Linux 网络架构
Linux 网络初始化
网络设备子系统初始化
网卡驱动初始化
协议栈初始化
数据包的接收过程
硬中断处理
ksoftirqd 软中断处理
协议栈处理
应用层处理
总结
这里深度理解一下在Linux下网络包的接收过程,为了简单起见,我们用udp来举例,如下:
int main(){int serverSocketFd = socket(AF_INET, SOCK_DGRAM, 0); bind(serverSocketFd, ...);char buff[BUFFSIZE];int readCount = recvfrom(serverSocketFd, buff, BUFFSIZE, 0, ...); buff[readCount] = '\0';printf("Receive from client:%s\n", buff);}上面代码是一段udp server接收收据的逻辑。只要客户端有对应的数据发送过来,服务器端执行recv_from后就能收到它,并把它打印出来。那么当网络包达到网卡,直到recvfrom收到数据,这中间究竟都发生过什么?
Linux 网络架构在Linux内核实现中,链路层协议靠网卡驱动来实现,内核协议栈来实现网络层和传输层。内核对更上层的应用层提供socket接口来供用户进程访问。我们用Linux的视角来看到的TCP/IP网络分层模型应该是下面这个样子的。
 Linux 网络初始化网络设备子系统初始化
Linux 网络初始化网络设备子系统初始化linux内核通过调用subsys_initcall来初始化各个子系统,其中网络子系统的初始化会执行到net_dev_init函数:
//net/core/dev.cstatic int __init net_dev_init(void){ ...... for_each_possible_cpu(i) {struct softnet_data *sd = &per_cpu(softnet_data, i);memset(sd, 0, sizeof(*sd)); skb_queue_head_init(&sd->input_pkt_queue); skb_queue_head_init(&sd->process_queue); sd->completion_queue = ; INIT_LIST_HEAD(&sd->poll_list); ...... } ...... open_softirq(NET_TX_SOFTIRQ, net_tx_action); open_softirq(NET_RX_SOFTIRQ, net_rx_action);}subsys_initcall(net_dev_init);首先为每个CPU都申请一个softnet_data数据结构,在这个数据结构里的poll_list是等待驱动程序将其poll函数注册进来,稍后网卡驱动初始化的时候我们可以看到这一过程。
然后 open_softirq 为每一种软中断都注册一个处理函数。NET_TX_SOFTIRQ的处理函数为net_tx_action,NET_RX_SOFTIRQ的为net_rx_action。
//kernel/softirq.cvoid open_softirq(int nr, void (*action)(struct softirq_action *)){ softirq_vec[nr].action = action;}open_softirq 会把不同的 action 记录在softirq_vec变量里的。后面ksoftirqd线程收到软中断的时候,也会使用这个变量来找到每一种软中断对应的处理函数。
 网卡驱动初始化
网卡驱动初始化这里以 FSL 系列网卡为例,其驱动位于:drivers/net/ethernet/freescale/fec_main.c
static struct platform_driver fec_driver = { .driver = { .name = DRIVER_NAME, .pm = &fec_pm_ops, .of_match_table = fec_dt_ids, .suppress_bind_attrs = true, }, .id_table = fec_devtype, .probe = fec_probe, .remove = fec_drv_remove,};static intfec_probe(struct platform_device *pdev){ fec_enet_clk_enable fec_reset_phy //使用gpio 复位phy 芯片 fec_enet_init //设置netdev_ops、设置ethtool_opsfor (i = 0; i < irq_cnt; i++) { devm_request_irq(..., irq, fec_enet_interrupt, ...); } fec_enet_mii_init //读取dts mdio节点下phy子节点,并注册phy_device register_netdev //注册网络设备}Linux 以太网驱动会向上层提供 net_device_ops ,方便应用层控制网卡,比如网卡被启动(例如,通过 ifconfig eth0 up)的时候会被调用 fec_enet_open,此外它还包含着网卡发包、设置 mac 地址等回调函数。
static const struct net_device_ops fec_netdev_ops = { .ndo_open = fec_enet_open, .ndo_stop = fec_enet_close, .ndo_start_xmit = fec_enet_start_xmit, .ndo_select_queue = fec_enet_select_queue, .ndo_set_rx_mode = set_multicast_list, .ndo_validate_addr = eth_validate_addr, .ndo_tx_timeout = fec_timeout, .ndo_set_mac_address = fec_set_mac_address, .ndo_eth_ioctl = fec_enet_ioctl,#ifdef CONFIG_NET_POLL_CONTROLLER .ndo_poll_controller = fec_poll_controller,#endif .ndo_set_features = fec_set_features, .ndo_bpf = fec_enet_bpf, .ndo_xdp_xmit = fec_enet_xdp_xmit,};此外,网卡驱动实现了 ethtool 所需要的接口,当 ethtool 发起一个系统调用之后,内核会找到对应操作的回调函数。可以看到 ethtool 这个命令之所以能查看网卡收发包统计、能修改网卡自适应模式、能调整RX 队列的数量和大小,是因为 ethtool 命令最终调用到了网卡驱动的相应方法。
