全文约3000字;
阅读时间:约8分钟;
听完时间:约16分钟;

昨天,我解决了这样一个问题:当多个产品共享同一组件时,直接从库存中扣除总需求量会导致库存量被重复计算,从而产生计算偏差。为了解决这一问题,我调整了算法,确保在计算库存时能准确地处理被多个产品共享的组件。
今天,我将继续优化系统,面对更复杂的挑战。当某个组件被多个产品共享,并且这些产品有不同的需求日期时,我们需要精确计算每天的欠料信息,以实现库存管理的精细化。
例如,在下图所示的情境中,产品1有两个不同的交货日期:7月8日和8月15日。如果我们将所有需求合并计算,那么可能会出现较高的欠料需求,这可能导致某些物料在特定日期前无法满足需求。然而,如果我们按照每个具体日期分别计算欠料情况,我们可能会发现7月8日的物料供应充足,而到了8月15日,则可能出现欠料的情况。通过这样的方式,我们可以更准确地预测和管理库存,避免因需求波动而导致的物料短缺。
 设计思路
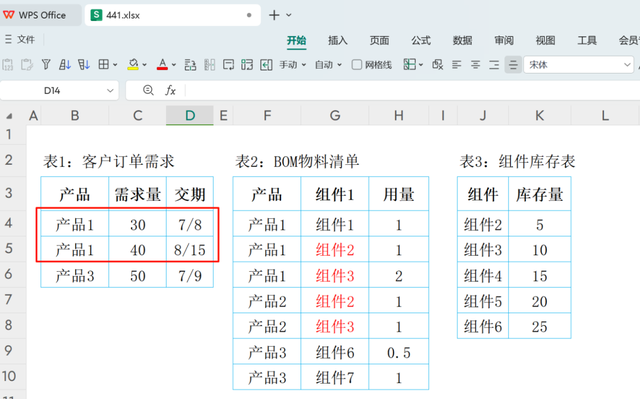
设计思路当前的算法不再适用简单的XLOOKUP函数直接查找和引用,原因在于产品名存在重复——如产品1会多次出现。若直接使用XLOOKUP,只会查找到第一个产品1的相关需求,而忽视后续相同产品的其他需求。因此,要解决这一问题,我们需要采用更为高级的函数组合:REDUCE与FILTER,以实现对物料清单(BOM)的有效分解。
首先,我们将产品明细,如产品1、产品2等,定义为LAMBDA函数的参数Y。接下来,利用REDUCE函数结合FILTER函数,针对每一个具体产品筛选其对应的BOM明细。通过这一系列的堆叠操作,我们能够生成涵盖所有产品——包括多次提及的产品1、产品2等——的完整BOM清单。最后,将这一清单与现有库存数据进行对比,计算累计需求,从而实现按日精确判断是否存在“欠料”情况。这种方法不仅确保了需求计算的准确性,还提高了库存管理的效率和精细度。
 筛选数据
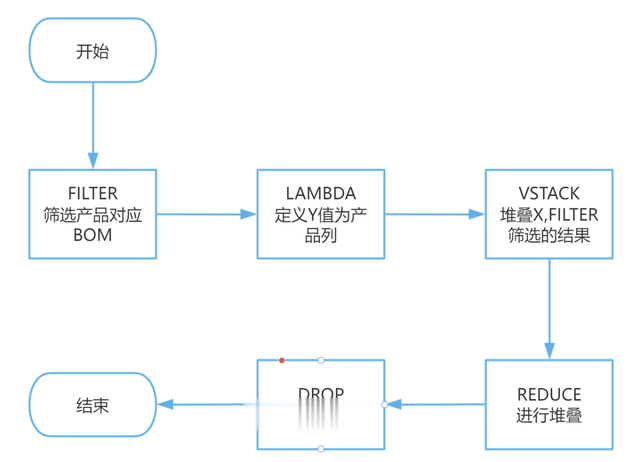
筛选数据在运用REDUCE函数进行堆叠处理之前,至关重要的是要构建出针对参数Y的初始函数结果。这一步骤通常涉及使用FILTER函数来精确筛选出与特定产品相对应的物料清单(BOM)细节。例如,在适当的位置,可以输入如下函数:
=FILTER(F4:H10,F4:F10=B4)
公式解释:
它从范围F4:H10(这是BOM明细所在的区域)中筛选出符合条件的数据行,这里的条件是列F(产品标识列)中的值必须与单元格B4中的产品名相匹配。换句话说,该函数将返回所有BOM条目,这些条目中的产品名与我们在B4单元格中指定的产品名一致。这是确保我们只处理相关产品BOM信息的关键步骤,为后续使用REDUCE函数进行数据汇总奠定了基础。
堆叠数据在通过FILTER函数成功获取了首个Y值(即首个产品的BOM明细)的结果之后,我们只需进一步借助REDUCE、LAMBDA以及VSTACK函数,即可实现不同产品的BOM信息堆叠。最终,为了清理数据,我们还将使用DROP函数移除由REDUCE函数产生的多余空值(通常是其第一参数)。为此,在恰当的位置,可以输入以下动态数组公式:
