
阿里妹导读
文章介绍了如何通过抽象语法树(AST)技术自动化地解决前端代码治理中的具体问题,特别是针对大量存在的未使用变量或函数参数等问题。
背景
在治理 CPO 项目代码 Block 和 Major 问题的背景下,需要通过工具来提高治理效率,那么如何才能精确的调整代码呢,这时候自然而然的就会想到 AST ,可以通过 AST 对代码进行相关调整,从而解决相应的问题。
注:本文代码示例都是基于 JavaScript 语言。
浅析 AST
何为 AST
抽象语法树(Abstract Syntax Tree,AST),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。

(图片源自网络)
AST 有什么用
前端开发同学在日常使用 JavaScript 中,虽然在编写代码的过程中很少会和 AST 直接打交道,但很多的工程化工具都会和它有关,比如 babel 对代码进行转换、eslint 校验、ts类型检查、编辑器语法高亮等,这些工具操作的对象,其实就是 JavaScript 的抽象语法树。
通常我们在实际使用 AST 的工作过程中,会经过三个阶段:
解析(Parse):将源代码转换为 AST。转换(Transform):通过各种插件对 AST 进行修饰(调整)。生成(Generate):利用代码生成工具,将修饰后的 AST 转换成代码。
(图片源自网络)
即通过将代码片段转换成 AST 以后,进行指定的结构处理,最后再将修饰后的 AST 转成代码,从而达到修改代码的效果。
AST 结构
可以通过 AST Explorer 查看code代码的抽象语法树结构,推荐使用 @babel/parse 解析器,可以和本文示例保持一致。
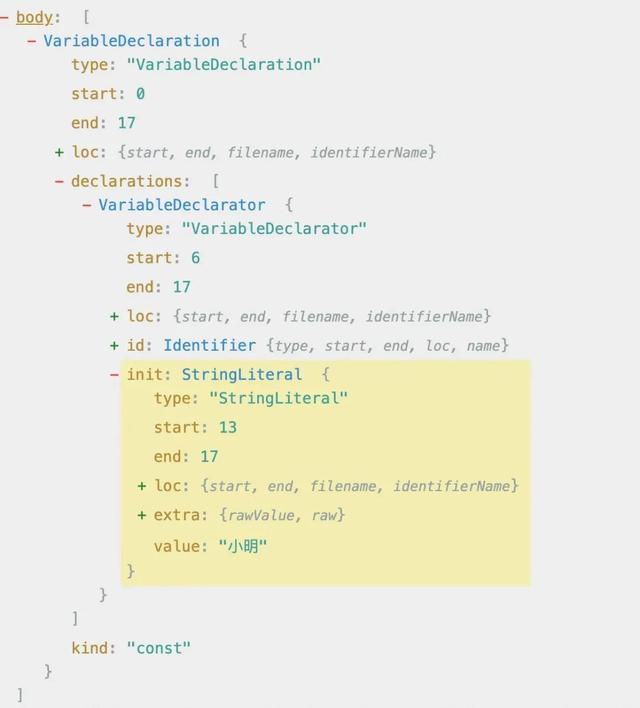
我们看一个简单的示例:
const name = '小明'经过转换,输出的 AST树状结构如下:
{ "type": "Program", "start": 0, "end": 17, "loc": { "start": { "line": 1, "column": 0, "index": 0 }, "end": { "line": 1, "column": 17, "index": 17 } }, "sourceType": "module", "interpreter": null, "body": [ { "type": "VariableDeclaration", "start": 0, "end": 17, "loc": { "start": { "line": 1, "column": 0, "index": 0 }, "end": { "line": 1, "column": 17, "index": 17 } }, "declarations": [ { "type": "VariableDeclarator", "start": 6, "end": 17, "loc": { "start": { "line": 1, "column": 6, "index": 6 }, "end": { "line": 1, "column": 17, "index": 17 } }, "id": { "type": "Identifier", "start": 6, "end": 10, "loc": { "start": { "line": 1, "column": 6, "index": 6 }, "end": { "line": 1, "column": 10, "index": 10 }, "identifierName": "name" }, "name": "name" }, "init": { "type": "StringLiteral", "start": 13, "end": 17, "loc": { "start": { "line": 1, "column": 13, "index": 13 }, "end": { "line": 1, "column": 17, "index": 17 } }, "extra": { "rawValue": "小明", "raw": "'小明'" }, "value": "小明" } } ], "kind": "const" } ], "directives": [] }可以发现 AST 这种数据结构其实就是一个大的 JSON 对象,每一个节点都有对应的 type 类型等关键信息。
AST 生成过程
JS 的抽象语法树的生成主要依靠的是 Javascript 解析器,整个解析过程分为两个阶段:
 词法分析
词法分析词法分析,也可以叫分词,是将字符序列转换为一个个单词(Token)序列的过程,这里的单词可以理解成自然语言中的词语,在语法解析中是具备实际意义的最小单元,也叫做语法单元。
Javascript 代码中的语法单元主要包括以下这么几种:
关键字:例如 var、let、const等;标识符:没有被引号括起来的连续字符,可能是一个变量,也可能是 if、else 这些关键字,又或者是 true、false 这些内置常量;运算符: +、-、 *、/ 等;数字:像十六进制,十进制,八进制以及科学表达式等语法;字符串:因为对计算机而言,字符串的内容会参与计算或显示;空格:连续的空格,换行,缩进等;注释:行注释或块注释都是一个不可拆分的最小语法单元;其他:大括号、小括号、分号、冒号等;分词示例:
// JavaScript 源代码const name = '小明'// 分词后的结果[ { value: 'const', type:'identifier' }, { value:' ', type:'whitespace' }, { value: 'name', type:'identifier' }, { value:' ', type:'whitespace' }, { value: '=', type:'operator' }, { value:' ', type:'whitespace' }, { value: '小明', type:'string' },]可以看到,分词器将代码片段按照语法单元拆分成了一组 Token 序列,这就完成了转换 ast 的第一步。当然,说起来比较简单,但实际编写分词器时,还是要考虑很多情况的,并且还要根据语言特性进行各种处理。
