这是一个系列教程/笔记本,旨在提供一个将 PDF 转换为播客的工作流程参考或课程。
您还可以从使用文本转语音模型的实验中学习相关知识。
该教程假设读者对大型语言模型(LLMs)、提示词和音频模型毫无基础知识,每个知识点都在相应的笔记本中详细涵盖。
目录:以下是逐步完成任务的思路:
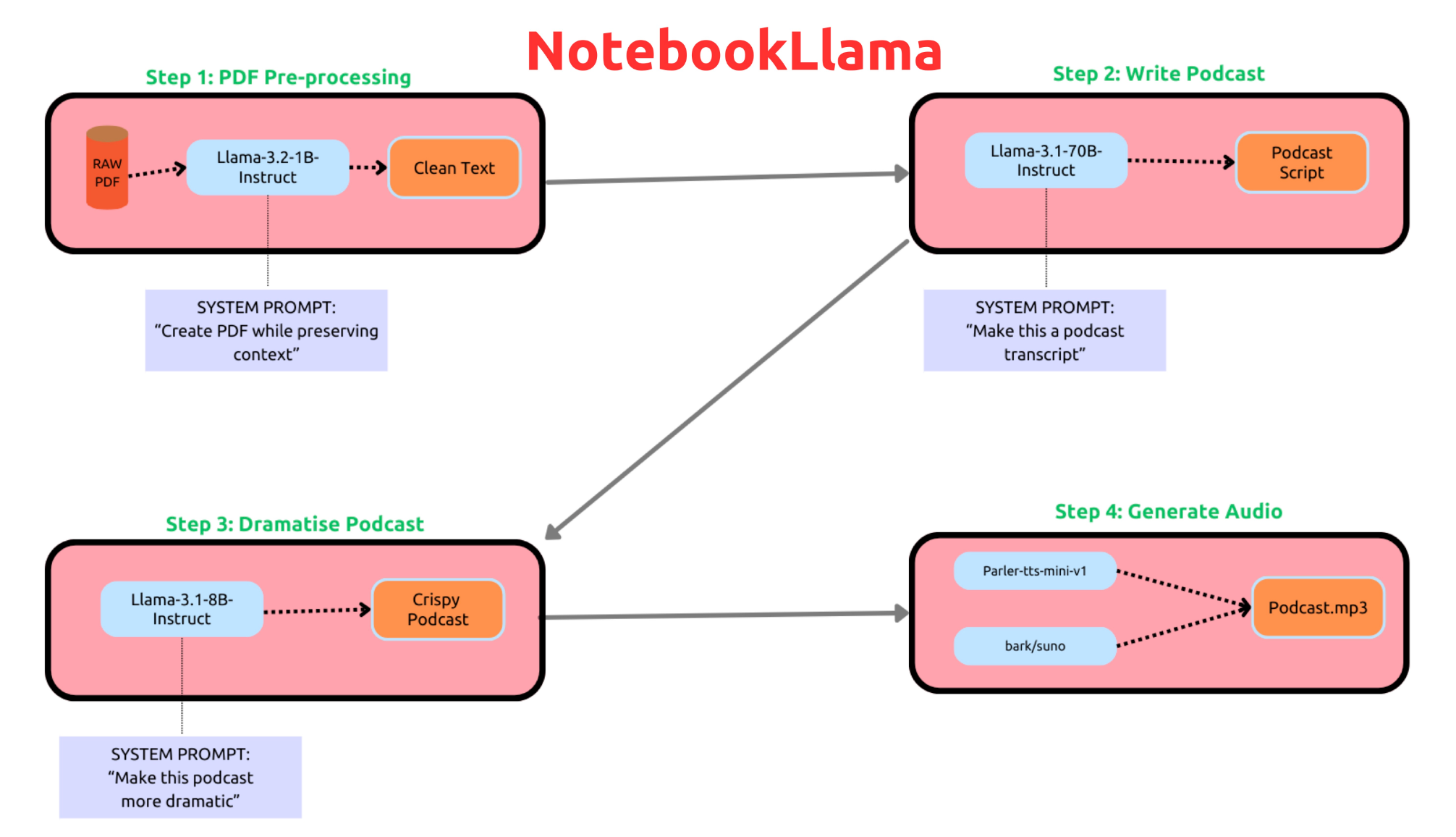
步骤 1:预处理 PDF:使用 Llama-3.2-1B-Instruct 模型预处理 PDF,并将其保存为 .txt 文件。
步骤 2:编写播客脚本:使用 Llama-3.1-70B-Instruct 模型从文本中生成播客脚本。
步骤 3:戏剧化重写:使用 Llama-3.1-8B-Instruct 模型,使脚本内容更加富有戏剧性。
步骤 4:文本转语音工作流:使用 parler-tts/parler-tts-mini-v1 和 bark/suno 模型生成对话形式的播客。
注释 1:在步骤 1 中,我们提示 1B 模型不要修改文本或进行总结,仅需清理编码导致的多余字符或乱码。更多细节请参见笔记本 1 的提示。
注释 2:在步骤 2 中,您还可以使用 Llama-3.1-8B-Instruct 模型。我们推荐您尝试不同模型并进行比较。之所以选择 70B 模型,是因为在测试示例中,该模型生成的播客脚本更具创造性。
注释 3:在步骤 4 中,建议尝试使用其他模型。这些模型基于特定提示选择,在测试中效果最佳,但可能有更新模型效果更佳。详细测试请参阅说明。
运行笔记本的详细步骤:要求:需具备 GPU 服务器或能够调用 70B、8B 和 1B Llama 模型的 API 服务。运行 70B 模型时需 GPU 集成内存约 140GB,才能在 bfloat-16 精度下推理。
注意:对于 GPU 资源较少的用户,可以全程使用 8B 或更低模型。以下流程基于测试中的最佳效果,但具体效果因配置不同可能有所不同,请自行尝试!
在开始之前,请使用 huggingface cli 登录,并启动 Jupyter Notebook 服务器,以便下载所需的 Llama 模型。
您将需要 Hugging Face 的访问令牌,可在设置页面获取。运行 huggingface-cli login,粘贴访问令牌完成登录,以确保脚本可以下载 Hugging Face 模型。
