在当今信息爆炸的时代,数据成为了一种宝贵的资源。Flyscrape,一个现代的网络爬虫工具包,提供了一种快速、简便的方式来构建自定义的网络爬虫。
 什么是 Flyscrape?
什么是 Flyscrape?Flyscrape 是一个独立的网络爬虫工具,具有以下特点:
无需编程语言环境:不需要 Node.js 或 Python 环境。浏览器/JavaScript 渲染:内置浏览器模式,可以渲染 JavaScript。访问个人浏览器 Cookies:能够访问用户浏览器的 Cookies,简化登录网站的抓取。精确的请求控制:允许用户控制请求处理速度和链接跟踪等。强大的数据提取能力:利用 JavaScript 定义从网站抓取的确切数据。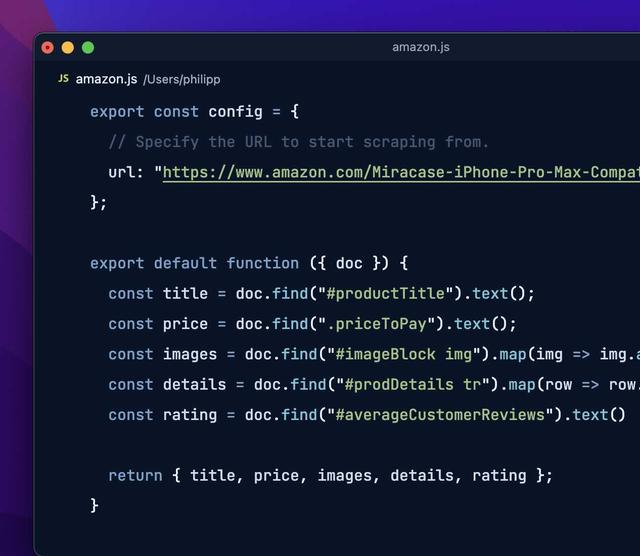 如何使用 Flyscrape?
如何使用 Flyscrape?