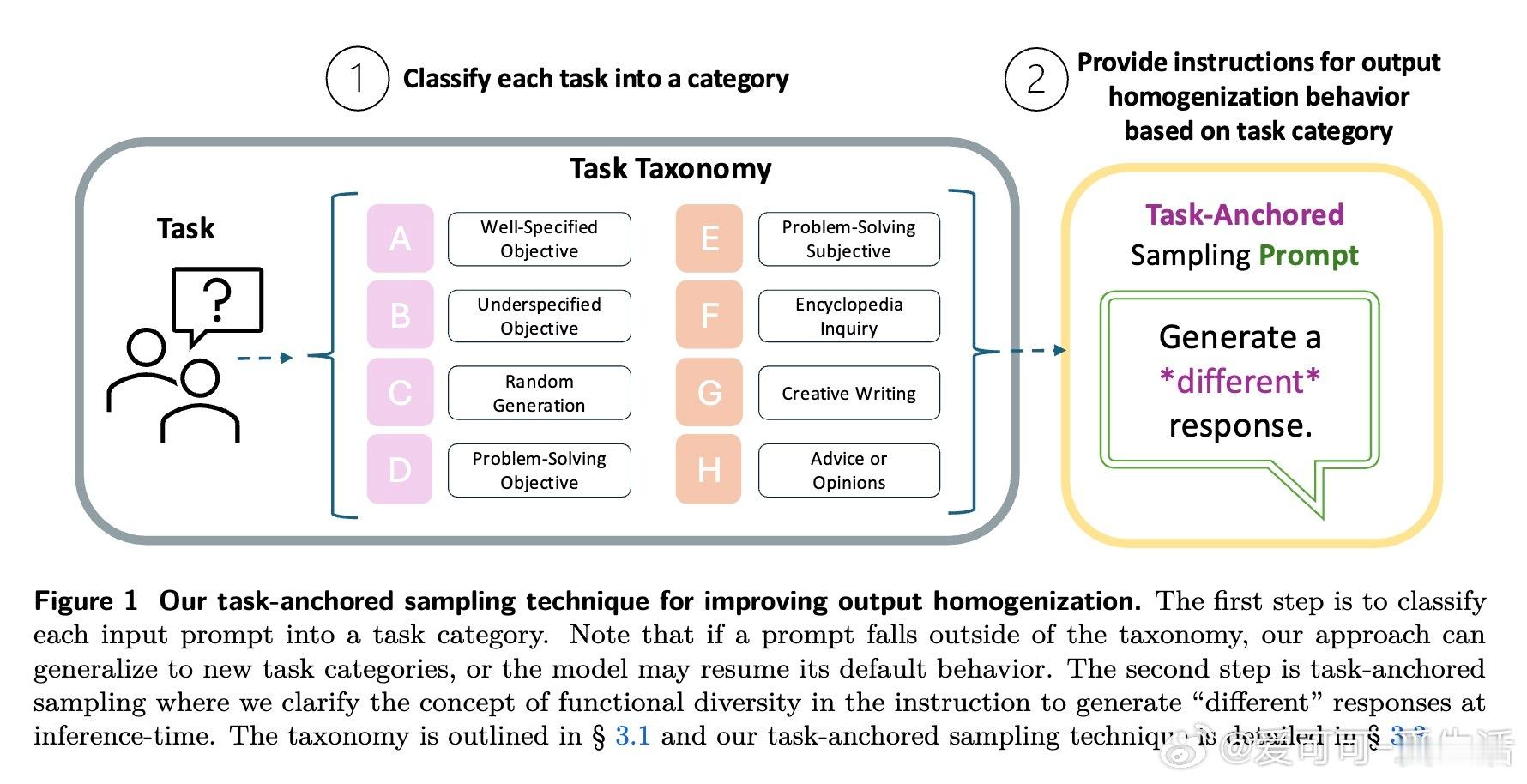
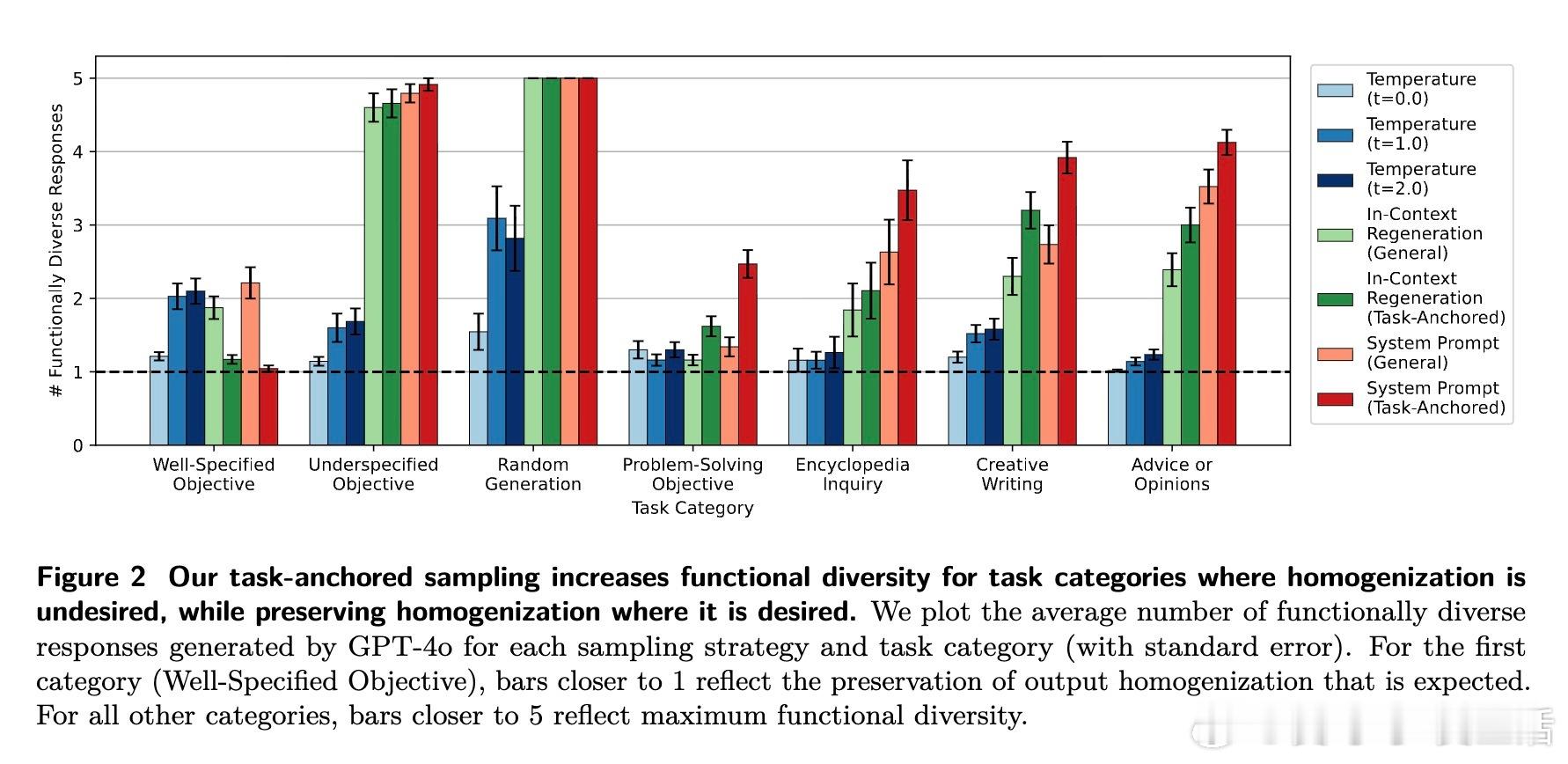
[CL]《LLM Output Homogenization is Task Dependent》S Jain, J Lanchantin, M Nickel, K Ullrich, A Wilson, J Watson-Daniels [FAIR at Meta] (2025)
输出同质化是否有害,关键取决于任务类型。Meta 与 MIT 联合团队最新研究提出基于任务分类的同质化评估与缓解框架,开创性地解决了大语言模型(LLM)输出多样性与质量的平衡难题。
• 任务细分:提出涵盖8大类任务的分类法,从单一确定性答案的数学问题到无限创造性的写作任务,精准界定何时需要保持输出一致,何时需提升多样性。
• 功能多样性指标:引入“任务锚定功能多样性”衡量方法,超越传统基于词汇或嵌入差异的泛化指标,更贴合实际任务需求。
• 任务锚定采样策略:创新采样指令设计,指导模型在不同任务类别下生成符合预期多样性的响应,既避免不必要的多样化,也促进必要的视角丰富。
• 挑战多样性-质量折中:实验证明,明确任务依赖的多样性提升策略不牺牲响应质量,颠覆以往普遍认为“多样性提升必然导致质量下降”的观点。
心得:
1. 多样性不是越多越好,理解任务本质才能精准调控输出多样性,提升用户体验和模型实用性。
2. 任务依赖的评估指标更能反映实际需求,促进模型在特定应用场景下表现更优。
3. 设计多样性策略时,清晰的任务指导可有效避免模型产生无意义或误导性的差异化回答。
了解如何通过任务依赖提升大语言模型输出多样性与质量👉 arxiv.org/abs/2509.21267
大语言模型输出多样性人工智能模型评估任务依赖