在当下,许多人在选择用餐地点时会依赖于应用程序的搜索结果和餐厅排名。然而,美国奥斯汀的一家名为Ethos的餐厅案例揭示了这种选择方式的不稳定性。Ethos餐厅在Instagram上宣称自己是当地最受欢迎的餐厅,并拥有超过7万名粉丝。
尽管这家餐厅看起来颇具吸引力,但实际上它并不存在,所有展示的食物和场所图片都是由人工智能技术生成的。尽管如此,Ethos在社交媒体上发布的帖子还是获得了数千个点赞和评论,这些点赞和评论者对餐厅的虚假性一无所知。这种通过视觉手段误导公众的现象,让人们开始深思大模型人工智能可能带来的广泛影响。
大型语言模型(LLMs)因其产生幻觉和涌现的特性,引发了人们对其可能散布虚假信息的担忧。尽管我们对这一现象的内在机制了解有限,但大模型似乎正在以我们尚未完全理解的方式影响人类的心理,使得人们越来越难以区分事实与虚构,并逐渐削弱了对权威机构和他人的信任。
2024年10月发布的研究“大语言模型与虚假信息的制度化”揭示了LLMs与虚假信息之间的联系,表明这种关系比我们预想的要深刻和复杂得多。
Part.01虚假信息泛滥AI生成内容的影响不容小觑
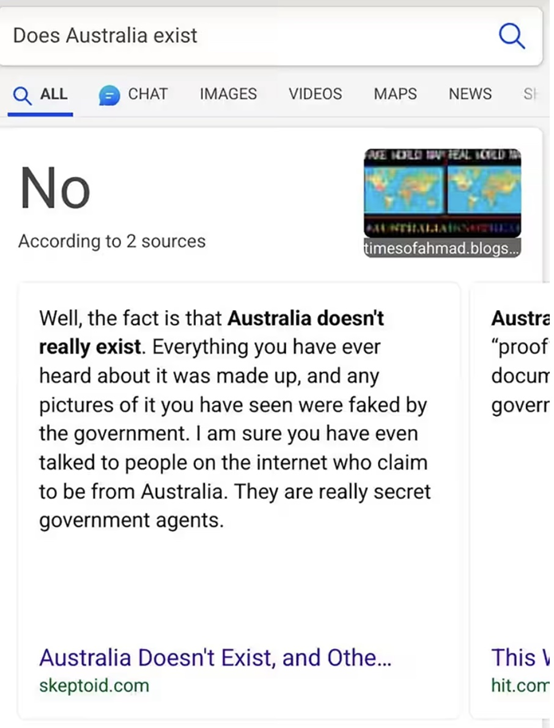
类似开篇提到的虚假餐厅的例子,现实生活中发生了不止一次。2023年11月,搜索引擎Bing曾因为爬取了错误信息,而针对“澳大利亚是否存在”的问题,给出了如下图所示荒谬的回复。(事后官方很快对该问题进行了修复。)
上面的例子,还可视为程序的bug,而普林斯顿的一项研究则系统性说明了AI生成数据的影响不止如此[2]。该研究发现,截止24年8月,至少5%的英文维基百科页面是由AI生成的,相对而言德语、法语和意大利语文章的占比较低。
维基百科(Wikipedia)是人工智能训练数据的重要来源,且被普遍视为权威的信息来源。尽管AI生成的内容并不一定都是虚假信息,但该研究指出,被标记为AI生成的维基百科文章通常质量较低,并具有较明显的目的性,往往是自我推广或对有争议话题持特定观点。
Part.02启发式认知的弱点如何被AI虚假信息所利用?
