可能你跟我一样头一次听说原子化CSS时,觉得写预设 听起来是一件极蠢的事,感觉这是在开倒车,因为我们都经历过 Bootstrap(其实不属于原子化) 的时代。
于是在这个概念刚刚在国内爆火的时候,我对其是嗤之以鼻的,当时我想象中的原子化:
只有带鱼屏才装得下。
而实际上的原子化:
在实际使用中,我们往往不会将所有的样式都使用原子化实现(当然也可以这么干)。
举一个例子,在你开发时,你按照自己习惯,做了一个近乎完美的布局,你的 已经写的非常棒,页面看起来赏心悦目,而此时,产品告诉你要在某个按钮的下面加一句提示,为了不破坏你的完美代码,又或者是样式无需太多的 css,你可能会选择直接写行内样式。此时原子化的魅力就体现了出来,只需要简单的寥寥几字,就把准确的 css 表达出来了,而无需再抽出一个无意义的。
为什么是 UnoCSS在 tailwindCSS、windiCSS 之后,一位长发飘飘的帅小伙,发布了一款国产原子化工具 UnoCSS。虽然大家可能很熟悉它,我还是想啰嗦几句。
UnoCSS 的优势CSS原子化在前端的长河中,可谓是一个婴儿:
“原子化 CSS”(Atomic CSS)的概念最早可以追溯到 2014 年,由 Nicolas Gallagher 在他的博客文章 “About HTML semantics and front-end architecture” 中提出。他在文章中提到了一种新的 CSS 方法论,即使用“单一功能类”(Single-purpose Classes)来替代传统的基于组件或块的样式管理方式。这种方法的核心思想是,将每一个 CSS 类设计为仅包含一种样式规则或一组简单的样式,以便更好地复用和组合样式,从而减少冗余代码。这一思想成为后来原子化 CSS 的基础。同年,第一个原子化框架 ACSS(Atomic CSS)发布了,由 Yahoo 团队开发。
ACSS 的推出激发了 Utility-First CSS 框架的兴起,最终在 Tailwind CSS 等项目中得到广泛应用。
Tailwind 和 Windi CSS 虽然也支持自定义,但它们的定制性主要体现在配置文件的扩展上,如自定义颜色、间距、字体、断点等,且在设计上仍然偏向于固定的原子类名体系。这两者可以通过配置文件生成新的实用类名,这种方式显然使他们有了不可避免的局限性。
而 UnoCSS 则有着高度定制化的特性,主要体现在它的灵活性和插件化设计,使其可以自由定义和扩展类名、行为,甚至能模拟其他 CSS 框架。相比之下,Tailwind CSS 和 Windi CSS 在设计上更偏向于固定的、基于配置的实用类体系,而 UnoCSS 则提供了更多自由度。
这样的设计也使得 UnoCSS 有着天然的性能优势,UnoCSS 支持基于正则表达式的动态类名解析,允许开发者定义自定义的样式规则。例如,可以通过简单的正则规则为特定样式创建动态的类,而不需要预先定义所有的类名。这使得 UnoCSS 的 CSS 小而精,据官网介绍,它无需解析,无需AST,无需扫描。它比Windi CSS或Tailwind CSS JIT快5倍!
原子化的通病从原子化的概念本身出发,我们不难发现,这种做法有一种通病,就是我除了要知道基本的 CSS 之外,还需要知道原子化类库的预定义值,也就是说,我们需要提前知道写哪些 是有效的,哪些是无法识别的。
在现代化编辑器中,我们可以使用编辑器扩展来识别这些类名。
比如在 VSCode 中的 UnoCSS 扩展

它可以在 HTML 中提示开发者这个类名下将解析出的 css

也可以进行自动补全。
是的这很方便,但是我们依旧要大概知道这些 预设 的写法,对其不熟悉的的用户,可能还要翻阅文档来书写。
全自动的 UnoCSS我就在想,为什么没有一个原子化库,可以支持智能识别呢,比如我想实现一个行高
按照上图中的预设,我需要依次打出 l、i、n、e、-,才匹配到了第一个和行高有关的属性,如果情况再搞笑一点,我根本不知道 line 怎么写怎么办?
