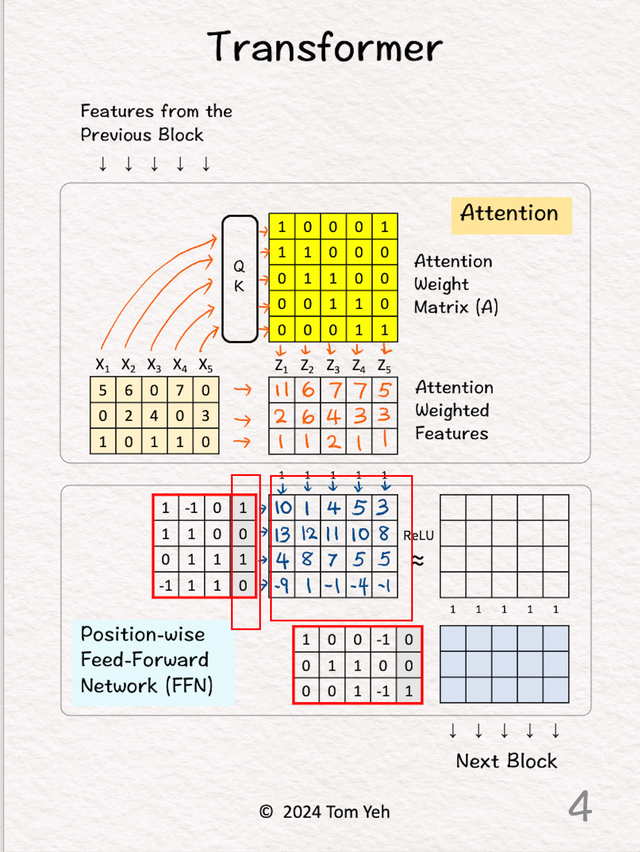
Transformer的结构可以很复杂,但是其中最主要的还是自注意机制和FNN(feed-forward network),其他的
1.输入前一个块的输入特征(5个向量,3维的)
 2.注意力矩阵
2.注意力矩阵将所有 5 个特征输入查询键注意力模块 (QK) 以获得注意力权重矩阵 (A),前面有文章介绍过。
 3.注意力加权
3.注意力加权将输入特征与注意力权重矩阵相乘,得到注意力加权特征(Z)。
效果就像是一个水平组合,比如这儿的,
 4.Feed Forward层1
4.Feed Forward层1将所有 5 个注意力加权特征输入到第一层FNN。
将这些特征值与权重相乘再加上偏差。效果是垂直组合。每个特征的维度从 3 增加到 4。每个位置都由相同的权重矩阵处理。FFN 本质上是一个多层感知器。
 5.Feed Forward层1,ReLU处理
5.Feed Forward层1,ReLU处理经过一次ReLU处理。
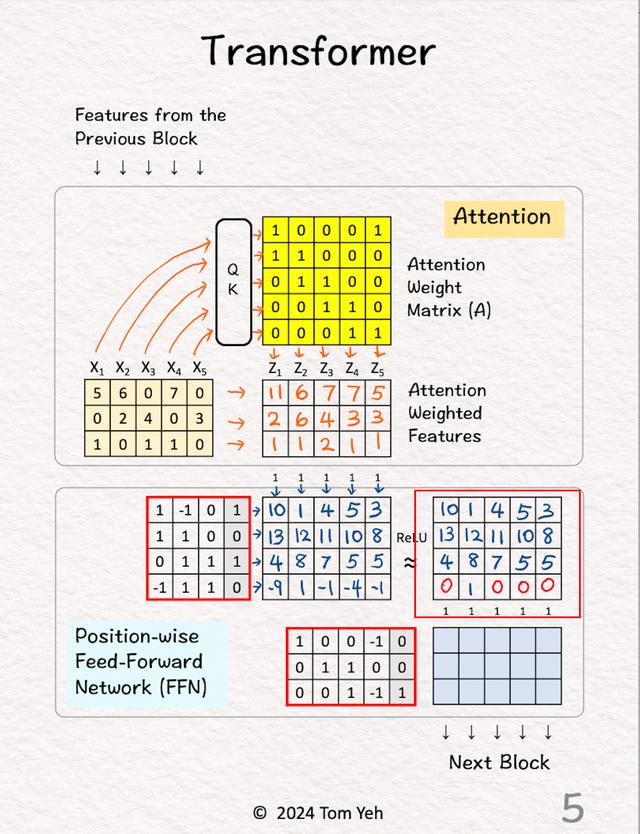 6.Feed Forward层2
6.Feed Forward层2将所有 5 个特征 (3维)输入到Feed Forward第二层。每个特征的维度从 4 降回 3(和输入一样)。输出被送到下一个块以重复此过程。