static const struct ethtool_ops fec_enet_ethtool_ops = { .supported_coalesce_params = ETHTOOL_COALESCE_USECS | ETHTOOL_COALESCE_MAX_FRAMES, .get_drvinfo = fec_enet_get_drvinfo, .get_regs_len = fec_enet_get_regs_len, .get_regs = fec_enet_get_regs, .nway_reset = phy_ethtool_nway_reset, .get_link = ethtool_op_get_link, .get_coalesce = fec_enet_get_coalesce, .set_coalesce = fec_enet_set_coalesce,#ifndef CONFIG_M5272 .get_pauseparam = fec_enet_get_pauseparam, .set_pauseparam = fec_enet_set_pauseparam, .get_strings = fec_enet_get_strings, .get_ethtool_stats = fec_enet_get_ethtool_stats, .get_sset_count = fec_enet_get_sset_count,#endif .get_ts_info = fec_enet_get_ts_info, .get_tunable = fec_enet_get_tunable, .set_tunable = fec_enet_set_tunable, .get_wol = fec_enet_get_wol, .set_wol = fec_enet_set_wol, .get_eee = fec_enet_get_eee, .set_eee = fec_enet_set_eee, .get_link_ksettings = phy_ethtool_get_link_ksettings, .set_link_ksettings = phy_ethtool_set_link_ksettings, .self_test = net_selftest,};协议栈初始化内核实现了网络层的 ip 协议,也实现了传输层的 tcp 协议和 udp 协议。这些协议对应的实现函数分别是 ip_rcv(),tcp_v4_rcv()和udp_rcv()。
网络协议栈是通过函数 inet_init() 注册的,通过inet_init,将这些函数注册到了inet_protos和ptype_base数据结构中了。如下图:
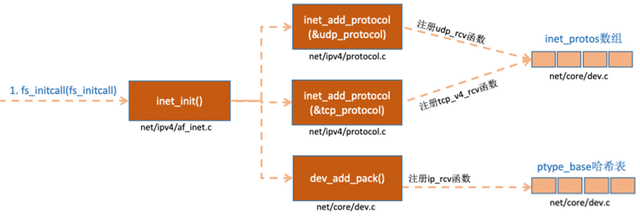
相关代码如下:
//net/ipv4/af_inet.cstatic struct packet_type ip_packet_type __read_mostly = { .type = cpu_to_be16(ETH_P_IP), .func = ip_rcv, .list_func = ip_list_rcv,};static const struct net_protocol tcp_protocol = { .handler = tcp_v4_rcv, .err_handler = tcp_v4_err, .no_policy = 1, .icmp_strict_tag_validation = 1,};static const struct net_protocol udp_protocol = { .handler = udp_rcv, .err_handler = udp_err, .no_policy = 1,};static int __init inet_init(void){ ......if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0) pr_crit("%s: Cannot add ICMP protocol\n", __func__);if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0) //注册 udp_rcv() pr_crit("%s: Cannot add UDP protocol\n", __func__);if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0) //注册 tcp_v4_rcv() pr_crit("%s: Cannot add TCP protocol\n", __func__); ...... dev_add_pack(&ip_packet_type); /注册 ip_rcv()}上面的代码中我们可以看到,udp_protocol结构体中的handler是udp_rcv,tcp_protocol结构体中的handler是tcp_v4_rcv,通过inet_add_protocol被初始化了进来。
int inet_add_protocol(const struct net_protocol *prot, unsigned char protocol){if (!prot->netns_ok) { pr_err("Protocol %u is not namespace aware, cannot register.\n", protocol);return -EINVAL; }return !cmpxchg((const struct net_protocol **)&inet_protos[protocol],, prot) ? 0 : -1;}inet_add_protocol函数将tcp和udp对应的处理函数都注册到了inet_protos数组中了。
