前面的文章中,提到了关于Python中字符串中的相关操作,更多地涉及到了字符串的格式化,有些地方也称为字符串插值操作,本质上,就是把多个字符串拼接在一起,以固定的格式呈现。
关于字符串的操作,其实还有另外一种场景,就是从固定格式的字符串中,解析、提取出我们想要的信息。实际工作中,更常用的是从用户行为日志中提取出相关信息,从而进行行为模式的识别与分析,继而辅助引导后续的运营动作。
关于从字符串中提取出所需要的信息,在老手看来,最容易想到的大概就是使用正则表达式了。
但是,正则表达式对新手不太友好,而且可读性太差,即便是熟练掌握了正则表达式的老手,隔了一段时间,回看自己写的正则表达式,也会有些吃力。
本文我们快速略过正则表达式的用法,然后重点介绍通过好用的第三方模块,来实现常规场景下的字符串内容解析、提取的工作。
用户行为日志在系统的运营过程中,记录用户在系统中的各种访问行为,通过这些行为日志的提取、分析,学习出用户相关动作背后的特定模式,从而更好地实现产品的运营,留存用户、提高转化率等。
下面我们生成一些用户行为日志的测试数据,作为后续文本内容提取的输入,从而演示文本解析提取的运行效果。

生成的日志内容,如下:
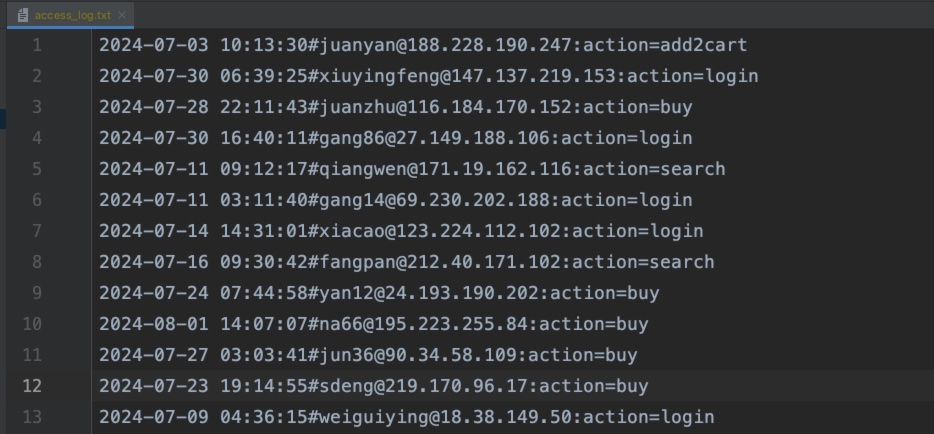
日志的格式为:
{访问时间}#{用户名}@{ip}:action={访问行为}
正则表达式由于正则表达式比较复杂,暂时不需要用到正则表达式,只有一些特殊复杂的文本解析提取,才可能考虑用正则表达式,这里,简单举个例子,从文本中提取出所有的ip字段:

输出结果:
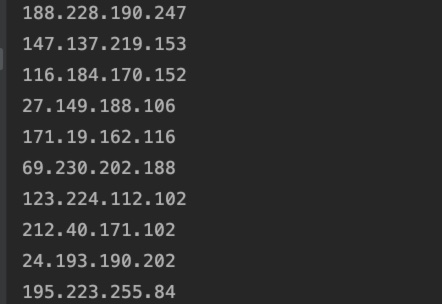
关于正则表达式不再展开,需要用到的时候再行查阅吧。
当然,不通过正则表达式,也可以实现这个需求,只需要做字符串的分割就行了。

除了正则表达式这个核武器,以及字符串分割的土方法。其实,还有更加灵巧、轻便的解决方案,这就要用到第三方模块parse。
安装三方模块,使用之前,需要先安装:
pip3 install parse
文档及源码地址https://github.com/r1chardj0n3s/parse
先来把前面的行为日志数据解析一下:

也可以通过关键字的形式,进行解析结果的提取:

前面解析日志中,我们只用到了parse模块中的parse()函数。
我们可以查看parse模块的源码,看下主要的功能:
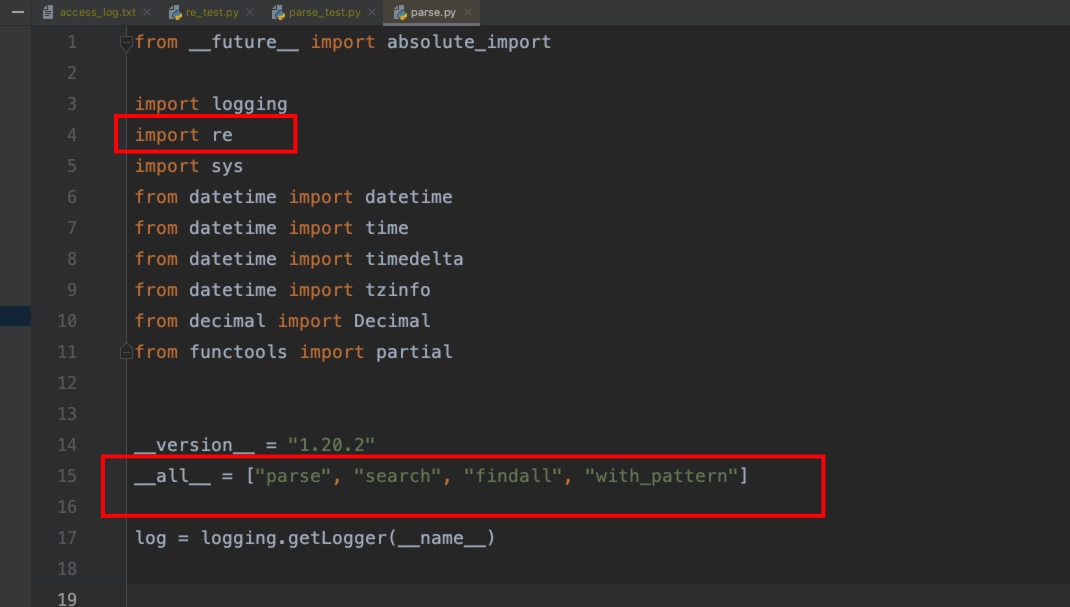
parse模块的实现,依赖了正则表达式模块。如同官网描述的一样,当我们通过:
from parse import *
只会导入4个函数:parse()、search()、findall()、with_pattern()。
关于这些函数的使用,感兴趣的可以查看源码自行研究。
其他模块其实,关于文本数据的解析、提取,除了re、parse外,还有其他模块,分别用于更多的场景中的文本解析、提取。比如HTML中的内容解析,可以使用lxml、beautifulsoup4,或者类似于jQuery的pyquery模块,也可以用于解析HTML文档。这些模块在通过爬虫采集相关数据时,会更加便捷。以后有机会,再进行相关的展开介绍。
