列表的排序,详见:https://docs.python.org/zh-cn/3.12/howto/sorting.html#sortinghowto
列表的排序,主要使用列表本身的sort方法和内置函数sorted。如官方文档所言,如果是对列表自身进行排序,不需要产生新的列表,那么采用列表的sort方法是更加高效的。如果需要产生新的列表,那么使用内置函数sorted反而是合适的。
列表本身的排序不是什么特别问题,特别的是需要解决实际应用中遇到的问题。现在我们有一个小想法,需要统计字符串中不同长度的子串出现的次数,并期望在较大样本空间内,计算不同子串出现的可能性(出现次数/样本空间总数)。上代码,见图1:
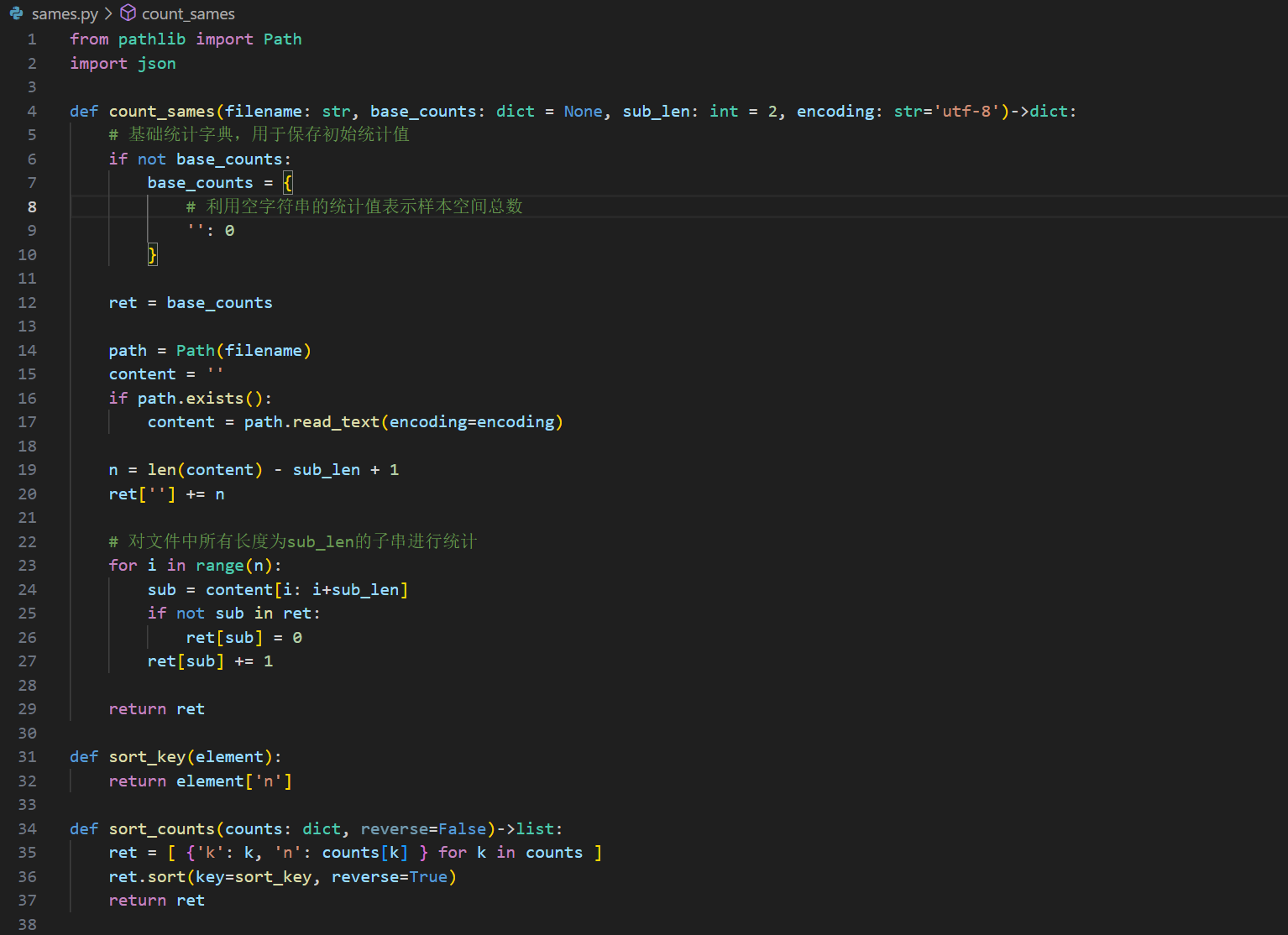
图1 统计指定长度子串存在个数的实现
自定义函数,count_sames(filename:str,base_counts:dict=None,sub_len:int=2,encoding:str='utf-8',reverse=False)的参数说明:
filename:数据文件
base_counts:基于的统计结果字典。在多个文件时,可以累加使用。
sub_len:子串长度
encoding:编码格式,这里采用utf-8编码
读取filename文件内容后,统计所有长度为sub_len相同子串的数量。
函数sort_counts(counts: dict, reverse=False),将相同子串统计的结果字典转换为列表的形式,元素为{k:子串,'n':个数}的字典对象(用tuple也可,这里是为了说明列表sort函数的key参数使用情况),其中利用列表的sort方法,指定排序所需关键字函数为sort_key函数(其内部返回了元素的'n'键的值)。需要注意的是,这里并不是比较函数(与其他语言不同),如果采用比较函数,需要使用python的functools.cmp_to_key对比较函数进行包装。
然后,我们将需要统计的字符串整体数据存放在了data.txt文件中。进行统计后,保存为本地的json文件。
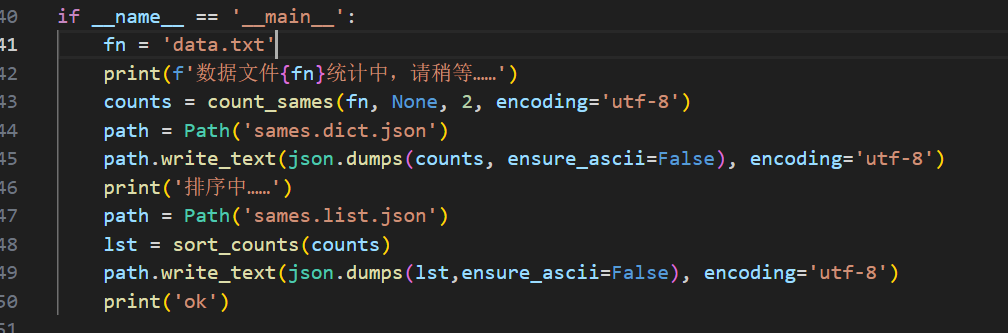
图2 统计后保存到本地文件

图3 排序后的列表结果
对2字符长度的统计可以看出,在200多万字符的数据中,排名靠前的“救援”、“车辆”、“亏电”等关键字,暴露了数据的内容,确实跟车辆救援相关,而且这些救援中对亏电车辆的救援占了绝大多数。如果想证明新的记录信息是类似车辆救援数据的话,提取数据、车辆、亏电三个维度的统计信息,相信能够接近答案。