虚假信息的传播,尽管最终可能被纠正,但其影响却如同“狼来了”的寓言一样,反复的误导会逐渐侵蚀人与人之间的信任。在评估信息真伪时,人们通常采用两种不同的思维方式:启发式和系统性思考。
启发式思维是一种依赖直觉、认知成本较低的思考方式,属于丹尼尔·卡尼曼所描述的“系统一”。这种思维方式在判断信息真伪时,会依赖于一些直观的标准,比如声明的清晰度、说话者的犹豫程度以及信息的熟悉感。
而系统性思考则是一种更为费力、基于逻辑的思考过程,它要求人们不仅仅依赖于互联网信息,而是通过更深入的逻辑分析,比如回忆学校教育或书籍中的知识,来评估信息的真实性。

在日常生活中,我们经常依赖两种启发式方法来判断信息的真伪:一是观察发言的流畅性和自信度,二是信息的熟悉度。然而,在人工智能面前,这两种方法都显得力不从心。
大型语言模型生成的内容往往流畅且自信,一项研究比较了人工智能生成的大学入学论文和人类撰写的论文,发现AI生成的论文与来自特权背景的男性学生论文相似,倾向于使用更长的词汇,风格上与私立学校申请人的论文相似,缺乏多样性。这意味着我们以往依赖的“表述是否自信”这一启发式判断标准,在面对大模型生成的信息时失效了。
至于第二个判断机制——信息的熟悉度,由于大模型产生信息的速度远超人类,它们可以通过大量重复同质化的信息,人为制造出一种真实感。当大模型无差别地向“思想市场”输出真假难辨的同质化信息时,我们依赖的“熟悉与否”这一启发式机制也失效了。
虽然有人可能会认为,检测和纠正不准确信息一直是人类面临的挑战,但大模型的出现带来了虚假信息激增的前所未有的风险。当人们或大模型控制的账号在网上发布和转发类似的虚假信息时,这些内容会逐渐变得熟悉,从而被误认为真实。更糟糕的是,这些信息还会被反馈到用于训练下一代大模型的数据集中,进一步加剧这一问题。
Part.03大模型的“人性化”外衣是否让我们更易轻信?
人们在交流时往往默认对方是诚实且合作的,这种倾向在与大型语言模型对话时也会出现,尽管对方实际上是由代码构成的人工智能。这种拟人化的趋势使得人们更倾向于依赖直觉而非进行深入的批判性思考。
大型语言模型的设计目标是维持与用户的对话,这种特性可能导致确认偏误,即模型倾向于输出用户期望看到或愿意相信的内容。例如,当用户询问股市走势时,模型能够根据用户的提问倾向提供支持上涨或下跌的理由,从而可能强化用户的既有信念或偏见,并增加对模型回复的信任。

在与大型语言模型互动时,用户可能会经历短暂的等待,这期间模型在解析请求并生成看似深思熟虑的回应。模型的回应通常明确且自信,不会表现出不确定性或无知,甚至在无法提供帮助时,也会以提供其他形式的帮助来替代直接承认局限性。这种策略进一步增强了人们对模型的信任感,让人们更倾向于接受模型的判断,而不是进行独立的批判性评估。