再看dev_add_pack(&ip_packet_type);这一行,ip_packet_type结构体中的type是协议名,func是ip_rcv函数,在dev_add_pack中会被注册到ptype_base哈希表中。
//net/core/dev.cvoid dev_add_pack(struct packet_type *pt){struct list_head *head = ptype_head(pt); ......}static inline struct list_head *ptype_head(const struct packet_type *pt){if (pt->type == htons(ETH_P_ALL))return &ptype_all;elsereturn &ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];}这里我们需要记住inet_protos记录着udp,tcp的处理函数地址,ptype_base存储着ip_rcv()函数的处理地址。后面我们会看到软中断中会通过ptype_base找到ip_rcv函数地址,进而将ip包正确地送到ip_rcv()中执行。在ip_rcv中将会通过inet_protos找到tcp或者udp的处理函数,再而把包转发给udp_rcv()或tcp_v4_rcv()函数。
数据包的接收过程硬中断处理首先当数据帧从网线到达网卡,网卡在分配给自己的 ringBuffer 中寻找可用的内存位置,找到后 DMA 会把数据拷贝到网卡之前关联的内存里。当 DMA 操作完成以后,网卡会向 CPU 发起一个硬中断,通知 CPU 有数据到达。
中断处理函数为:
//drivers/net/ethernet/freescale/fec_main.cstatic irqreturn_tfec_enet_interrupt(int irq, void *dev_id){struct net_device *ndev = dev_id;struct fec_enet_private *fep = netdev_priv(ndev);irqreturn_t ret = IRQ_NONE;if (fec_enet_collect_events(fep) && fep->link) { ret = IRQ_HANDLED;if (napi_schedule_prep(&fep->napi)) {/* Disable interrupts */ writel(0, fep->hwp + FEC_IMASK); __napi_schedule(&fep->napi); } }return ret;}//net/core/dev.c__napi_schedule->____napi_schedulestatic inline void ____napi_schedule(struct softnet_data *sd, struct napi_struct *napi){ list_add_tail(&napi->poll_list, &sd->poll_list); __raise_softirq_irqoff(NET_RX_SOFTIRQ);}这里我们看到,list_add_tail修改了CPU变量softnet_data里的poll_list,将驱动napi_struct传过来的poll_list添加了进来。其中softnet_data中的poll_list是一个双向列表,其中的设备都带有输入帧等着被处理。紧接着 __raise_softirq_irqoff 触发了一个软中断 NET_RX_SOFTIRQ。
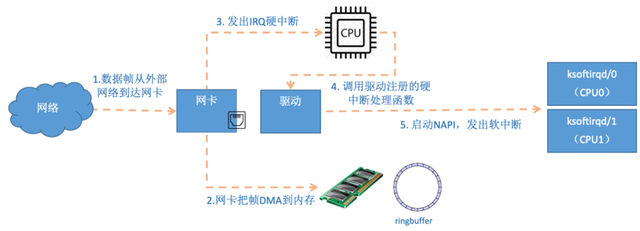
注意:当RingBuffer满的时候,新来的数据包将给丢弃。ifconfig查看网卡的时候,可以里面有个overruns,表示因为环形队列满被丢弃的包。如果发现有丢包,可能需要通过ethtool命令来加大环形队列的长度。
ksoftirqd 软中断处理接下来进入软中断处理函数:
//kernel/softirq.cstatic void run_ksoftirqd(unsigned int cpu){ local_irq_disable();if (local_softirq_pending()) { __do_softirq(); rcu_note_context_switch(cpu); local_irq_enable(); cond_resched();return; } local_irq_enable();}asmlinkage __visible void __softirq_entry __do_softirq(void){while ((softirq_bit = ffs(pending))) { h->action(h); }}在网络设备子系统初始化中,讲到为 NET_RX_SOFTIRQ 注册了处理函数 net_rx_action。所以 net_rx_action 函数就会被执行到了。
//net/core/dev.cstatic __latent_entropy void net_rx_action(struct softirq_action *h){struct softnet_data *sd = this_cpu_ptr(&softnet_data); list_splice_init(&sd->poll_list, &list);for (;;) { ... n = list_first_entry(&list, struct napi_struct, poll_list); budget -= napi_poll(n, &repoll); ... } ...}napi_poll->__napi_poll->work = n->poll(n, weight)首先获取到当前CPU变量softnet_data,对其poll_list进行遍历, 然后执行到网卡驱动注册到的 poll 函数。对于 FSL 网卡来说,其驱动对应的 poll 函数就是 fec_enet_rx_napi。
