:
确定衡量指标:现有指标过多,有的项目看重性能,有的看重白屏,不统一不明确。我们按需选取几个关键指标,如性能LCP、白屏报错数量等。确定评估方式:每天的pv会影响错误的上报趋势,因此评估一些错误指标的时候,我们取上报次数和pv的比值。另外,还有几个指标特殊处理,如性能指标取90分位数,资源错误取uv维度的上报次数和uv的比值,而接口取了最大错误率。划分等级区间:每个指标的上下限是不一样的,我们要对其划分区间的同时,也要排除一些极端值对其的负影响。因此,我们以指标近30天的的百分位数作为阶段健康区间,将指标分为10个等级。拟合曲线公式:上述的10个等级是离散的,我们还需要设计一个顺滑的分数曲线,将其映射到0-100的分数曲线。确定权重:每个指标对页面的影响不一,其权重也不该一样。如,相比性能LCP,白屏更严重,权重也应该更高。我们根据业务反馈来确定各个指标权重。项目最终得分:最后将所有指标得分权重求和。下图以白屏指标为例,简单介绍了一下思路。

前端服务
前端服务是在整体错误监控中负责承上启下的作用。用来完成数据和中台展示的对接,一些功能接口的封装,数据流操作等等。
Go服务
go服务主要功能为连接数据(kafka),写入ck。是我们实时数据通道的重要的一个环节。我们把所有kafka的数据分类经过4个不同的job服务(错误、特殊业务、播放器、性能)分类部署,再对应写入CK的日志中。
在错误通道中,接入了指标(metric),接入指标的好处在只记录数字,大大减少实时计算的压力,这个方面会在APM的告警中详细解释为什么选择指标接入的原因。

go接入kafka写入ck
Node服务
Node更多是提供apm展示更多数据功能的api,包括调用ck日志、聚合信息、获取离线日志、sourceMap解析还原、告警触发通知等等。

现有相关node的api
其中sourceMap的解析还原是比较通用的策略,我们使用的也是业界比较通用的解析工具 `source-map(https://www.npmjs.com/package/source-map)`,其原理我也是看了一些文章应该涉及到VLQ编码的知识(更多有兴趣的朋友可以深究)。常规的使用我更多当成一个黑盒工具去解析即可。

APM源码解析
APM后台
有了收集上报,那一定就会有数据展示分析(可视化)的中台APM(Application Performance Management)。
其实对于中台的核心功能,刚开始做的并不好,在没有设计,产品等等的参与下,我们从0开始写需求目标,画大致的设计稿和功能点。今年上半年APM改造也做了很多内容,我们对错误分析拆成了3个部分做了重写和优化,详细在后面章节介绍。

聚合分析
APM不仅继承了观远已有的字段聚合展示,它还更直观展示了聚合度的百分比、不在需要业务一一去查询。
展示了浏览器、城市、灰度版本号、堆栈文件等类型的集合度标签,还会计算最大日环比,判断是否报错突增、是否出现新错误,如第二行数据。如果上报数据中,至少还有一份js堆栈文件,我们就会展示js文件占比和堆栈文件样例,如第一行数据。

技术难点
列表中展示聚集度需要再统计上报次数的同时,去分别统计浏览器、城市等分布情况,取其最大值返回。
难点有二:
统计上报次数和计算分布情况,必须是同时进行的,不能依赖离线调度任务如何编排SQL,使得同时返回7+聚集度标签。难点一也是观远看板做不到的原因,观远看板加载时如果有大量计算,很容易超时导致失败。开发前,我们调研发现内部One-Service平台支持用户编写SQL将离线表转换成接口,并且百万数据也撑得住,这就很好的帮助我们解决了这个问题。
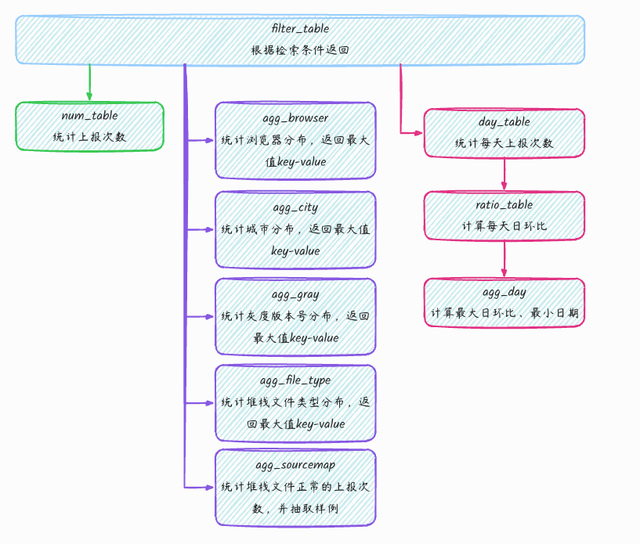
我们在One-Service平台编写的SQL结构如上。其中,浏览器/城市/灰度版本号/堆栈文件类型的SQL类似,以浏览器为例:
SELECT msg, ua_browser_version AS _name, COUNT(*) AS _num, ROW_NUMBER() OVER ( PARTITION BY msg ORDER BY COUNT(*) DESC ) AS row_numFROM t_searchGROUP BY msg, ua_browser_version统Ï计浏览器分布查询
黑产/危险/修复指数