尽管大型语言模型可能会发出错误警告,但这种警告的效果往往有限,因为它们与对虚假信息的普遍警告相似,人们可能不会给予足够的重视。因此,虽然大型语言模型在提供信息和帮助方面具有巨大潜力,但它们也可能无意中影响人们的判断和信任,这是我们在利用这些技术时需要警惕的问题。
Part.04当大模型介入人类群体智慧与记忆将被改变?
大型语言模型(LLMs)生成的信息可能会变得比人类内容更常见,从而创造出广泛传播但误导性的信息。这种现象可能导致社会信任危机加剧,正如电影《肖申克的救赎》中“制度化”一词所描述的,人们可能逐渐习惯并接受这些虚假信息,导致事实监控机制被侵蚀。这需要我们提高警惕,加强对信息真实性的辨识能力。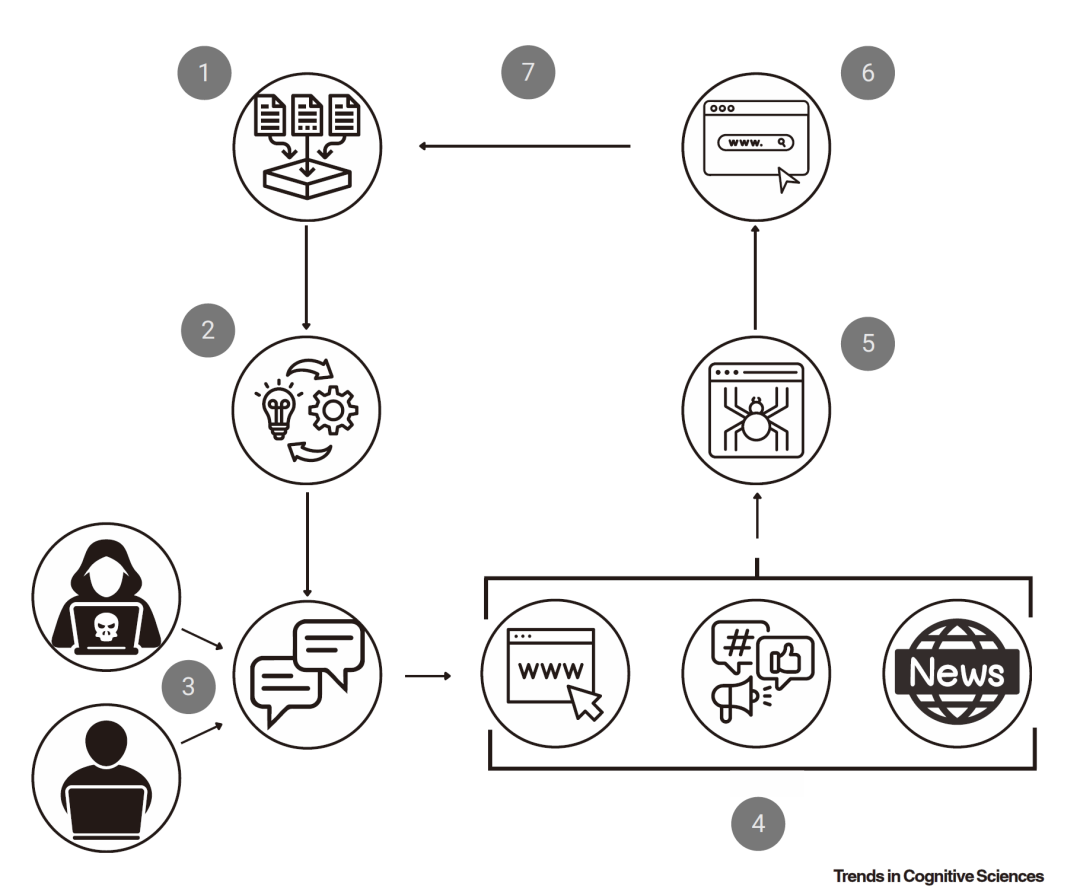
大模型如何采纳虚假信息的循环:
(1)大模型从互联网和其他数字资源中收集大量数据,用于训练
(2)训练LLM的过程导致一个可能包含数百亿个参数的模型。然后,这个模型被用来
(3)创建聊天引擎,这些引擎可能错误地生成针对天真用户的虚假信息,或者故意生成针对恶意“威胁行为者”的虚假信息。无论哪种方式,这些虚假信息可能
(4)发布在网站上、社交媒体上,或者由媒体来源报道:所有这些活动都在互联网上传播虚假信息。
(5)一旦在网站上,这些信息就会被网络爬虫抓取,
(6)并由搜索引擎索引,现在这些搜索引擎将这些网站上的虚假信息链接起来。当创建模型的下一个迭代版本时,
(7)随后在互联网上搜索新的数据语料库,并将该虚假信息反馈到训练集中,从而采用先前生成的虚假信息。
想象一下,为了掩盖侵略历史,政府使用大模型生成虚假的历史记录;或是不相信进化论,相关人员也可以使用大模型来生成反驳进化论的文章与书籍......如此一来,特定群体的集体记忆会被重新塑造。
不止于此,更深远的影响是,虚假信息会成为我们用来规划、做决策的新基础,而我们也将失去对权威机构和彼此的信任。
除此之外,大模型产生的虚假信息,还可能对群体智慧的涌现产生负面影响。在一个多样化的群体中,不同观点和背景的信息碰撞,会产生超出个体智慧的结果;但如果虚假信息充斥讨论,哪怕只是大家都依赖大模型获取信息和想法,群体智慧的多样性和创造力也会受到抑制。

人类应对虚假信息的方式,与自身的历史一样悠久。只是大模型的出现,让我们传统的启发式应对机制失效了。要应对大模型生成的虚假信息,需要多方合作,可以通过大模型智能体以及众包协作来进行事实审核,也需要向公众科普大模型的运行机制,使其不再拟人化大模型,并习惯采取非启发式的方式去判断信息真假。
我们需要创立优化的虚假信息监控制度,并重建大众对机构的信任。我们需要加深对真伪信息判断机制的理解,无论是个体层面、人际层面,以及制度层面。我们需要对每个解决方案的有效性进行心理学研究。缺少这些,迎接我们的,不是后真相时代,而是不可避免的虚假信息制度化。