关于数据的分组计数,前面的文章中已经涉及了很多次。眼下要进行分组计数,我们可用的方法有:1、直接使用dict进行计数,需要对首次出现的键进行判断初始化的操作;2、使用dict的setdefault()方法进行计数,代码可以简化一些,虽然方法名有点怪;3、defaultdict进行计数,可以设置自动初始化,代码更加简洁。
虽然前面这三个方法都可以实现计数的需求,但是,还是停留在相对基础的计数功能。
如果我们想要更加灵活的计数功能,比如计完数之后,取出Top N,比如分别计数之后的合并……
前面的基础计数功能,倒不是不能实现这些需求,只是相对来说,有些麻烦了。我们可以试试collections中的Counter类,一个专门为计数而生的工具类。
Counter定义Counter是collections模块下的一个工具类,我们已经介绍过的defaultdict也是该模块中的。首先看下Counter的定义文档:
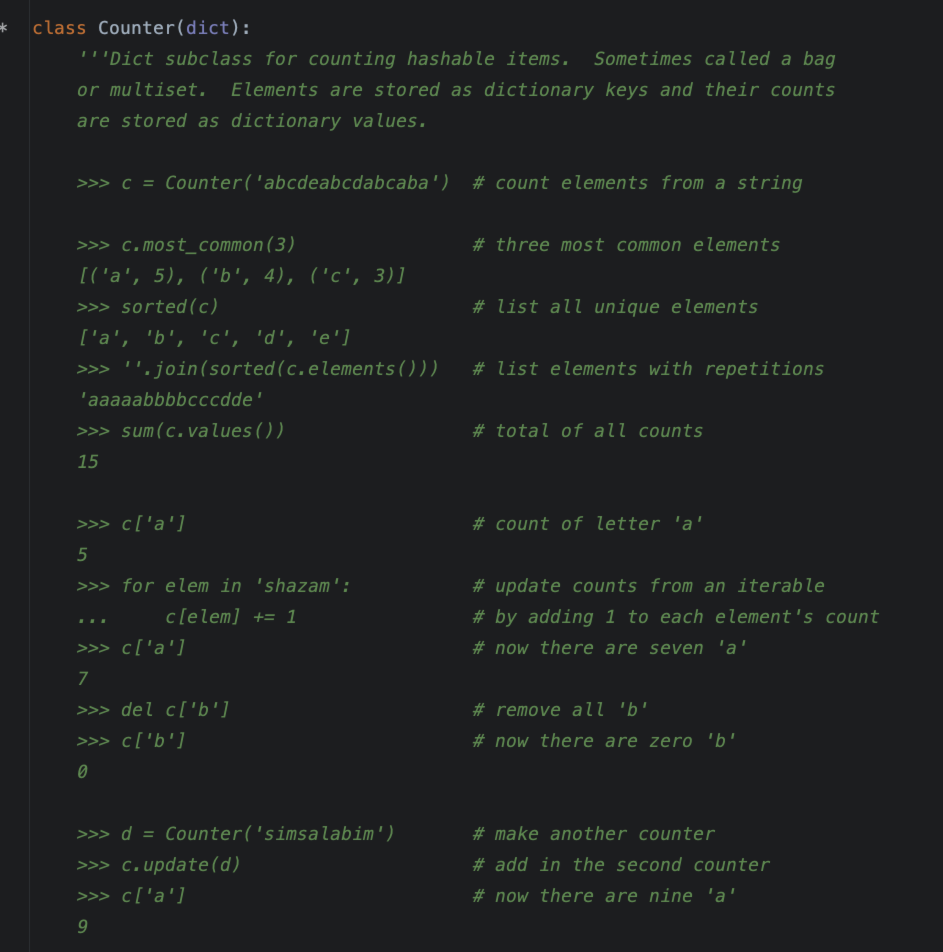
可以看到Counter是dict的子类,用于统计可哈希的元素的个数。其实,从文档中,已经能学到关于Counter的主要功能了。
需要注意的是,统计的是可哈希的元素,这点可能会限制了Coutner的使用范围,但是,结合defaultdict,还是可以实现更加灵活的计数。
要使用Counter,还要看下我们怎么能够构造一个Counter对象。看下文档中,魔术方法:__init__的说明:

可以看到,我们有几种主要的构造方式:
1、无参形式,直接构造一个空对象,然后在后续逐步更新。
2、传入一个可迭代的对象,一般是原始数据明细,比如字符串、列表、元组等,会自动对可迭代对象计数。
3、传入一个字典对象,一般是已经有的计数结果,用于对计数结果进行更进一步的扩充。
4、以关键字参数的形式传参,如同字典一样,只是已有的计数结果的存储形式可能不同而已。
所以,对于不可哈希的元素,我们可以通过dict或者defaultdict进行计数,然后用统计结果进行Counter对象的构造。
Counter的核心用法1、简单的可哈希数据元素的计数并取出Top N
首先我们以单词计数为例,首先我们先生成一个列表,存放各个单词,然后对这些单词进行统计计数,最终输出单词的统计结果,并给出出现最多的Top 3。
直接看代码:
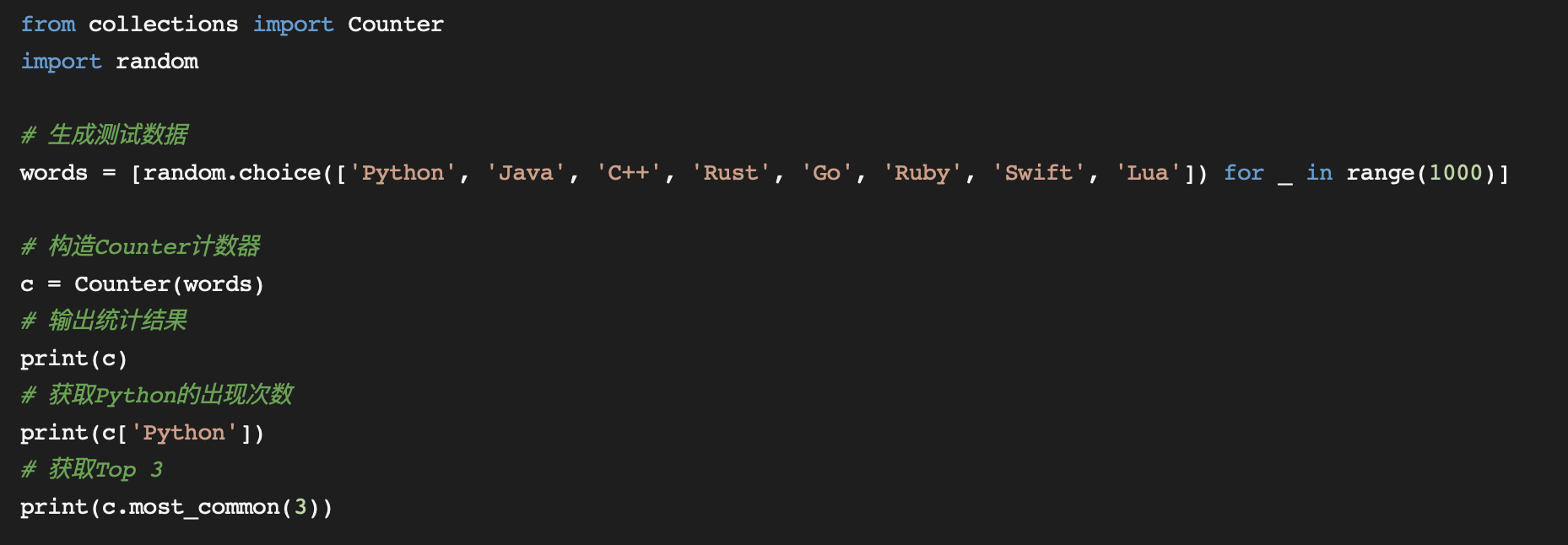
执行结果:

代码中,我们使用list存放所有的单词数据,然后用其构造一个Counter对象。Counter对象可以像dict一样,使用[key]方式索引元素的出现次数。most_common(n)方法,以列表的形式,返回Top n的数据,列表中的元素为元组形式,分别为键值和对应的次数。
复杂的计数场景
有些场景下,计数结果并没有我们所看到的这么简单。
如果数据存储在了两个列表中,或者数据量比较大,我们是分布式统计的,以便于提高统计的效率,就会涉及到每个局部统计的结果合并的问题。
如果使用dict或者defaultdict来处理这种情况,可能又涉及到键值判断或者初始化默认值的情况,但是用Counter则会变得简单很多,可以直接进行两个Counter的数学运算。
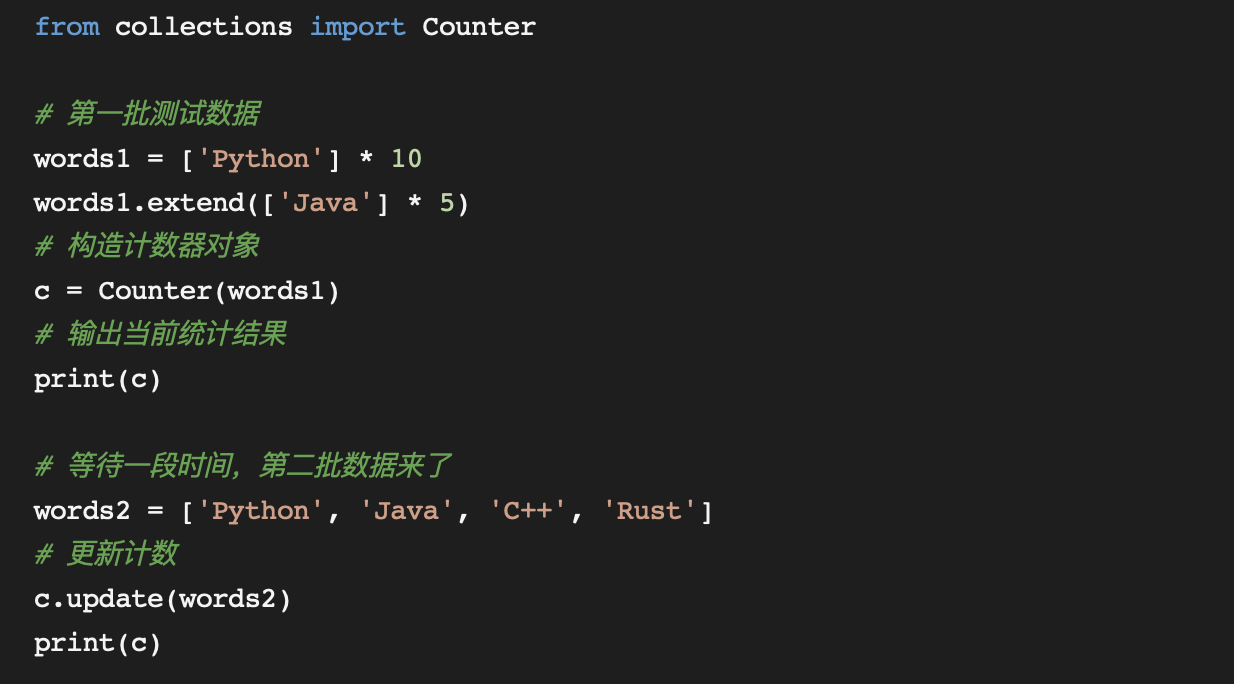
2、Counter对象的增量迭代式计数
首先看,增量式统计,数据是一批批陆续到来的,我们要使用Counter的update()方法进行计数的增量更新:

3、Counter对象的数学运算,实现局部计数结果的合并
大数据计算中,一个典型的入门案例,就是分布式word count。将海量数据切分为多个任务,分布到不同节点上分别进行统计,获取中间结果,然后将结合汇聚,生成最终的结果。
我们简单模拟一下,只是为了演示Counter的数学运算:

执行结果:

当然,Coutner也是支持减法、交集、并集等运算的,这里就不一一演示了,感兴趣的,可以自行尝试。
4、不可哈希元素计数针对不可哈希的元素的统计计数,我们可以结合dict、defaultdict得出统计结果,如果后续需要进行Top N的处理,或者统计结果的合并,再交由Counter进行进一步加工处理。
也可以使用列表生成式,将不可哈希的元素转换为可哈希的元素,然后进行统计。
总结本文主要就关于统计计数的相关实现方式,重点介绍了Counter的基本使用。其实,这些都不需要记忆,只要有需求场景时,能想到有这么个工具类,实际使用时,再查看定义文档即可。
