DeepMind发布Veo3论文谷歌称Veo3是视觉界GPT3时刻
DeepMind发布了Veo3论文,展示了Veo3在零样本(zero-shot)条件下完成多任务的能力,并称其为视频领域的通用基础模型(foundation model),以及"视觉推理领域的GPT-3时刻"。
文章提到,Veo3不仅能识别图像内容,还能理解物理规律,甚至完成类比推理和解迷宫任务,而且这些能力并非专门训练过的结果。
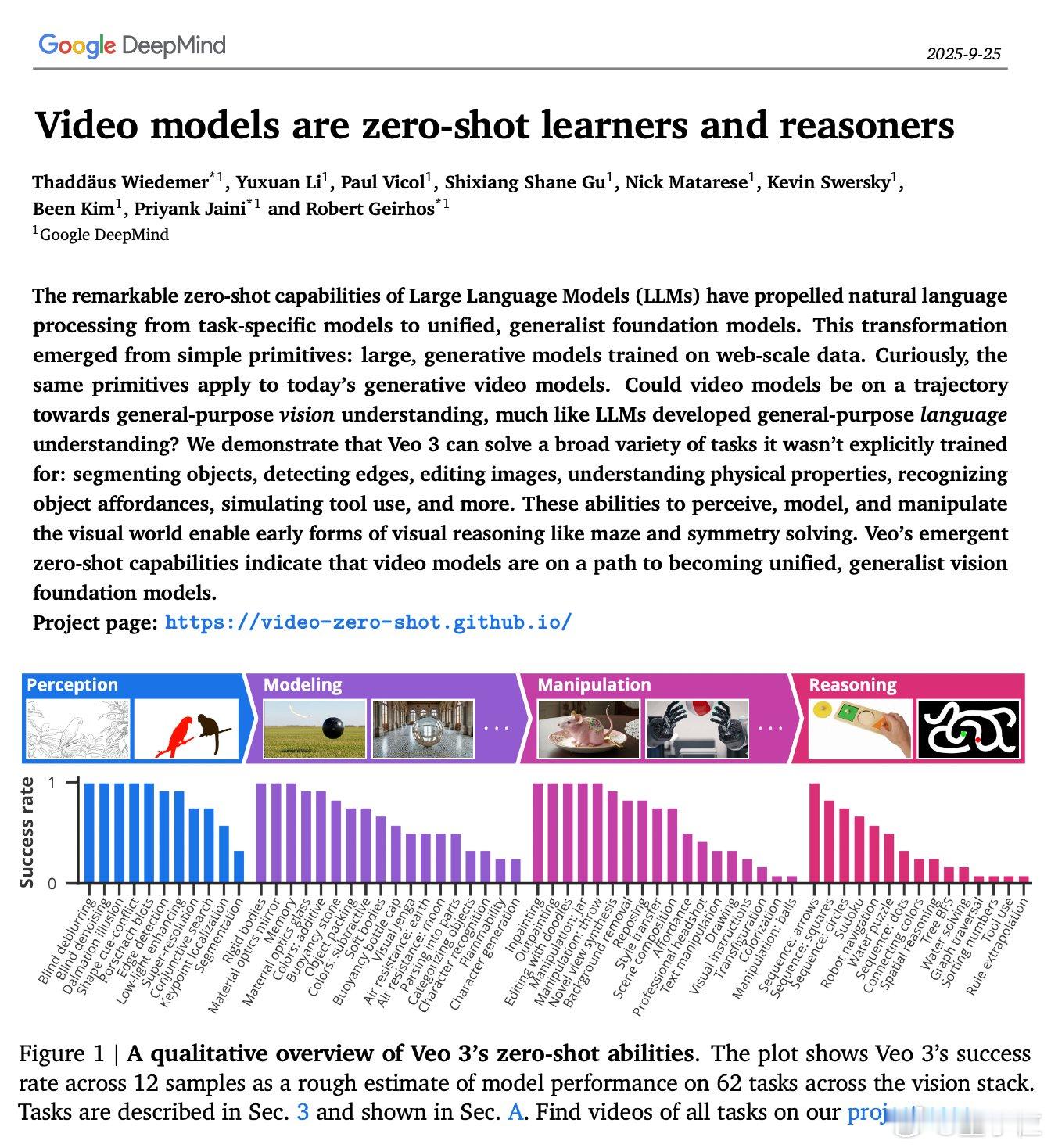
论文系统评估了Veo3在多个维度的表现,亮点包括:
感知能力:Veo3在边缘检测、图像分割、低光增强、超分辨率等经典视觉任务上表现出色,且完全无需微调。例如在BIPEDv2数据集上做边缘检测,效果甚至超过了人工标注。
物理建模:模型能够区分刚体与软体,理解重力差异(如地球与月球)、浮力、玻璃与镜子的光学特性,甚至可以判断一个物体是否能装进背包。
图像操作:支持背景移除、风格迁移、色彩修改、视角重建、3D换姿等操作,还能用自然语言或手势控制操作,如“打开瓶盖”或“给角色变装”。
视觉推理:可完成迷宫导航(5x5格内pass
推理机制创新:论文提出“帧链推理”(chain-of-frames),类似语言模型中的“思维链”(chain-of-thought)。模型通过视频帧序列逐步“思考”,实现对时间与空间的动态建模与推演。
性能提升明显:Veo3在各项任务上全面超越前代Veo2。在图像编辑保真度上,人工评价认为Veo3生成结果明显更精细。
泛化能力强:即便是从未训练过的任务,只需提供自然语言提示和首帧图像,Veo3也能给出“临场可用”的合理解法——包括线稿编辑、图案补全、抽象推理等。
成本问题正在缓解:虽然视频生成仍需大量算力,但论文指出推理成本正迅速下降,预计未来一年内成本可比LLM下降9至900倍。
能力边界清晰:Veo3在抽象类比(如旋转与镜像)和复杂规划(如搬运大型家具)等任务上仍存在短板,距真正的通用人工智能还有一定差距。
研究者指出,这种“zero-shot+多模态+时间建模”的组合路径,正是当年GPT-3能力爆发的关键要素。论文中甚至直接写道:
“我们正见证视频模型成为视觉领域通用基础设施的转折点,就像语言领域当年的GPT-3时刻一样。”
原文链接:arxiv.org/abs/2509.20328