有一个列表数据:

description 有内容描述,name 是配置项的名字,parent 是配置项的父级项。
现在我希望输入 "图例 show",能从上述数据中筛选出描述内容有"图例",并且配置项名字是 show 的数据。注意上图中的 show 配置项,没有描述内容,要去自身父级项找。
也有可能一些数据只在 内容描述 中包含 "图例" 与 "show" ,此时也能输出,但是这些匹配的数据应该排在 配置项名字是 show 的数据 的后面。
也就是按积分权重搜索。你会怎么实现?
记住100个python技巧,远不如来一次实战。
实战内容是一个 echarts 配置代码生成工具。上一节我们已经把 echarts 的原始 json 数据整理好。

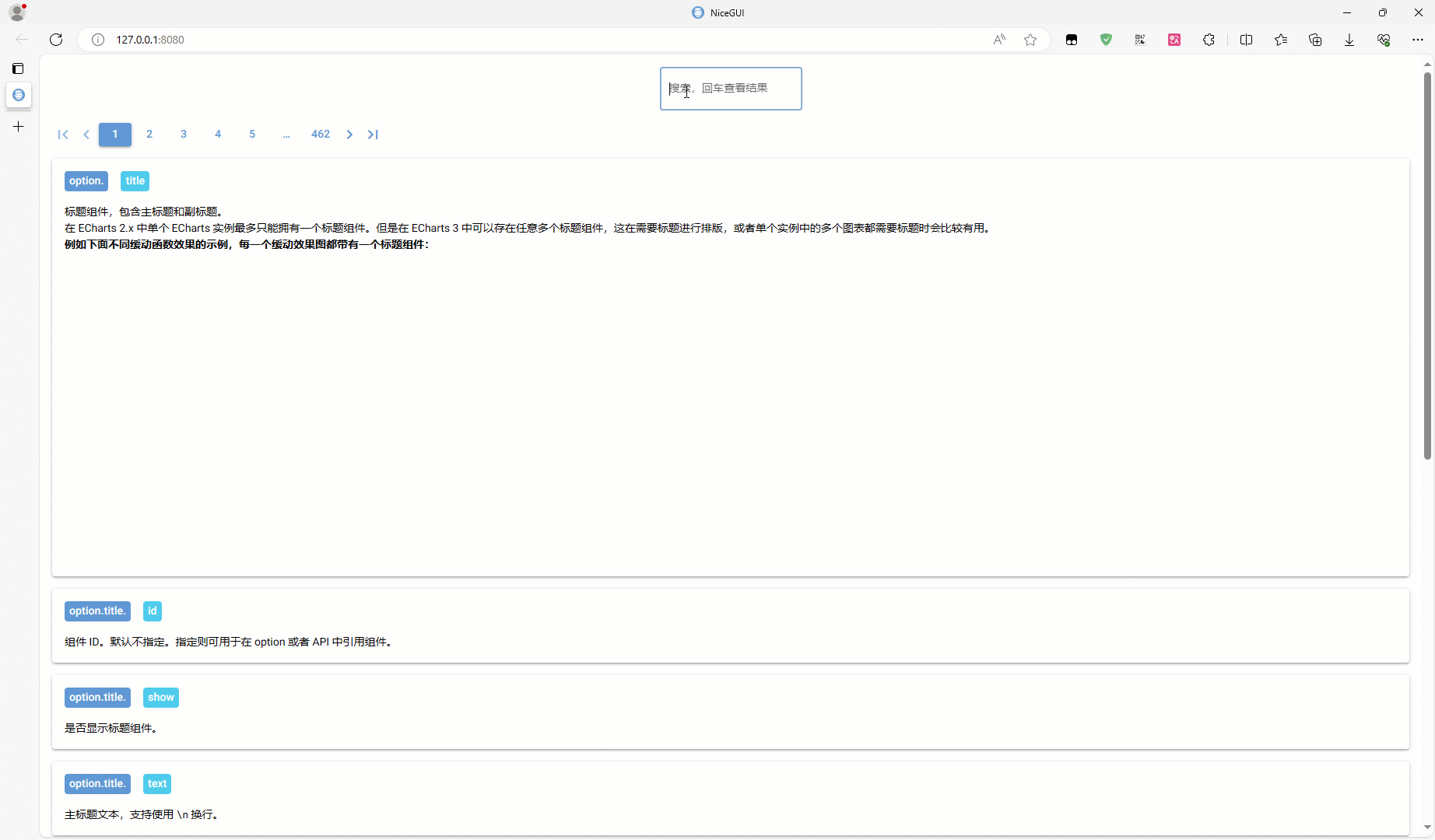