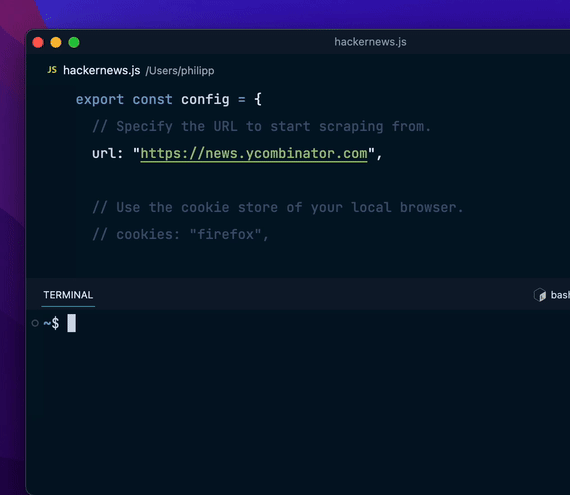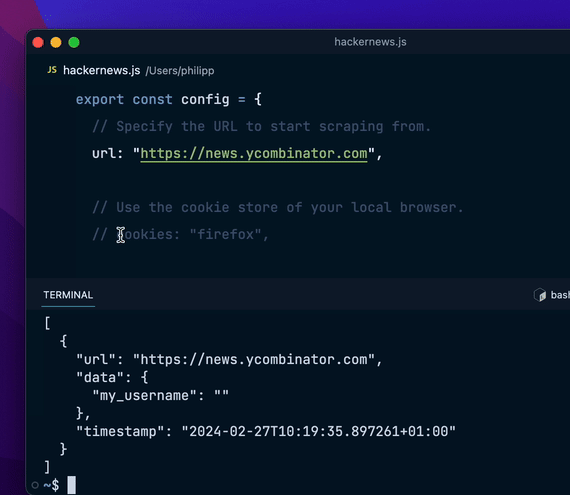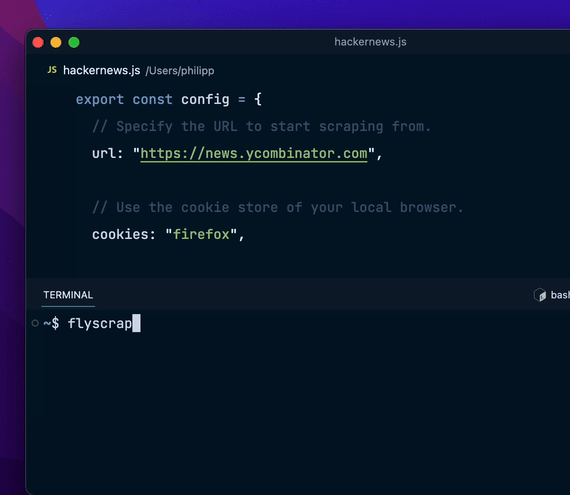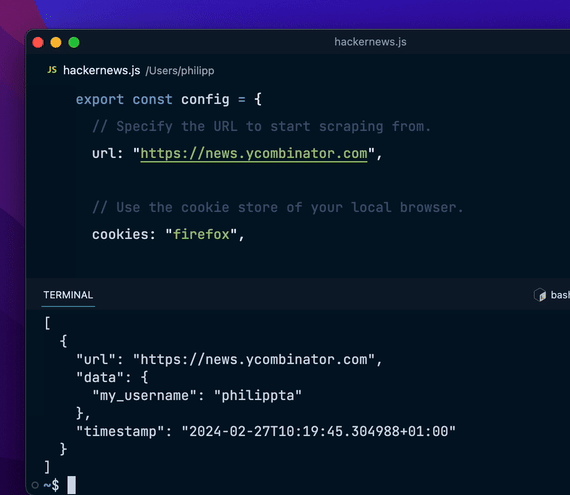 安装 Flyscrape
安装 Flyscrape在 Mac、Linux 或 WSL 上,通过以下命令安装 Flyscrape:
curl -fsSL https://flyscrape.com/install | bash创建抓取脚本使用 new 命令创建一个新的抓取脚本:
flyscrape new hackernews.js配置抓取脚本在脚本中定义抓取的配置:
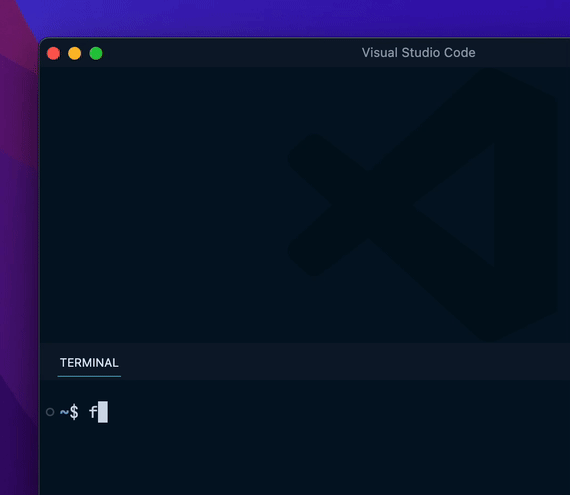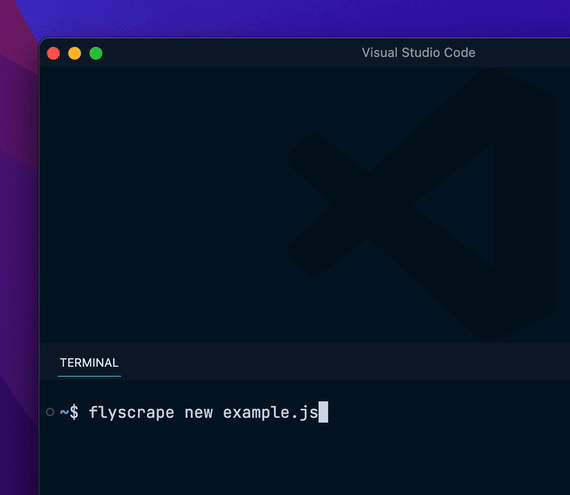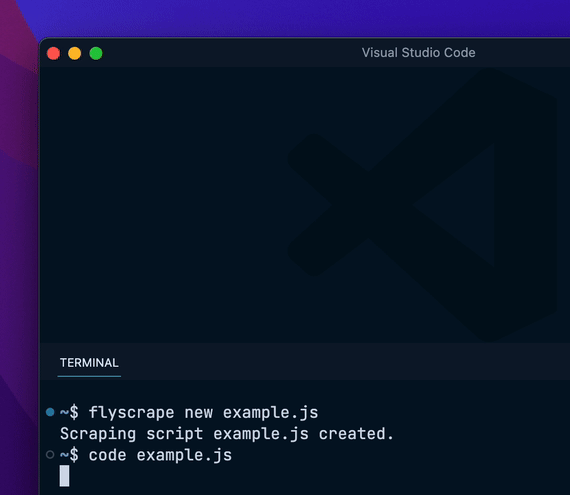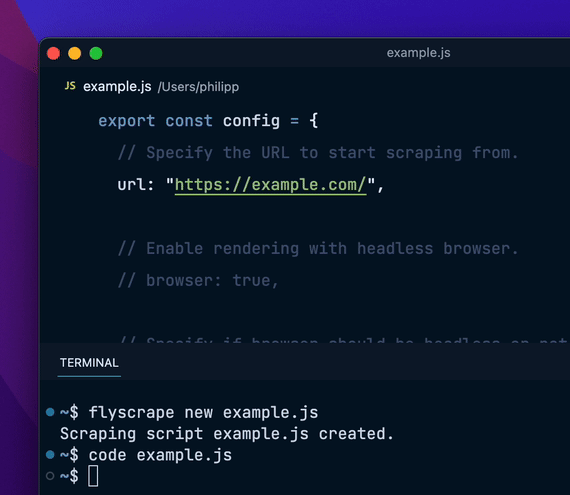