首先,从这里安装所需依赖,运行以下命令:
git clone https://github.com/meta-llama/llama-recipescd llama-recipes/recipes/quickstart/NotebookLlama/pip install -r requirements.txt
笔记本 1:
本笔记本用于处理 PDF,并使用新的 Feather light 模型将其转换为 .txt 文件。
在第一个代码单元格中输入所需 PDF 链接。请自行选择 PDF,并更新笔记本中的链接。
尝试修改 Llama-3.2-1B-Instruct 模型的提示,看看能否优化结果。
笔记本 2:
本笔记本将处理后的文本转换为创意性的播客脚本,使用 Llama-3.1-70B-Instruct 模型。如有强大 GPU 资源,可测试 405B 模型!
请尝试更改系统提示词,查看效果是否有所提升,并使用 8B 模型测试对比。
笔记本 3:
此笔记本从上一部分的脚本生成结果中调用 Llama-3.1-8B-Instruct,为对话增加戏剧性和停顿。
关键之处在于,我们将对话生成成元组形式,后续处理更加便利。数据结构基础知识在此派上用场了!
在文本转语音逻辑中,我们使用两种不同模型,针对不同提示词各有表现。因此,为每个角色单独定制提示。
请继续尝试更改系统提示,查看结果,并在此阶段测试 feather light 3B 和 1B 模型。
笔记本 4:
最后,将前面生成的内容转换为播客。我们使用 parler-tts/parler-tts-mini-v1 和 bark/suno 模型实现对话。
在选择 parler 模型的对话角色和提示时,基于模型作者的建议进行了实验。您可尝试不同方法,更多细节见资源部分。
注意:目前有一个问题:Parler 需要 transformers 4.43.3 或更早版本,而步骤 1 到 3 需要最新版本。因此在最后的笔记本中需要切换版本。进一步改进/未来的思路:语音模型实验:TTS 模型决定了播客的自然性。可以通过更好的流程和专业人士的帮助改进——欢迎贡献代码!
多 LLM 讨论:另一种生成播客脚本的方法是让两个代理讨论相关主题。目前使用的是单一 70B 模型编写播客大纲。
测试 405B 模型进行脚本创作
更优的提示词设计
支持导入网站、音频文件、YouTube 链接等。同样,欢迎社区贡献!