语法分析语法分析的任务是在词法分析的基础上将单词序列组合成语法树,通过语法分析,最终输出 AST。
如下就是通过语法分析器处理,最终得到的包含逻辑关系的 AST 语法树。(仅截取关键部分)
AST 修饰以及生成代码
既然AST是一个 JSON 树,只需要对其进行遍历,并且对其中的节点进行相关属性的修改,就可以达到修改 AST 的目的。最后根据修改后的 AST 进行代码生成即可。
AST 应用—代码 eslint 问题修复
问题治理方案
Aone 扫描的 Web 前端代码质量问题,是根据 eslint 规则进行的问题扫描统计。
所以我们的目标也很明确,以较低的成本解决掉相关问题。
我们以 @ali/no-unused-vars 规则扫描出的问题为例。
规则解释:未使用的变量名、函数参数等。项目情况:该类型问题1200+。解决目标:删除对应变量名。思考:这个类型问题的数量,手动修改显然是不现实的,于是计划通过工具实现。提问:为什么要自己开发逻辑,而不用eslint的自动修复呢?首先,vscode中,eslint 的此类修复规则需要手动触发并且依赖 eslint 插件。其次,像 @ali/no-unused-vars 规则并没有提供修复方法。技术方案:执行 npx eslint --format json 将校验规则转为 json 并筛选出该类型的问题。通过@babel/parser,将相应文件的代码转成 ast 抽象语法树。遍历 ast 节点并与 eslint 的输出结果匹配,如果命中,则进行树节点的删除操作。将调整后的 ast 转为代码,并替换原文件内容。举个栗子
我们现在先解决一个比较简单的问题场景:
// 一个普普通通的变量定义语句const name = '小明'假设此时 name 是未被使用的变量,eslint 校验时会有如下提示:

按照我们前面确定的技术方案:
1️⃣ 通过npx eslint --format json 获取到 eslint 的校验结果,结果中包括了问题代码的 line,startColumn,endColumn,此时就可以获取到出问题的变量名。
2️⃣ 获取整个文件内容,并交给 @babel/parse 进行 ast 解析,得到 ast 语法树。
import * as babelParser from '@babel/parser';const EXAMPLE_CODE = 'const name = "小明"'// 解析源代码function babelParse (code) { const ast = babelParser.parse(code, { sourceType: 'module', plugins: ['jsx', 'typescript'], }); return ast}const astResult = babelParse(EXAMPLE_CODE)console.log(astResult)/**{ "type": "Program", "start": 0, "end": 17, "loc": { "start": { "line": 1, "column": 0, "index": 0 }, "end": { "line": 1, "column": 17, "index": 17 } }, "sourceType": "module", "interpreter": null, "body": [ { "type": "VariableDeclaration", "start": 0, "end": 17, "loc": { "start": { "line": 1, "column": 0, "index": 0 }, "end": { "line": 1, "column": 17, "index": 17 } }, "declarations": [ { "type": "VariableDeclarator", "start": 6, "end": 17, "loc": { "start": { "line": 1, "column": 6, "index": 6 }, "end": { "line": 1, "column": 17, "index": 17 } }, "id": { "type": "Identifier", "start": 6, "end": 10, "loc": { "start": { "line": 1, "column": 6, "index": 6 }, "end": { "line": 1, "column": 10, "index": 10 }, "identifierName": "name" }, "name": "name" }, "init": { "type": "StringLiteral", "start": 13, "end": 17, "loc": { "start": { "line": 1, "column": 13, "index": 13 }, "end": { "line": 1, "column": 17, "index": 17 } }, "value": "小明" } } ], "kind": "const" } ],} */3️⃣ 使用 @babel/traverse 对语法树进行遍历。
traverse 可以遍历 parse 生成的 ast,并通过第二个入参中定义的属性,遍历指定的节点类型,并用handleVariableType方法对节点进行修饰处理。