//drivers/net/ethernet/freescale/fec_main.cstatic int fec_enet_rx_napi(struct napi_struct *napi, int budget){struct net_device *ndev = napi->dev;struct fec_enet_private *fep = netdev_priv(ndev);int done = 0;do { done += fec_enet_rx(ndev, budget - done); fec_enet_tx(ndev); } while ((done < budget) && fec_enet_collect_events(fep));if (done < budget) { napi_complete_done(napi, done); writel(FEC_DEFAULT_IMASK, fep->hwp + FEC_IMASK); }return done;}fec_enet_rx->fec_enet_rx_queue
然后进入 GRO 处理,流程如下:
napi_gro_receive->napi_skb_finish->gro_normal_one->gro_normal_list->netif_receive_skb_list_internal
最终通过函数 netif_receive_skb_list_internal() 进入内核协议栈。
协议栈处理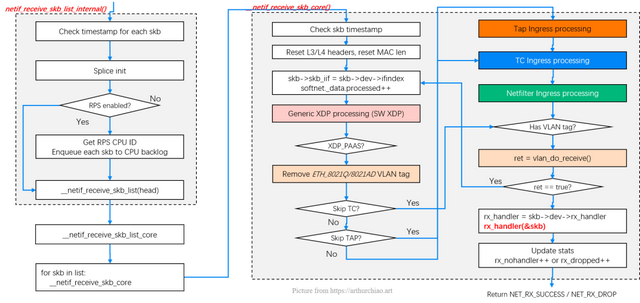 static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc, struct packet_type **ppt_prev){ ......//抓包 list_for_each_entry_rcu(ptype, &ptype_all, list) {if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } list_for_each_entry_rcu(ptype, &skb->dev->ptype_all, list) {if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } ......if (likely(!deliver_exact)) { deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &ptype_base[ntohs(type) & PTYPE_HASH_MASK]); } ......}static inline void deliver_ptype_list_skb(struct sk_buff *skb, struct packet_type **pt, struct net_device *orig_dev, __be16 type, struct list_head *ptype_list){struct packet_type *ptype, *pt_prev = *pt; list_for_each_entry_rcu(ptype, ptype_list, list) {if (ptype->type != type)continue;if (pt_prev) deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } *pt = pt_prev;}
static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc, struct packet_type **ppt_prev){ ......//抓包 list_for_each_entry_rcu(ptype, &ptype_all, list) {if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } list_for_each_entry_rcu(ptype, &skb->dev->ptype_all, list) {if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } ......if (likely(!deliver_exact)) { deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &ptype_base[ntohs(type) & PTYPE_HASH_MASK]); } ......}static inline void deliver_ptype_list_skb(struct sk_buff *skb, struct packet_type **pt, struct net_device *orig_dev, __be16 type, struct list_head *ptype_list){struct packet_type *ptype, *pt_prev = *pt; list_for_each_entry_rcu(ptype, ptype_list, list) {if (ptype->type != type)continue;if (pt_prev) deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } *pt = pt_prev;}函数 deliver_ptype_list_skb 会从数据包中取出协议信息,然后遍历注册在这个协议上的回调函数列表。ptype_base 是一个 hash table,在协议初始化小节我们提到过,ip_rcv 函数地址就是存在这个 hash table中的。
//net/core/dev.cstatic inline int deliver_skb(struct sk_buff *skb, struct packet_type *pt_prev, struct net_device *orig_dev){ ......return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);}pt_prev->func 这一行就调用到了协议层注册的处理函数了。对于 ip 包来讲,就会进入到 ip_rcv(如果是 arp 包的话,会进入到 arp_rcv)。