黑产指数:根据堆栈报错文件中js占比、城市聚集度、浏览器聚集度来计算。如行一,黑产指数超过59%,打开堆栈信息,报错文件为空确实异常。
危险指数:根据最大日环比、是否新错误来计算。如行二,打开发现确实是新出现后突增的错误,业务应该加紧排查问题。
修复指数:根据堆栈报错文件中js占比、用户行为日志数量来计算。如行三,点击sourcemap按钮后,可以直接看到报错代码,错误原因该是file没有判空。
一键告警
背景
B站前端原有的告警只有一种称为日志告警,它的特点就是实时计算,根据配置的规则去计算是否符合规则条件,从而触发告警通知。根据详情链接和配置显示的字段分布可以看出大致的原因和详细排查日志。这样来看优缺点比较明显
优点: 实时、规则自定义丰富、日志详情地址清晰
缺点: 生成的规则不停的计算消耗大、过滤规则的配置需要有一定的入门门槛。


日志告警的配置和触发
一键告警就是从日志告警中演变而来的,那么肯定会有疑问,有了日志告警为什么需要做一键告警?
原因大致如下:
job(前端技术实时服务)的日志告警规则配置随着mirror的业务不停增加接入方,实时运算压力超标。更多前端的同学只需要看到自己项目的情况和配比阈值,不需要理解整体配置告警的链路成本,更快的关注业务情况,处理业务异常。常常有黑产的攻击,如何去判断业务是真的有问题还是特定某些聚合度。日志告警触发后不在公司内无法访问链接地址。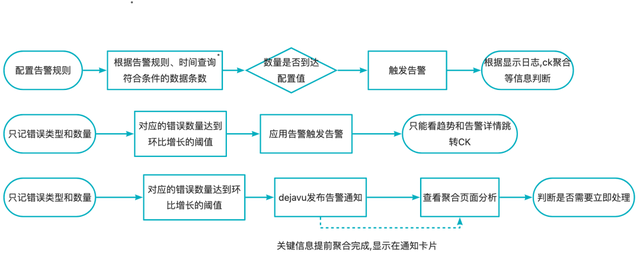
日志告警、应用告警、一键告警
一键告警设置
在告警配置中我们提供了根据项目配置的几种通用类型的告警信息,和24小时内的数据情况,根据环比增长和最小触发值2个选项来确认是否触发告警,让更多前端同学只需要了解自己项目的整体情况去设置对应的数值即可。 前端同学可以不用关心PQL的环比语法,设置固定期望阈值和告警组即可完成告警配置。

一键告警配置、预览
一键告警触达
配置完成对应项目的告警后,我们对接了alarm平台(内部告警平台)的webhook,用node给dejavu(前端统一基建平台)发送告警通知,最后通过企微发送告警详情。

企微告警通知

支持H5、web的查看详情分析预览
这样一键告警的链路大致如下,现有方案的优势为:
保持实时告警的有效性。接入指标后大幅度减少日志运算的计算量。默认的环比+最低个数配置降低了大部分前端配置理解告警的门槛。指标触发后,聚合度分析页面可以观测大致问题的原因,决定是否需要马上跟进。支持web/h5,公司外网等等情况的访问。日志
APM支持的日志在mirror部分已经所有展示分别为离线日志和错误行为日志2个方向。
错误行为日志是根据kv配置,存储堆栈大小(默认10),自动关联错误上报的能力,可以关联错误用户前后的具体操作

离线日志展示,记录用户的全部行为,api请求需要接入统一请求+上报中间件

日志的收集上报在mirror中已经有讲到,在和APM约定好上报解析格式后,对应获取文件的日志从而解析展示,方便一些错误关联或者整体详细日志排查的跟进。后续我们也会针对2种日志和一些错误做出数据上的关联,提升日志的价值。
未来规划
在整体推进错误监控的过程中,时刻感觉到还要走的路很远,我们现阶段以mirror的标准化和推进APM作为主目标来规划后续的几个方向:
持续保持对bili-mirror sdk的优化和更新支持更多适合B站特有业务的迭代。完善健康度分值算法的升级迭代。数据方面不断治理数据的有效性和合理性和准确性。告警通知如何做到更精确和一些无意义告警对于前端开发者的打扰。在整体APM平台功能的迭代升级,后续对于性能模块的深入探索开发等等。更多平台支持的可能性(比如小程序)。总结
最后拿一张整体的结构图来表明我们现有的整体结构。
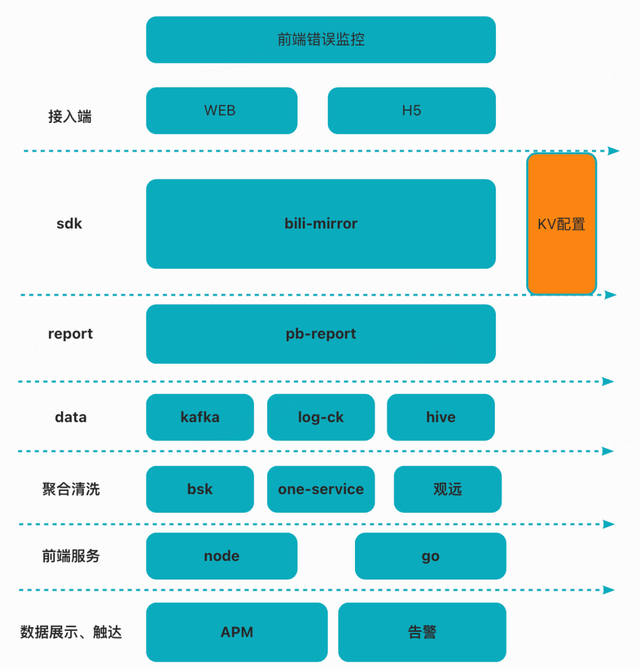
B站前端监控在整体1年多的发展中遇到了很多挑战,总体完成了从0到1的建设。后续我们也会持续关注一些行业经验配合我站业务的特性,持续优化和迭代前端监控中的细节。也希望有经验或者希望交流的行业大佬们互相讨论和学习。
-End-
作者丨于大正正、未央