我相信很多同学可能会有共情,因为我们在写传统 CSS 时,一般是打出我们自己熟悉的几个字母,依靠编辑器的自动补全(emmet)来做的,像这样:

嗯,看起来很舒服,只需要打出少量的字母,就可以识别到了。
先看一下传统的字面量 Uno 预设
传统预设
我们可以自定义一些个人比较熟悉的简写。
或者写一些正则,来支持更复杂的数值插入等
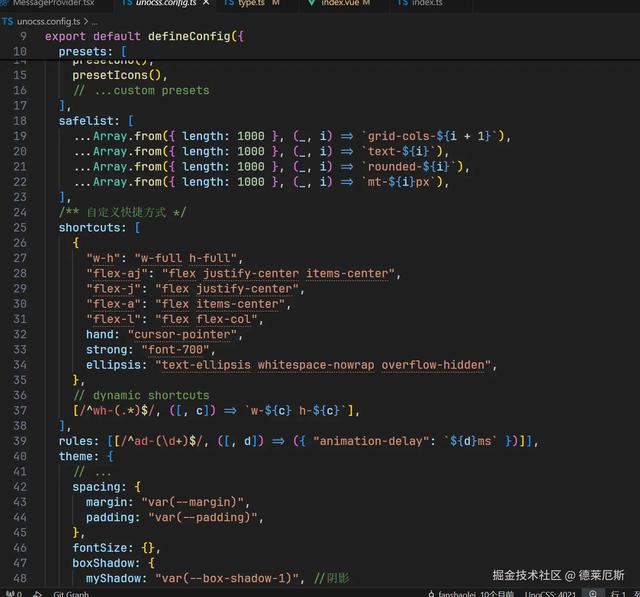
好吧,看到这我都上不来气儿了,这我要写到什么时候去?
确实,一个一个的去自定义规则,花费了非常多的精力和时间,那我们看一下社区有没有提供相对通用的规则呢, UnoCSS社区预设
好吧,可能有,但是太多了,且大多是一些个性化的实现。
autoUno 预设方案于是我准备手动做一个类似 emmet 补全的预设,希望它可以做到识别任意写法,比如:
line-height1pxlh24pxlh1lh1remlineh1lihei1...等等你习惯的写法正则拦截几乎所有写法字母+数字
/^[a-zA-Z]+(\d+)$/字母+数字+单位
/^[a-zA-Z]+(\d+)+(vh|vw|px|rem|em|%)$/字母+颜色
/^[a-zA-Z-]+(#[a-zA-Z0-9]+)$/字母+冒号+字母
/^[a-zA-Z]+:+[a-zA-Z]$/也就是说,我们的 rules 会长这样:
rules: [ [ /^[a-zA-Z]+(\d+)$/, ([a, d]) => { const [property, unit] = findBestMatch(a, customproperty) if (!property) return return { [property]: `${d || ''}${unit || ''}` } } ], [ /^[a-zA-Z]+(\d+)+(vh|vw|px|rem|em|%)$/, ([a, d, u]) => { const [property] = findBestMatch(a, customproperty) if (!property) return return { [property]: `${d || ''}${u}` } } ], [ /^[a-zA-Z-]+(#[a-zA-Z0-9]+)$/, ([a, c]) => { const [property] = findBestMatch(a, customproperty) if (!property) return return { [property]: c } } ], [ /^[a-zA-Z]+:+[a-zA-Z]$/, ([a]) => { const [property] = findBestMatch(a, customproperty) if (!property) return const propertyName = property.split(':')[0] const propertyValue = property.split(':')[1] return { [propertyName]: propertyValue } } ], ]接下来,只要实现 findBestMatch 方法就好了。
正如刚刚提到的,我们需要模拟一个 emmet 的提示,规则大概是这样的
匹配顺序一致至少命中 2 字符可以自定义单位那么我们可以先列举一下可能用到的 CSS 属性(全部大概有350个左右)
const propertyCommon = [ "display: flex", "display: block", "display: inline", "display: inline-block", "display: grid", "display: none", // "...":"..." 还有更多]比如我希望 输入 d:f 就自动帮我匹配到 display: flex 。
那么逻辑应该是这样的:
获取到第一个字符 d,让它分别去这些字符串中比较,比如 display: flex 将被分解成 d、i、s...