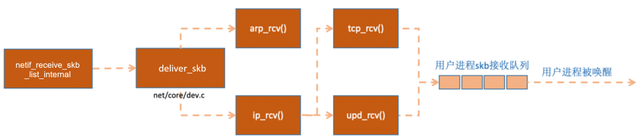 IP协议层处理
IP协议层处理 //net/ipv4/ip_input.cint ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev){struct net *net = dev_net(dev); skb = ip_rcv_core(skb, net);if (skb == )return NET_RX_DROP;return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, net, , skb, dev, , ip_rcv_finish);}
//net/ipv4/ip_input.cint ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev){struct net *net = dev_net(dev); skb = ip_rcv_core(skb, net);if (skb == )return NET_RX_DROP;return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, net, , skb, dev, , ip_rcv_finish);}这里NF_HOOK是一个钩子函数,当执行完注册的钩子后就会执行到最后一个参数指向的函数 ip_rcv_finish。
ip_rcv_finish->dst_input->ip_local_deliver->ip_local_deliver_finishstatic int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb){ skb_clear_delivery_time(skb); __skb_pull(skb, skb_network_header_len(skb)); rcu_read_lock(); ip_protocol_deliver_rcu(net, skb, ip_hdr(skb)->protocol); rcu_read_unlock();return 0;}void ip_protocol_deliver_rcu(struct net *net, struct sk_buff *skb, int protocol){ ...... ret = INDIRECT_CALL_2(ipprot->handler, tcp_v4_rcv, udp_rcv, skb); ......}在这里 skb 包将会进一步被派送到更上层的协议中,udp 和 tcp。
UDP协议层处理 udp协议的处理函数是 udp_rcv。//net/ipv4/udp.cint udp_rcv(struct sk_buff *skb){return __udp4_lib_rcv(skb, &udp_table, IPPROTO_UDP);} 应用层处理
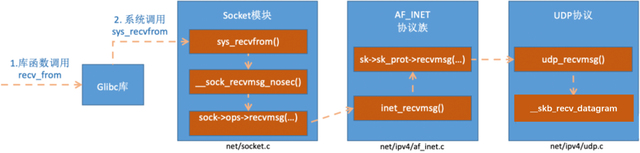
应用层处理通过开头的应用程序,我们知道应用层的数据接收函数是 recvfrom,recvfrom 是一个glibc的库函数,该函数在执行后会将用户进行陷入到内核态,进入到Linux实现的系统调用 sys_recvfrom。
在理解 sys_revvfrom之前,我们先来简单看一下socket这个核心数据结构。

socket数据结构中的const struct proto_ops对应的是协议的方法集合。每个协议都会实现不同的方法集,对于IPv4 Internet协议族来说,每种协议都有对应的处理方法,如下。对于udp来说,是通过inet_dgram_ops来定义的,其中注册了inet_recvmsg方法。
//net/ipv4/af_inet.cconst struct proto_ops inet_stream_ops = { ...... .recvmsg = inet_recvmsg, .mmap = sock_no_mmap, ......}const struct proto_ops inet_dgram_ops = { ...... .sendmsg = inet_sendmsg, .recvmsg = inet_recvmsg, ......}socket数据结构中的另一个数据结构struct sock *sk是一个非常大,非常重要的子结构体。其中的sk_prot又定义了二级处理函数。对于UDP协议来说,会被设置成UDP协议实现的方法集udp_prot。
//net/ipv4/udp.cstruct proto udp_prot = { .name = "UDP", .owner = THIS_MODULE, .close = udp_lib_close, .connect = ip4_datagram_connect, ...... .sendmsg = udp_sendmsg, .recvmsg = udp_recvmsg, .sendpage = udp_sendpage, ......}看完了 socket 变量之后,我们再来看 sys_revvfrom 的实现过程。
 总结
总结首先在开始收包之前,Linux要做许多的准备工作:
创建ksoftirqd线程,为它设置好它自己的线程函数,后面指望着它来处理软中断呢协议栈注册,linux要实现许多协议,比如arp,icmp,ip,udp,tcp,每一个协议都会将自己的处理函数注册一下,方便包来了迅速找到对应的处理函数网卡驱动初始化,每个驱动都有一个初始化函数,内核会让驱动也初始化一下。在这个初始化过程中,把自己的DMA准备好,把NAPI的poll函数地址告诉内核启动网卡,分配RX,TX队列,注册中断对应的处理函数当上面都ready之后,就可以打开硬中断,等待数据包的到来了:
网卡将数据帧DMA到内存的RingBuffer中,然后向CPU发起中断通知CPU响应中断请求,调用网卡启动时注册的中断处理函数中断处理函数几乎没干啥,就发起了软中断请求内核线程ksoftirqd线程发现有软中断请求到来,先关闭硬中断ksoftirqd线程开始调用驱动的poll函数收包poll函数将收到的包送到协议栈注册的ip_rcv函数中ip_rcv函数再讲包送到udp_rcv函数中(对于tcp包就送到tcp_rcv)