
关注智尊AI大模型
“Arena Learning提供了一种高效、可扩展的新方法,通过模拟聊天机器人竞技场,利用AI评判模型代替人工评估,实现了模型的持续优化。这种方法的成功实施预示了人工智能在自然语言处理领域的新方向,特别是在自动化和减少对昂贵人工资源的依赖方面。”
1、Frozenset基础介绍 🌐在自然语言处理领域,LLM展现出了强大的能力,尤其是对话系统中的应用。然而,模型评估和持续优化面临着巨大挑战:
人工评估成本高传统的人工评估方法虽然能够提供精确的评估结果,但这种方法耗时且成本高昂。
持续优化困难随着应用场景的不断演化,模型需要不断调整和优化,以适应新的用户意图和指令。
为了解决这些问题,构建一个高效的数据飞轮,以持续收集反馈并改进大模型,成为了必要的研究方向。
2、Arena Learning方法概述 🧩
ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
Arena Learning是一种完全基于AI的训练和评估流水线,它通过以下几个步骤实现了模型的持续优化,无需人工介入。
模型离线聊天聊天机器人竞技场通过AI模拟的方式创建竞技场环境,让模型在控制的环境中对战。
AI代替人工评估模型使用先进的LLM作为评判标准,模拟人类评估者的行为。
构建数据飞轮持续优化模型通过对战生成的数据反馈,持续训练和优化大模型。
3、核心技术:AI评判大模型 🔍
ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
Arena Learning的核心技术之一是采用AI评判大模型,这个模型的具体实现包括:
评判大模型使用如Llama3-70B-Chat等高能力模型作为裁判。
输入包括对话历史、用户指令以及两个LLM的响应。
输出对每个LLM的评分,十分制;
详细解释,涉及连贯性、事实准确性、上下文理解等因素
判断哪个回复更优
消除位置偏差通过交替两个大模型的位置进行两轮对战,确保评估的公平性。
这种AI评判模型能够客观地评估回复质量,极大提高了评估的效率和一致性。
4、构建数据飞轮 ⏱️Arena Learning通过以下步骤构建数据飞轮,以实现LLM的持续优化:
收集大规模指令数据从多个开源数据集收集原始指令数据
进行多轮过滤、清洗和去重
使用MinHashLSH等技术进行数据去重
排除与测试集相似的指令,防止数据泄露
迭代对战和模型优化初始训练使用特定数据集训练基础模型
通过多轮SFT、DPO和PPO迭代训练,不断使用新的对战数据更新和优化模型。

ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
5、WizarArena:离线评估套件 🎯为了准确评估模型性能并预测Elo排名,研究团队开发了离线测试集WizardArena,包括:
多样性子集论文使用 K-Means聚类算法将源数据处理成 500 个类别。从每个类别中,随机选取两个样本,构建 1000 个多样性样本,创建 Offline-Diverse WizardArena。
困难子集从每个类别随机选择 20 个样本,形成一个包含 10000 条的数据集,然后使用 GPT-4 按难易程度从 0 到 10 评估每个指令,并筛选出难度最高的 1000 条数据,创建 Offline-Hard WizardArena。
WizardArena的优势效率:
比传统方法快40倍
规模:
包含2000个样本,覆盖广泛主题
一致性:
与在线竞技高度一致
Offline-Mix WizardArena 将多样性和困难测试集合并为 2000 个样本。与主要关注单轮对话数据的 Arena-Hard-v1.0 不同,WizardArena-Mix 纳入了多轮对话数据。下图 4 和 5 显示了 WizardArena-Mix 中对话轮次的分布和类别统计。WizardArena-Mix 多轮对话数据占据了很大比例,话题分布也具有多样性。

ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
通过上面的“裁判”模型和离线的 WizardArena 评测集,使用一系列对战来评估各种聊天机器人模型的性能。然后使用战斗的结果来计算参与聊天机器人模型的 Elo 排名。
6、实验结果与分析 🎯实验表明,通过Arena learning产生的数据训练的模型在多个阶段表现出显著的性能提升,验证了这一方法的有效性和扩展性。
WizardArena 与 LMSYS ChatBot Arena 是否紧密对齐下图 6 展示了一些流行模型在 3 个评估基准上的排名:LMSYS ChatBot Arena-EN、MT-Bench 和 WizardArena。结果显示,在使用 LMSYS ChatBot Arena 作为参考基准时,WizardArena 展现了良好的排名一致性,然而 MT-Bench 显示出较大的波动。

ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
下表 3 显示,Offline WizardArena-Mix 在多个一致性指标上显著优于 MT-Bench,进一步证明了 WizardArena-Mix 高质量以及使用“裁判”模型来评判 LLMs 之间的对战并在模拟竞技场中为后训练生成大量高质量数据的可行性。

ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
建立一个高效的数据飞轮用于模型 Post-training下表 4 展示了使用 Arena Learning 方法在三轮数据飞轮迭代中对 WizardLM-β 模型进行后训练的影响,其中 Ii 代表第 i 次迭代。通过 Arena Learning 方式与 SOTA 模型进行持续对战并使用最新获取的数据更新模型权重可以逐步增强模型能力。因此,Arena Learning 构建了一个有效的数据飞轮,使用 Arena Learning 可以显著提高模型在后训练中的性能。


ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
Post-training 中 SFT,DPO,PPO 迭代训练的 Scaling下图 8展示通过 Arena Learning 方式经过多轮迭代对战,在 SFT,DPO,PPO 阶段模型性能也逐步提升。具体来说,从 SFT-I0 到 PPO-I3,WizardArena-Mix ELO 评分从 871 提升至 1274,实现了巨大的 403 点增幅,而 Arena-Hard Auto ELO 评分也上升了 26.3 点(从 5.2 到31.5)。

ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
7、消融实验 🎯数据选取策略论文提出了judge-pair battle 策略,跟当前广泛使用的数据选择策略进行了对比,表5表明通过 judge-pair battle方法选出的数据使 WizardArena-Mix ELO 比 Original 的 30k 数据提高了 29 点,超过了基于多样性的 K-Means 聚类方法和基于指令复杂度的 INSTAG 方法。同时,这些结果强调了 judge-pair 方法在 SFT 阶段针对性选取高质量数据并加强基础模型弱点的高效性,同时通过 judge pair battle 方式构造 <Choose,Reject> 数据对天然适应 DPO 和 PPO 训练。
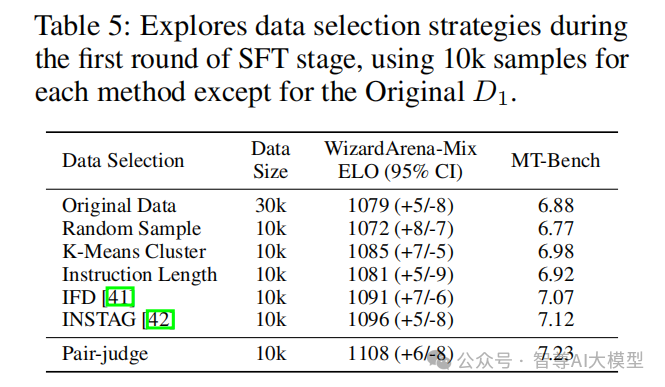
ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
数据规模与模型性能的关系论文讨论了数据规模和质量对模型性能的影响。阈值 K 是 Arena Learning 中一个重要的超参数,它控制了 SFT 数据的规模以及 RL 数据对中 <Choose,Reject> 两者回答质量的差距。图9结果表明通过 Battle 方式有助于筛选出模型真正需要的数据,从而构建了一个更高效、规模更精简的数据飞轮。阈值选择除了与数据的质量有关,还与数据的数量有关,这两个因素都会影响最终的训练效果。阈值过小的时候数据数量虽然很大但是整体质量太低,阈值过大的时候数据整体质量很高但是数据量太小,这两种情况都不利于训练。因此,选择一个合适的阈值很重要。

ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
Llama3-70B-Instruct Judge vs. GPT-4 Judge一致性表 6 探讨了 Llama3-70B-Instruct 与 GPT-4 在 WizardArena-Mix 竞技场中作为评判模型的一致性。结果证明使用 Llama3-70B-Instruct 作为性价比高的评判模型,与 GPT-4 和基于人工评判的 LMSYS ChatBot Arena 都保持了高度的一致性,确保了本文中 WizardArena 评估和使用 Arena Learning 方式进行 Post-training 的可靠性。

ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
与SOTA模型Battle数量的Scaling下图 10 证明了Battle 模型数量 Scaling 和 Arena Learning 的可扩展性及其与不同模型的兼容性,为未来算法的大规模应用提供了实验基础。

ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
不同Battle方式对模型性能提升的影响论文探索了使用多个模型进行彼此成对 Battle 来构建数据飞轮的必要性,在 D1 数据 SFT-I1 阶段设计了多种 Battle 模式,包括:i)与任意一个模型进行成对 Battle,ii)将 D1 随机分为三份,分别在每一份数据上只和一个模型进行 Battle,iii) 与任意两个模型进行成对 Battle,iv)与三个模型进行成对 Battle。结果如下表 7 展示,模式(iv)在 WizardArena 上表现最佳。因此论文最终利用多个模型进行彼此成对战斗,以构建模拟的离线聊天机器人竞技场。

ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
在 LMSYS Arena-Hard Auto,AlpacaEval 2.0 LC,OpenLLM Leaderboard 的表现下表8展示了经过三轮迭代后,WizardLM-β 在各种评测基准上的表现,结果表明:1)利用 Arena Learning 生成训练数据的方法并进行多轮迭代训练显著提升了模型的性能;2)Arena Learning 可以增强模型泛化能力和可扩展性。

ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
每轮SFT选取的数据量和难度分布下表 9 详细展示了 SFT 每一轮的数据量、难度和阈值划分。证明了随着模型能力的进化,其输掉的对战场数也急剧下降,高质量的数据飞轮应更加注重寻找对目标模型具有挑战性的数据,以补充其能力的不足。
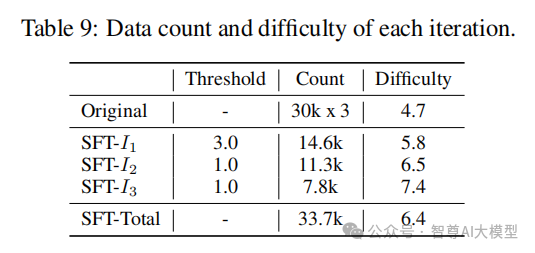
ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
每轮从所有Battle模型中选取的数据量统计下表 10 统计了在 SFT 和 DPO 阶段的3轮中,每个 Battle 模型被选取的胜利/接受响应的数量。在 SFT 阶段,每轮数据量通过连续的迭代轮数持续下降(从 14.6k 降至 7.8k)。此外,选定数据的数量与 Battle 模型的表现强相关。在 DPO 阶段,大多数 Battle 模型随着迭代轮数增多,选取的数据量呈现下降趋势,但 WizardLM-β 的数据量呈上升趋势(1.1k->1.6k->2.3k),主要原因是随着 WizardLM-β 模型性能的提升,它在正向样本中的比例也逐渐增

ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
每轮各类别数据量分布统计下图 11 展示了 SFT 在每轮迭代中各类别选取训练数据量的趋势,结果表明随着每次迭代的进行,数据的选择逐渐偏向于更具挑战性的任务,从而有利于继续强化模型在这些复杂类别中的性能。
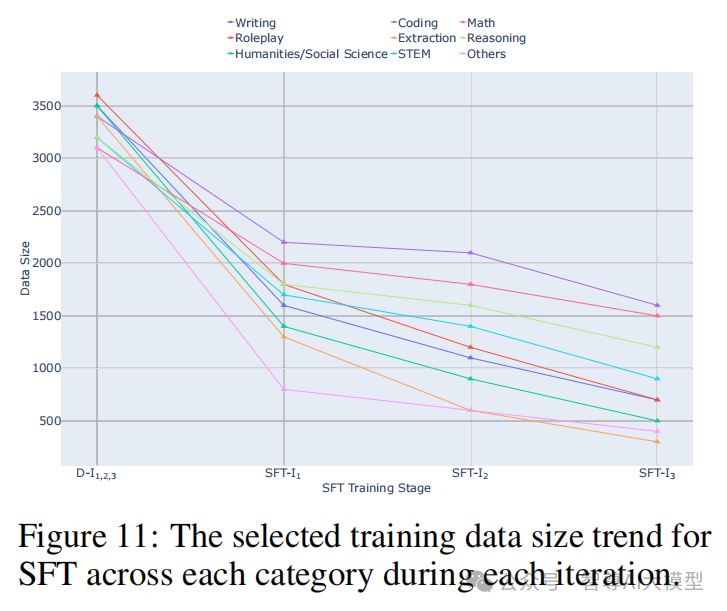
ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
模型在所有类别性能变化趋势下图 12 展示在训练阶段随着迭代次数增加,WizardLM-β-7B 模型在八个类别中 ELO 分数的演变,结果证明了 Arena Learning 通过利用多个先进模型的集体知识和优势来显著提升 WizardLM-β-7B Post-training 性能。

ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
使用更先进的模型进行Battle下表11探索第一轮中采用更先进模型与 WizardLM-β-7B 进行对战的性能影响,结果突显了通过采用更先进模型进行对战可以实现更显著的性能改进。
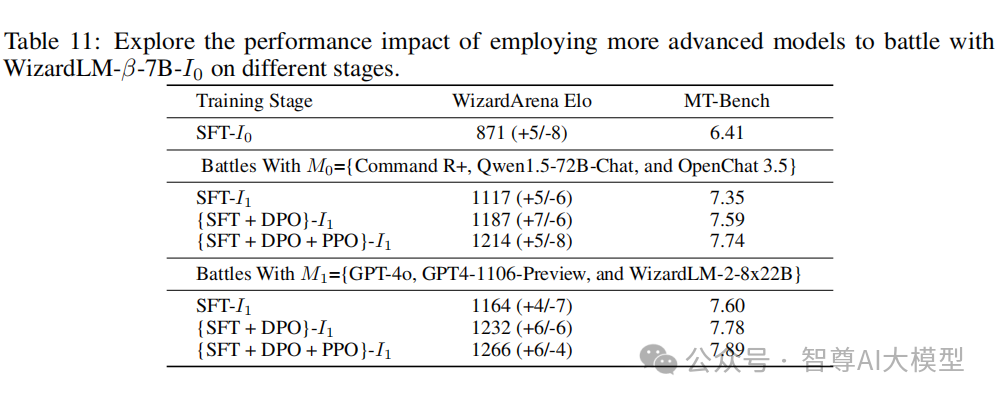
ArenaLearning通过模拟LLM竞技场来构建大规模数据飞轮
8、总结 🚀Arena Learning作为一种前沿且极具潜力的方法,为模型的持续优化开辟了一条高效且可扩展的新途径。它巧妙地构建了模拟聊天机器人竞技场的场景,并引入了AI评判机制,从而有效替代了传统的人工评估方式。这一创举不仅预示着人工智能在自然语言处理领域的崭新航向,还显著推动了自动化进程,大幅降低了对昂贵且有限人工资源的依赖。
本文不仅是对AI自我优化能力的一次深刻剖析,更是对未来AI技术发展蓝图的一次前瞻性构想,激励着研究者与开发者不断探索更加智能、高效且可持续的AI应用方案。
论文标题:
Arena Learning: Build Data Flywheel for LLMs Post-training via Simulated Chatbot Arena
论文链接:
https://www.microsoft.com/en-us/research/publication/arena-learning-build-data-flywheel-for-llms-post-training-via-simulated-chatbot-arena/

关注智尊AI大模型

关注智尊AI大模型