首先匹配到第一个字符 d 发现一致,那么 display: flex 的可能性就 + 1,整个遍历下来,顺序一致,且命中字符数最多的,就是我们要找的,很显然 输入 d:f 命中最多的应该是 display: flex ,分别是 d、:、f ,此时函数返回就正确了。
findBestMatch 方法实现除了刚刚列举的常用固定写法,还有一些带单位的属性,我选择用 $ 符号分割,以便于在函数中提取
const propertyWithUnit = [ "animation-delay$ms", "animation-duration$ms", "border-bottom-width$px", "border-left-width$px", "border-right-width$px", "border-top-width$px", "border-width$px", "bottom$px", "box-shadow$px", "clip$px", // ... 更多]我们在预设属性中,使用 $ 符号隔断了一个默认单位,一会将在函数中提取它。
export function findBestMatch(input: string, customproperty: string[] = []) { // 将输入字符串转换为字符数组 const inputChars = input.split('') let bestMatch: any = null let maxMatches = 0 // 遍历所有目标字符串 for (let keywordOrigin of customproperty.concat(propertyWithUnit.concat(propertyCommon))) { const keyword = keywordOrigin.split('$')[0] // 用来记录目标字符串的字符序列是否匹配 let matchCount = 0 let inputIndex = 0 // 遍历目标字符串 for (let i = 0; i < keyword.length; i++) { // 如果第一个字符就不匹配,直接跳过 if (i === 0 && keyword[i] !== inputChars[0]) { break } if (inputIndex < inputChars.length && keyword[i] === inputChars[inputIndex] && (input.includes(":") && keyword.includes(":") || (!input.includes(":")))) { matchCount++ inputIndex++ } } // 如果找到的匹配字符数大于等于 2,且比当前最大匹配数多 if (matchCount >= 2 && matchCount > maxMatches) { maxMatches = matchCount bestMatch = keywordOrigin } } let unit: any = '' // 用正则匹配单位,最后一个数字的后面的字符 const unitMatch = input.match(/(\d+)([a-zA-Z%]+)/) unit = unitMatch && unitMatch[2] if (!unit && bestMatch && bestMatch.split('$')[1]) { unit = bestMatch.split('$')[1] } return [bestMatch && bestMatch.split('$')[0], unit]}此函数使用了一种加分机制,去寻找最匹配的字符,当用户传入一个 时,将从第一个字符开始匹配,第一个不匹配直接跳过(遵循emmet规则,也有利于性能),接着,在是否加分的的 if 中,需要判断是否包含 : ,这是为了区分是否是带冒号的常用属性(区别于带单位的属性)。
在循环中,将找出最匹配的预设属性值,最后,判断用户输入的字符串是否带单位,如果带单位就使用用户单位,如果没有,就使用默认单位(预设属性中 $ 符号后面的字符)。
然后返回一个数组,它将是 [property,unit]
其实在上面的正则中,我将带单位和不带单位的匹配分开了,在写这篇文章时,findBestMatch 函数我还没想好怎么改,于是就先将就着讲给各位看,核心思想是一样的。
如此一来,我们无需自定义过多的固定 rules,只需要补充一些CSS属性就可以了,接下来你的UnoCSS 规则将长这样:
export default defineConfig({ presets: [ autoUno([ 'border-radius$px', "display:flex", "...." ])],})只需列举你将用到的标准css属性即可,含有数值的,以$符号分隔默认单位,其实你也无须过多设置,因为我的 autoUno 预设中已经涵盖了大部分常用属性,只有你发现 autoUno 无法识别你的简写时,才需要手动传入。
接下来,隆重介绍
autoUno
autoUno 是 UnoCSS 的一个预设方案,它支持你以最直觉的方式设置 。
你认为对,它就对,再也不受任何预设的影响,再也不用记下任何别人定义的习惯。
此项目已在 github 开源:github.com/LarryZhu-de…
此项目在 NPM 可供下载:www.npmjs.com/package/aut…
官方网站(可在线尝试):larryzhu-dev.github.io/autoLarryPa…
安装pnpm i autouno使用import { defineConfig } from 'unocss'import autoUno from 'autouno'export default defineConfig({ presets: [ autoUno([ "box-shadow:none", ])], })作者:德莱厄斯链接:https://juejin.cn/post/7435653910252191754