在数字化时代,我们经常需要在大量的文档中快速找到所需的信息。尤其是 PDF 格式的文档,因其广泛的应用和良好的兼容性,成为了许多专业人士的首选。然而,PDF 文档的搜索功能往往不如文本文件直观和高效。这时,pdfgrep 这个命令行工具就显得尤为重要。
 什么是 pdfgrep?
什么是 pdfgrep?pdfgrep 是一个开源的命令行工具,它允许用户在 PDF 文件中搜索文本。它不仅支持基本的文本搜索,还提供了许多高级功能,如正则表达式匹配、多文件搜索、彩色高亮显示等。
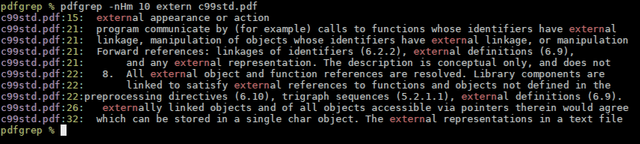 pdfgrep 的特点1. 与 GNU Grep 兼容
pdfgrep 的特点1. 与 GNU Grep 兼容pdfgrep 试图与 GNU Grep 保持兼容,这意味着许多在 Grep 中常用的选项,如递归搜索(-r)、忽略大小写(-i)、显示行号(-n)和计数匹配行数(-c)等,在pdfgrep中同样适用。
2. 多文件搜索如果你忘记了信息存储在哪个 PDF 文件中,pdfgrep允许你同时搜索多个 PDF 文件,只需指定搜索的关键词,它会自动遍历所有文件。
3. 彩色高亮显示pdfgrep 支持 GNU Grep 的--color选项,并且默认启用。这使得搜索结果中的匹配文本以彩色显示,便于用户快速定位。
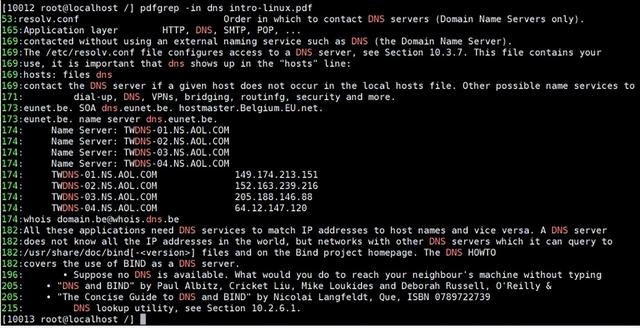 4. 正则表达式支持
4. 正则表达式支持pdfgrep 支持使用正则表达式进行搜索,包括 POSIX 和 Perl 兼容的正则表达式(PCRE),这为用户提供了强大的搜索能力。
5. 免费软件pdfgrep 是自由软件,根据 GPL 版本 2 或更高版本授权,这意味着你可以自由地使用、修改和分发它。
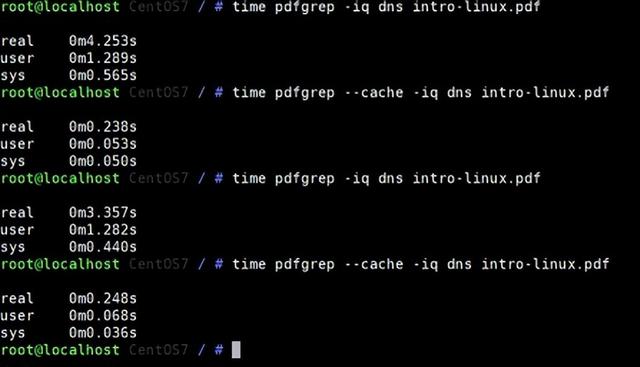 pdfgrep 的安装
pdfgrep 的安装pdfgrep 可以在多种操作系统上运行,包括 Linux、macOS 和 Windows。具体的安装方法会根据操作系统的不同而有所差异。通常,你可以使用包管理器来安装pdfgrep,例如在 Ubuntu 上,你可以使用以下命令:
sudo apt-get install pdfgrep在 macOS 上,你可以使用 Homebrew:
brew install pdfgrep在 Windows 上,你可以下载预编译的二进制文件或者使用 Cygwin 等工具。
pdfgrep 的基本用法搜索单个 PDF 文件要搜索单个 PDF 文件中的文本,你可以使用以下命令:
pdfgrep "搜索词" 文件名.pdf这将列出所有包含“搜索词”的行。
搜索多个 PDF 文件如果你不确定信息在哪个文件中,可以使用以下命令搜索一个目录下的所有 PDF 文件:
pdfgrep -r "搜索词" 目录/使用正则表达式pdfgrep 支持使用正则表达式进行更复杂的搜索。例如,如果你想搜索以“example”开头的行,可以使用:
pdfgrep "^example" 文件名.pdf忽略大小写如果你的搜索不区分大小写,可以添加-i 选项:
pdfgrep -i "搜索词" 文件名.pdf显示行号要显示匹配行的行号,可以使用-n 选项:
pdfgrep -n "搜索词" 文件名.pdf彩色高亮显示默认情况下,pdfgrep 会以彩色显示匹配的文本。如果你的终端不支持彩色或你想要关闭这个功能,可以使用--color=never 选项:
pdfgrep --color=never "搜索词" 文件名.pdf计数匹配行数如果你只想知道匹配的数量,可以使用-c 选项:
pdfgrep -c "搜索词" 文件名.pdf总结pdfgrep 是一个功能强大且灵活的 PDF 文本搜索工具。它不仅能够满足基本的搜索需求,还提供了丰富的选项来适应各种复杂的搜索场景。无论你是开发者、研究人员还是普通用户,pdfgrep 都能成为你日常工作中的得力助手。通过掌握 pdfgrep 的使用方法,你将能够更高效地处理和分析 PDF 文档中的数据。