=DROP(REDUCE("",B4:B6,LAMBDA(X,Y,VSTACK(X,FILTER(F4:H10,F4:F10=Y)))),1)
公式解释:
REDUCE("", B4:B6, LAMBDA(X, Y, VSTACK(X, FILTER(F4:H10, F4:F10 = Y)))) 这部分公式的核心在于使用REDUCE函数遍历产品列表(B4:B6),对每个产品执行相同的操作。对于每一项产品Y,它首先检查X(累积结果)是否为空,然后通过FILTER函数筛选出与当前产品Y相关的BOM明细,再利用VSTACK函数将筛选出的明细追加到累积结果X的下方,从而逐步构建出所有产品的BOM汇总表。
DROP(..., 1) 函数的作用是在最终结果中删除第一行数据,这是因为REDUCE函数在初始化时通常会将一个空值作为起始点,而这会导致汇总结果的第一行为空或包含无关信息。通过DROP函数,我们可以确保最终输出的BOM汇总表干净整洁,没有额外的空白行。
通过上述步骤,我们能够高效地整合所有产品的BOM信息,为后续的库存管理和欠料分析提供精确的数据支持。
零件数量:一旦BOM(物料清单)的需求被确定下来,接下来的步骤便是计算各个组件的具体需求量。这一计算过程实质上是将产品的生产数量与BOM中各组件的使用量相乘。简而言之,产品的每个组件都需根据其在BOM中出现的次数来重复计算需求量。例如,如果产品1的BOM清单中包含3个不同的组件,那么对于每种组件而言,其需求量将等于产品1的生产数量(假设为30个单位)乘以该组件在BOM中的用量。这意味着,如果产品1的计划生产数量为30个,那么对于BOM清单中的每个组件,其需求量都将分别计算为30个单位,进而确保每个组件的总需求量得以准确反映产品生产计划的实际需求。
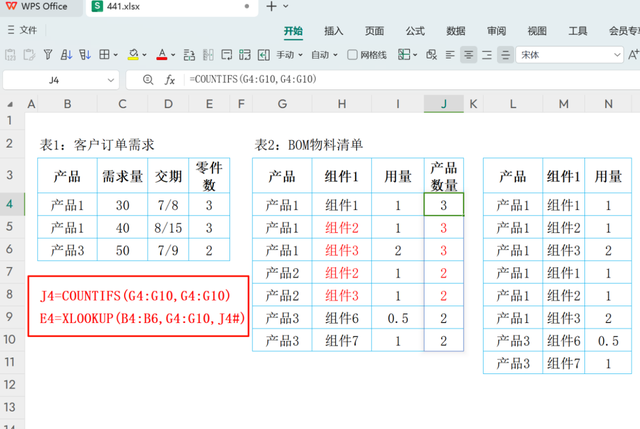
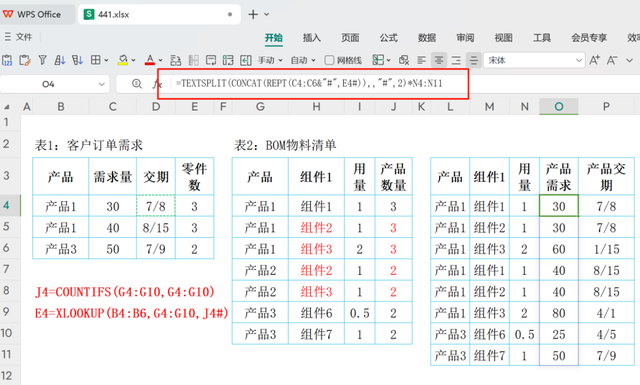
基于上述特性,我们首先需要确定每个产品在BOM(物料清单)中的出现次数,以便于后续计算每个组件的具体需求量。为此,可以在BOM表格的邻近区域输入以下公式,用于计算与特定产品相对应的BOM数量: J4=COUNTIFS(G4:G10,G4:G10)
此公式将统计G4单元格所在行的值在整个G4:G10区间内出现的次数,从而得出该产品在BOM中的重复次数。
随后,在产品需求列的旁边新增一列,用于引用BOM中的组件数量。在该列的相应单元格(例如E4)输入以下公式:
E4=XLOOKUP(B4:B6,G4:G10,J4#)
以下公式的解释如下:
XLOOKUP(B4:B6, G4:G10, J4#) 这一公式的作用是,从B4:B6(产品列表)中查找与G4:G10(BOM产品列)相匹配的产品名称,然后返回该产品在J列(即通过COUNTIFS计算得到的BOM重复次数列)中的对应值。J4#表示的是J列中从J4开始的整个数据列,确保XLOOKUP函数能正确引用所有相关的重复次数数据。