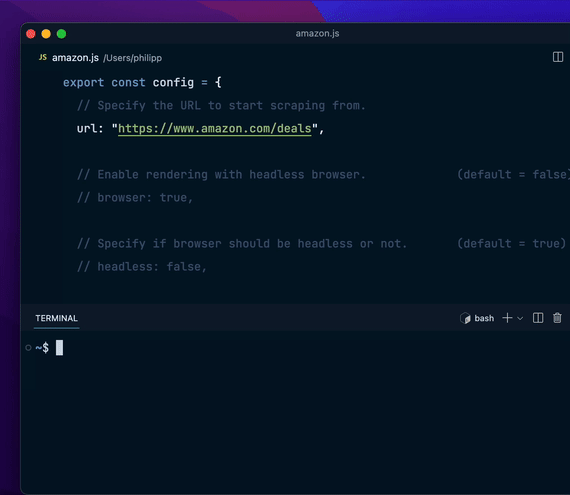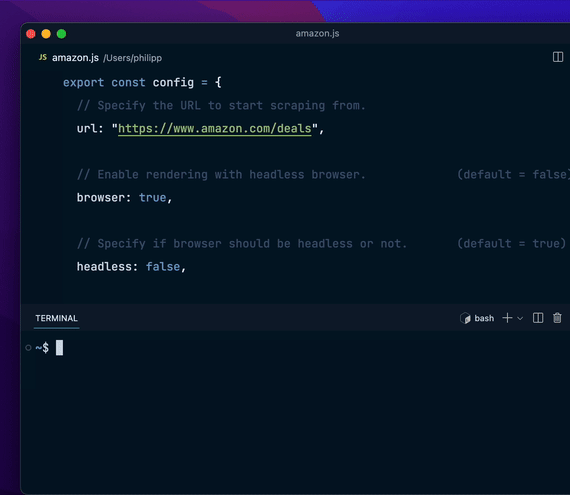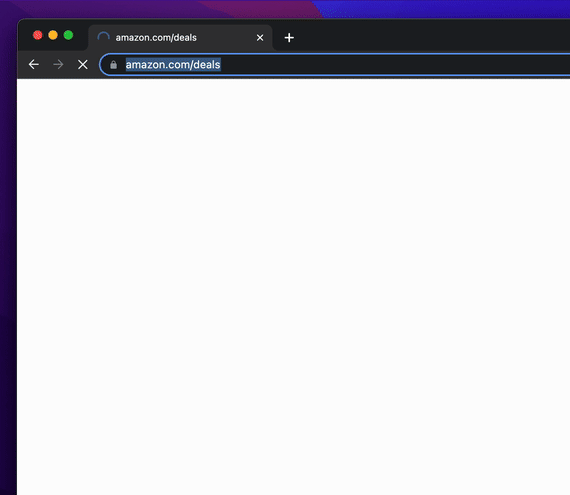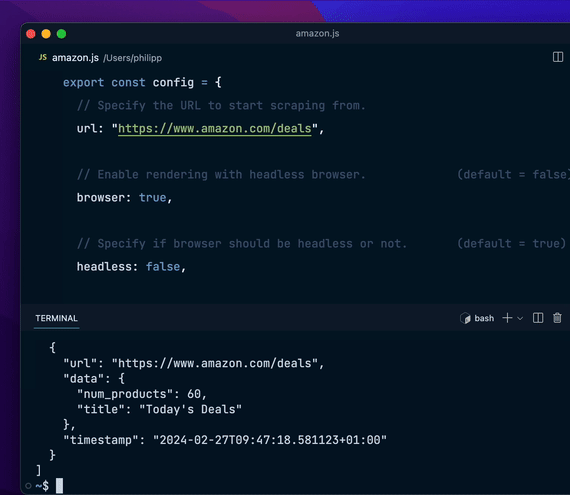 export const config = { url: "https://hackernews.com", // 更多配置...};编写数据提取逻辑
export const config = { url: "https://hackernews.com", // 更多配置...};编写数据提取逻辑编写数据提取逻辑,使用类似于 jQuery 或 cheerio 的 API:
export default function({ doc, absoluteURL }) { // 数据提取代码...};启动开发模式使用 dev 命令启动开发模式:
flyscrape dev hackernews.js运行爬虫使用 run 命令执行爬虫:
flyscrape run hackernews.js输出结果爬虫将输出一个 JSON 数组,包含所有抓取的页面数据。
Flyscrape 的优势易用性:简单设置和直观的 API 设计。灵活性:适应各种复杂的抓取需求。强大性:内置浏览器模式和 Cookies 支持。直观性:通过 dev 模式,可以时刻查询到代码的修改,得到想要的数据信息。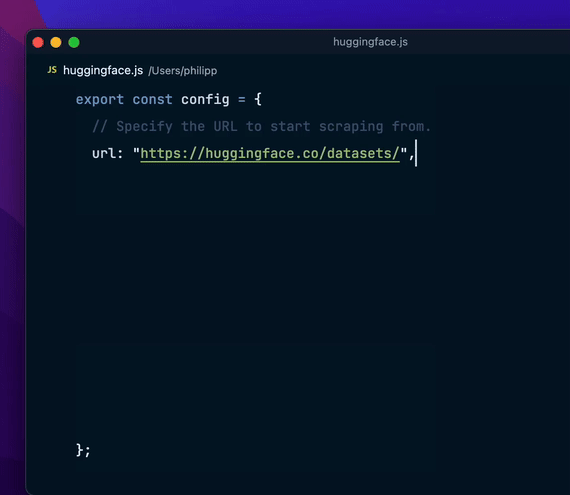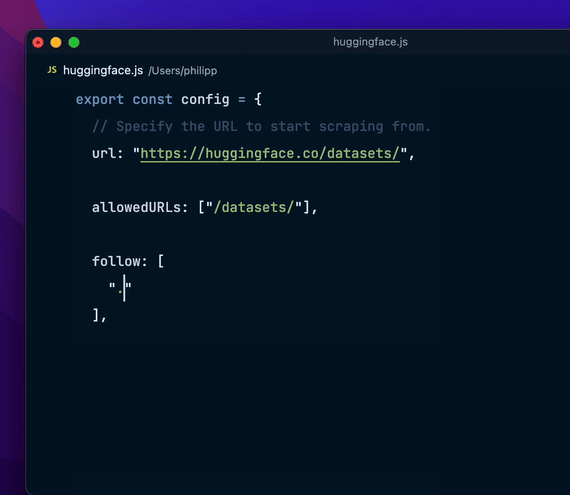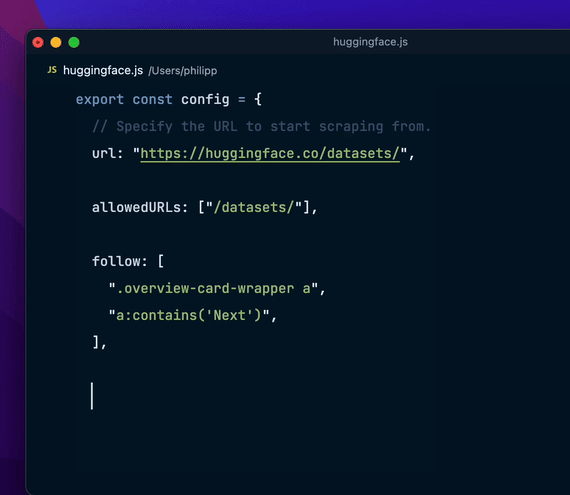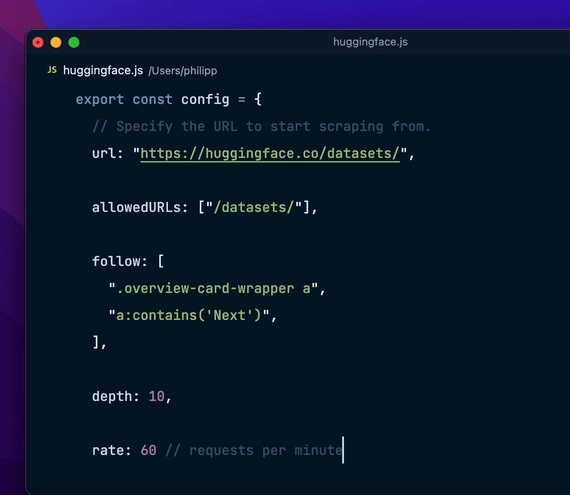 结语
结语Flyscrape 为用户提供了一个高效、便捷的数据抓取解决方案。如果你需要快速构建自定义爬虫,Flyscrape 是一个值得尝试的选择。