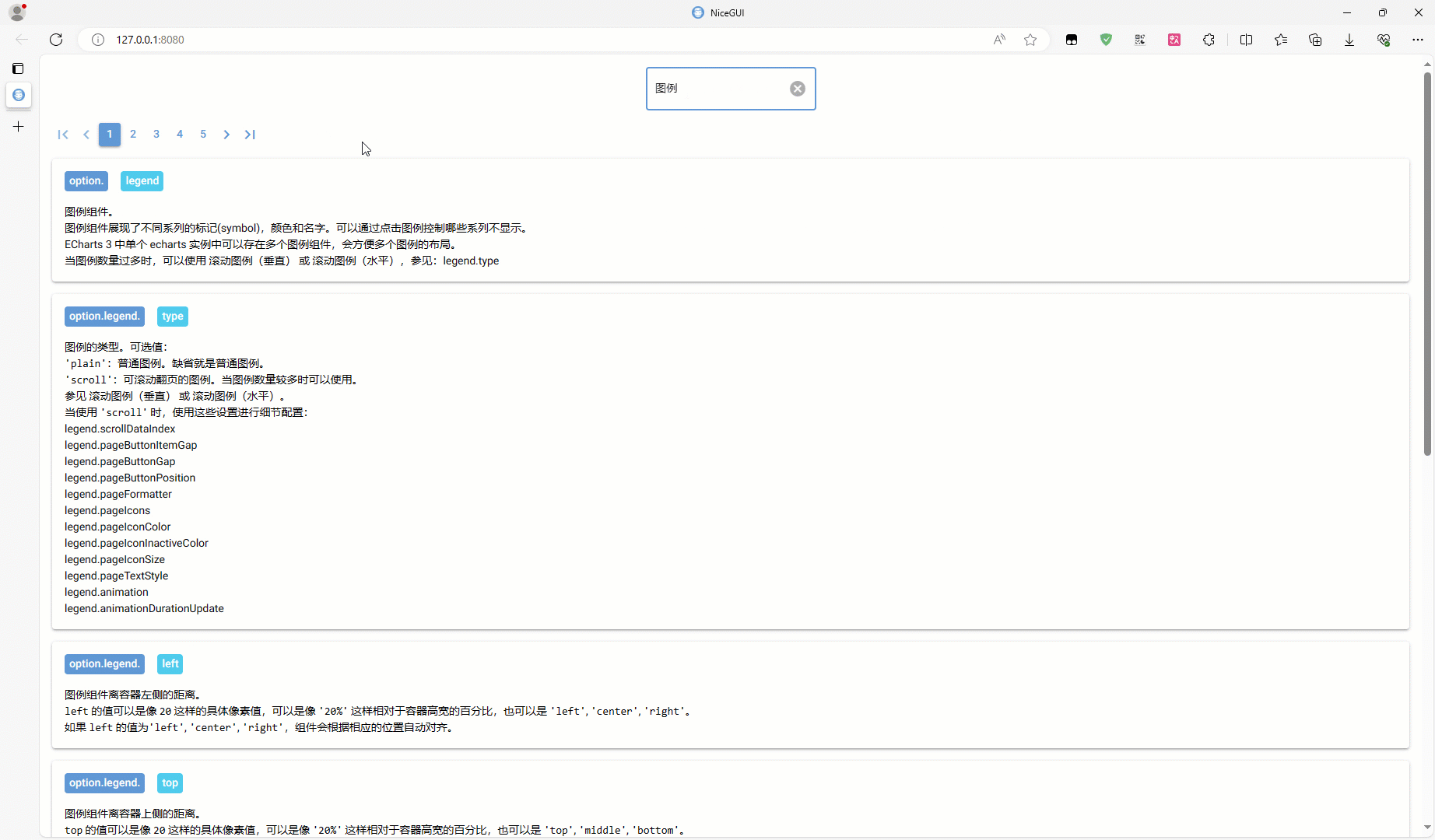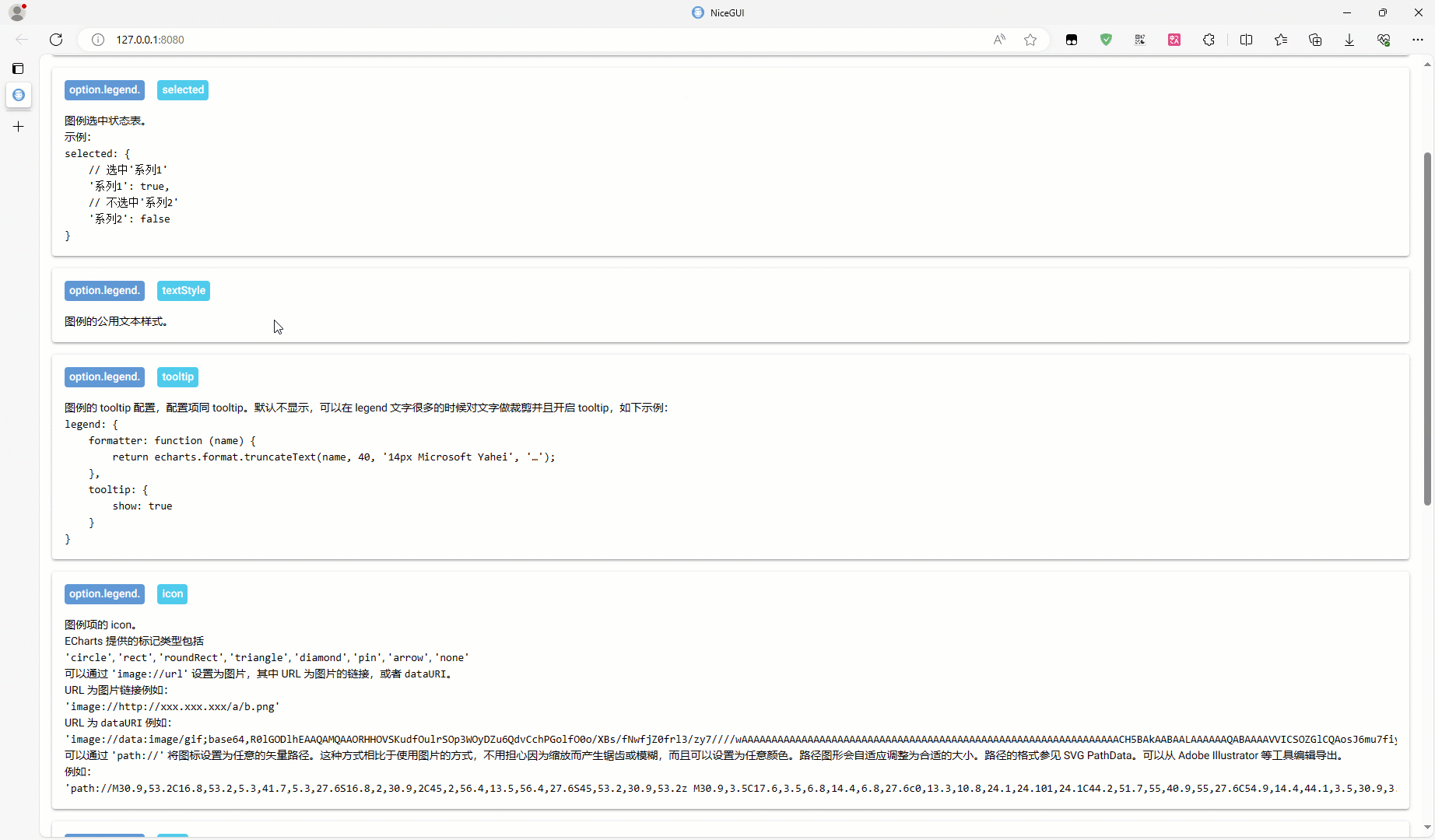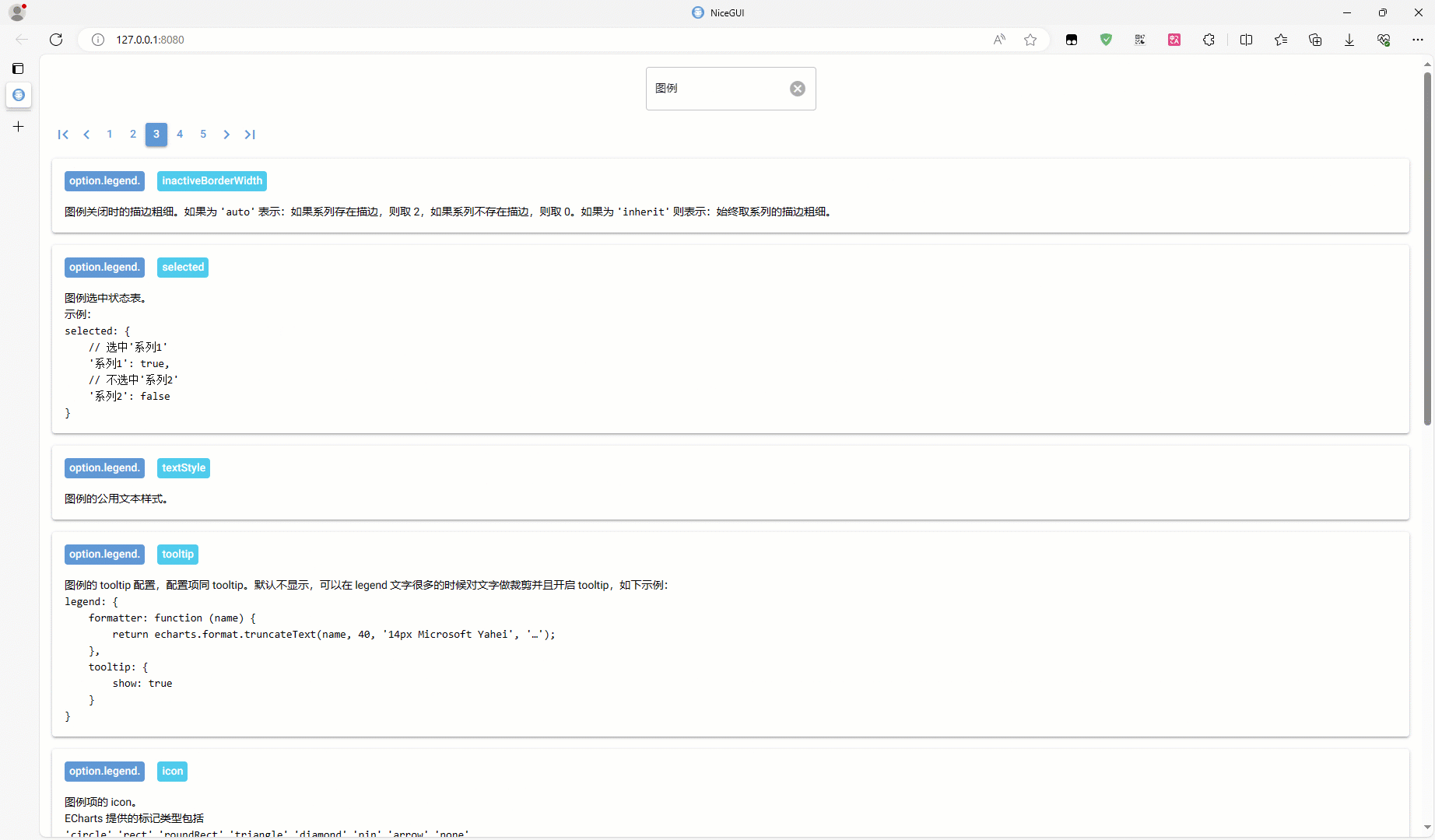
加载放到界面上,就是这个样子:

json 数据中的每一行,对应界面上的一个卡片

界面上方有一个输入框,输入后会针对某种方式进行搜索,符合的才显示
我们将实现积分权重搜索功能,从思路,代码组织开始,一步步实现。
不要忘记一键三连。你的点赞、收藏、关注,是我创作的动力。
先看项目的文件:

界面代码虽然不是今天的重点。但我们得知道, ui.py 文件里面全是关于界面的代码。里面总得获取数据吧。
同时,我们不希望界面代码中混杂过多的关于获取和处理后台数据的逻辑。所以,我们把处理后台数据的代码全放到 dataServices.py 文件里面

仅仅让 ui.py 中调用一个 get_items_by_search 的函数,获取符合条件的数据。在 ui.py 中的调用非常简单:

dataServices.py 可不管别人,只要专心完成 get_items_by_search 函数即可。

今天的任务就是完成 dataServices.py 模块
首先得到从 json 文件加载数据,一个函数搞定:
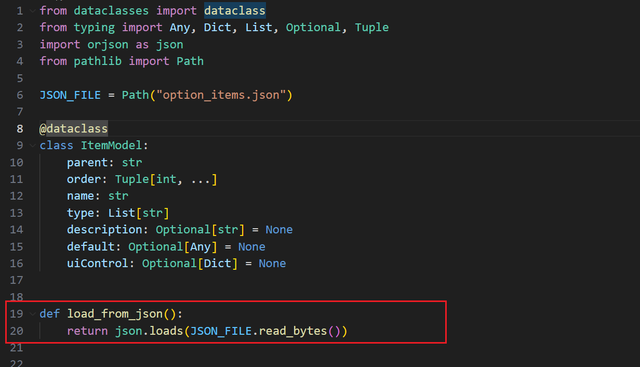
定义一个 get_items 函数,把 json 得到的一堆字典数据,转成数据对象,并且按原始顺序排序:
 数据类是上一节内容定义下来的,只要符合 json 数据的结构即可
数据类是上一节内容定义下来的,只要符合 json 数据的结构即可不使用数据类行不行?当然可以,只不过后续我们得操作一堆的字典数据,代码写起来可辛苦了。
接着就是大家都认为超级简单的搜索功能:遍历 + 判断:
 行29:调用刚刚写好的函数,获得数据行36:先简单实现搜索功能,只要描述文本中包含输入的搜索词,就列出来吧
行29:调用刚刚写好的函数,获得数据行36:先简单实现搜索功能,只要描述文本中包含输入的搜索词,就列出来吧现在,该怎么验证功能是否完成?要调用界面代码把整个程序跑起来吗?
显然不需要,我们新开一个 jupyter 环境,在里面调用。
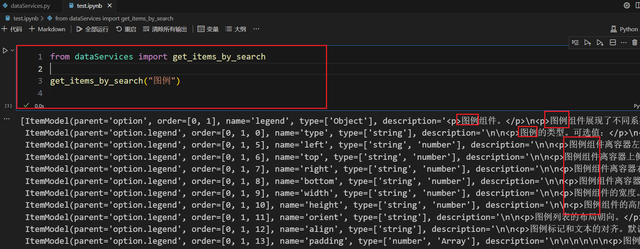
看起来还行。
注意,此时我们不需要依赖界面代码,即可测试基本功能是否完成。
功能完成了吗?还差远呢。
有时候我们希望搜索多个关键词,中间用空格断开,仍然可以搜索到结果。例如:

但目前的实现却会把整个文本整体去匹配:

怎么办?最直观的实现方式,按空格划分多个关键词。
回到功能函数代码
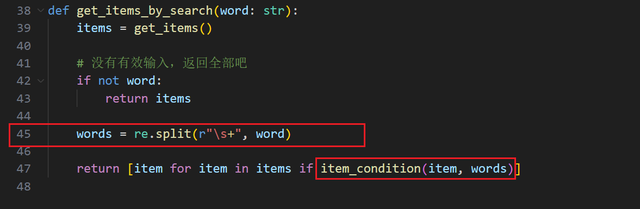 行45:用正则表达式按空格划分多个搜索词
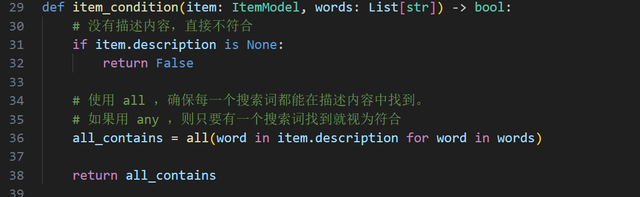
行45:用正则表达式按空格划分多个搜索词行47的 item_condition 是另一个函数,用于判断一条记录是否符合条件。看看它的实现:
再次测试一下,没问题了
注意需要重启 jupyter 环境,否则你会一直调用旧代码
这只是开胃菜,有时候我们希望同时去描述内容和配置项名字匹配,比如我希望搜索图例配置中是否显示的开关,输入“图例 show”,会发现只能找到 tooltip 的配置项:

如果我们到 echarts 官方网站搜索,一样无法找到 show 的配置项:

原来,有些配置项的描述根本没有任何内容:
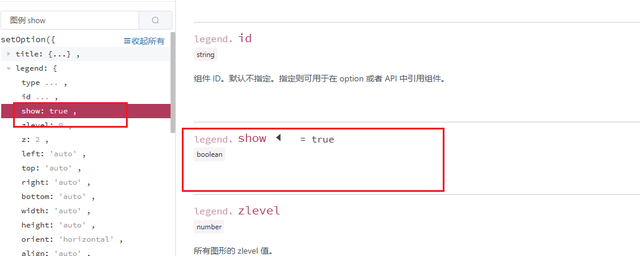
既然自己没有描述,那就到父级找吧:

现在开始有难度了,首先,我们实现一个通过路径搜索配置项的函数:
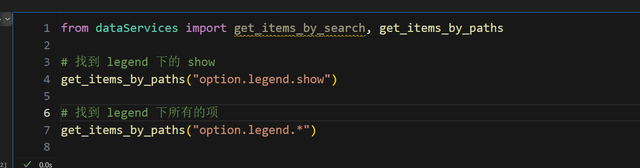
由于本身数据项里面就有 parent 和 name 信息,这个函数很容易实现:
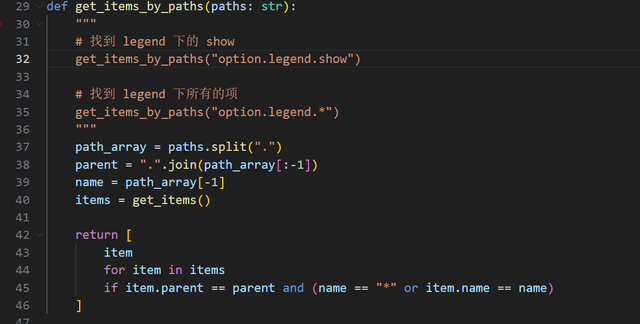
接着实现一个从父级找描述的功能函数:

即使有了这些,但是我们却很难描述哪些记录是符合条件的。

并且别忘记,我们可是希望符合条件的数据是有前后顺序的:
自身的描述有包含搜索词自身描述没有搜索词,但父级描述有或者两者都有搜索词本身命中了配置项的 name我们希望,上面的规则只要命中一条,就算符合,并且他们输出是有前后顺序(点4应该比点3输出展示更靠前)。
啊,有些数据可能命中上述的多条规则。
有没有一种方式可以同时描述优先级别,又能做筛选过滤的?其实很简单,我们对每一个数据项按一定规则打出一个分数。
分数低于一定阈值,则算不符合输出条件按分数高低排序 行82-90:修改搜索功能的函数,为每一项打分数并过滤排序
行82-90:修改搜索功能的函数,为每一项打分数并过滤排序我知道会有人说,这代码重复调用很影响性能。别急着优化!
现在剩下的重点就是完成"打分数"函数 cal_item_score ,先简单实现:

如果此时去此时最终的搜索功能,却发现:

非常慢,我们看看: 在按路径搜索的函数中,我们调用了 get items:

get_items 函数可是要从json文件中加载数据,这每一次计算数据项分数,都要重新加载一次数据,肯定慢。
很简单可以解决,打上缓存装饰器:
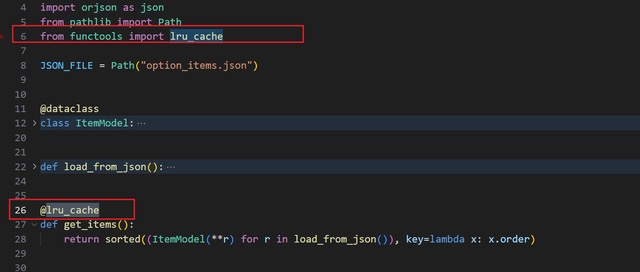
再次执行:

终于找到了 图例的 show,只不过它并不是排在第一位。这与我们的计算分数里面的系数有关系。这个后面再说,问题在于,这个查询仍然需要1.1秒。
我们再找一下有没有什么函数在循环中多次调用,并且调用时的参数很大机会是相同的,就可以做缓存:

cal_item_score 算吗,其实不算,因为 其中的 item 入参每个都不一样。

获取父级的描述内容,肯定会多次重复。可以打缓存。之后再次执行看看:

时间从 1.1 秒降到0.1秒。
此外,缓存不是没有代价的,比如我们可能希望只在一次搜索过程中缓存父级的描述内容,那么我们可以在每次搜索结束时,清除缓存:

现在还有一个问题,计算分数中的各项系数还没有调整好。这个你可以根据自己的需要调整。后面的教程我们将尝试实现启发式的计算分数。能够随着用户每次搜索的反馈,动态调整权重,让搜索结果能针对每个人有不一样的输出展示
转发、关注我,私信"实战",获得本期源码和数据。