通过上述步骤,我们不仅能够统计每个产品在BOM中的出现次数,还能将这些信息与产品需求有效关联,为后续计算每个组件的总需求量奠定坚实的基础。这一流程确保了需求计算的准确性和效率,有助于企业更好地规划生产和库存管理。
 需求交期
需求交期有了零件数,就可以根据这个数量来重复了,在合适位置录入以下公式得到产品分解后的产品对应的组件需求用量:
=TEXTSPLIT(CONCAT(REPT(C4:C6&"#",E4#)),,"#",1)*N4:N11
公式解释:
REPT(C4:C6 & "#", E4#) 这部分函数的作用是,将C列(组件列表)中的每个组件名称与其后添加的分隔符(此处为"#")重复E列(组件需求次数)中对应次数。这样做的目的是创建一个字符串序列,其中每个组件名称根据其需求次数被重复列出。
CONCAT(...) 函数则将上述生成的字符串序列合并成一个单一的长字符串。
TEXTSPLIT(..., "#", 2) 函数用于将上述长字符串分割成单独的组件名称,其中"#"作为行分隔符,1表示忽略空单元格。
最后,将得到的组件名称列表与N列(产品数量)进行乘法运算,从而计算出每个组件的总需求量。
公式解释:
对于产品的交期计算,逻辑上与此相似,只是引用的区域需变更为日期列,公式可相应调整为:
=TEXTSPLIT(CONCAT(REPT(D4:D6&"#",E4#)),,"#",1)*N4:N11
到了这一步,我们已经构建起了计算物料短缺所需的基础数据框架。鉴于当前采用的算法与先前一天所用的逻辑大体相同——即通过参照现有库存,并从中扣除累积需求量来确定——因此,仅需对涉及的数据公式进行细微调整。这些改动旨在确保计算过程能够准确反映最新的库存状态与需求变化。由于调整幅度不大,且遵循既定的计算原则,故在此不再赘述具体修改细节。
简而言之,通过沿用并微调原有的算法,我们可以高效地更新物料短缺情况,为后续的库存管理和采购决策提供及时且准确的支持。
最后总结综上所述,面对多产品共享组件及需求日期差异带来的复杂性,我们采取了一系列策略以提升库存管理的精准度。从解决物料清单(BOM)中产品名重复导致的计算偏差入手,我们引入了REDUCE与FILTER函数组合,有效实现了对各产品BOM明细的精确筛选与堆叠,确保了需求计算的准确性。此外,通过细化需求交期,我们能够按日评估欠料状况,避免了因合并计算造成的潜在物料短缺风险。
关键步骤包括:首先,运用FILTER函数精确提取单个产品的BOM信息;其次,借助REDUCE与VSTACK函数,完成多产品BOM数据的高效堆叠,确保全面覆盖所有需求;接着,通过XLOOKUP与COUNTIFS函数,准确计算各组件需求量,为精确库存管理打下基础;最后,运用TEXTSPLIT与REPT函数,结合产品数量和交期,精确计算每个组件的总需求量,确保供应链顺畅运行。