import traverse from '@babel/traverse';traverse(astResult, { VariableDeclaration(path) { // 这里代表处理type为VariableDeclaration的节点 // 这里就可以对节点进行处理了 handleVariableType(path) }})我们再看一下代码对应的 ast 结构,其中 declarations 数组代表当前节点定义的变量,数组中每个元素代表一个定义的变量节点,该节点带有 id 属性,其中包含了变量名的相关信息。我们可以用 id.name 和 eslint 输出结果中获取到的变量名对比,如果相同,则继续对比代码位置信息。每个节点都有 loc 属性,代表了当前节点的位置信息,通过该属性的位置信息可以定位是否是指定的变量。
匹配成功后,可以通过:
node.declarations.splice(index, 1) 删除当前变量。
最后判断如果 node.declarations.length === 0 ,即不存在声明的变量时,删除整个语句 path.remove()。
根据以上逻辑,补充处理代码:
// 假设待删除的变量名为text,行号为line,起始列startColumn,终止列endColumnfunction handleVariableType(path) { const { node } = path node.declarations.forEach((decl, index) => { if (decl.id.name === text) { if (decl.loc.start.line === line && decl.loc.end.line === line && decl.id.loc.start.column === startColumn && decl.id.loc.end.column === endColumn) { node.declarations.splice(index, 1); } } }); // 如果声明列表为空,则移除整个声明语句 if (node.declarations.length === 0) { path.remove(); }}通过以上的处理逻辑,就可以把对应的整个变量声明语句删除了。
特殊情况
那么是不是所有未使用的变量声明语句都可以删除呢?
看下面的例子:
const timer = setTimeout(() => { console.log('a');}, 1000);变量 timer 未被使用,但显然不能直接将整个语句删除,因为复制语句的右侧是一个定时器函数的返回值,而定时器中必然会有其他逻辑执行,删除后会影响到业务逻辑,所以我们需要将这种情况排除。
我们看下这段代码对应的 ast。(仅截取关键部分)

可以看到 VariableDeclarator 节点中,init 节点代表的是赋值语句右侧的表达式,其中 type 为 CallExpression(可以与前面的示例对比,type 的值是 StringLiteral),可以理解为函数执行的返回值。因此,我们只需要在处理方法 handleVariableType 中判断,如果init 的节点是该类型,则不进行删除,需要人工确认处理方案。
// 假设待删除的变量名为text,行号为line,起始列startColumn,终止列endColumnfunction handleVariableType(path) { const { node } = path node.declarations.forEach((decl, index) => { if (decl.id.name === text) { if (decl.loc.start.line === line && decl.loc.end.line === line && decl.id.loc.start.column === startColumn && decl.id.loc.end.column === endColumn) { if (decl.init?.type === 'CallExpression') { // 补充的判断逻辑 // 执行函数的返回值不能删除, 用户自己判断 } else { node.declarations.splice(index, 1); } } } }); // 如果声明列表为空,则移除整个声明语句 if (node.declarations.length === 0) { path.remove(); }}修饰完以后,使用 @babel/generator 将 ast 再转换成代码片段并替换源代码。
import generate from '@babel/generator';// 将修改后的AST转换回代码字符串const finalCode = generate(astResult, { retainLines: true }).code;以上就利用 ast 解决了一种简单场景的未使用变量的问题。
补充说明
当然,以上只是其中一种情况,仅 @ali/no-unused-vars 这一项规则,就会有很多种情况,需要进行总结归类,然后再进行问题的解决。
以下是部分场景的代码示例,随着治理项目的增加,可能还会有更多未考虑到的场景,需要逐个适配处理逻辑。
// 变量// 删除整行表达式const xxx =// 删除结构出来的指定变量const { xxx } =const { xxx: abc } =const { xxx = [] } =const [a ,b] =// 函数// 删除函数本体function a() {}// 删除入参nfunction a(m, n) { console.log(m)}// 解构, 删除参数nfunction a({m,n}) { console.log(m)}// ❗️以下示例不能删,判断逻辑:当前变量如果是由方法执行返回的const a = setTimeout(() => { console.log('a');}, 1000);const b = arr.map((item) => { console.log(item);});最后
当逐渐掌握 ast 以后,会加深自己对语言底层的理解,也能探索出更多的代码玩法,例如定义一种新的语法糖、多种语言互转等等,这些都是非常酷的事情。