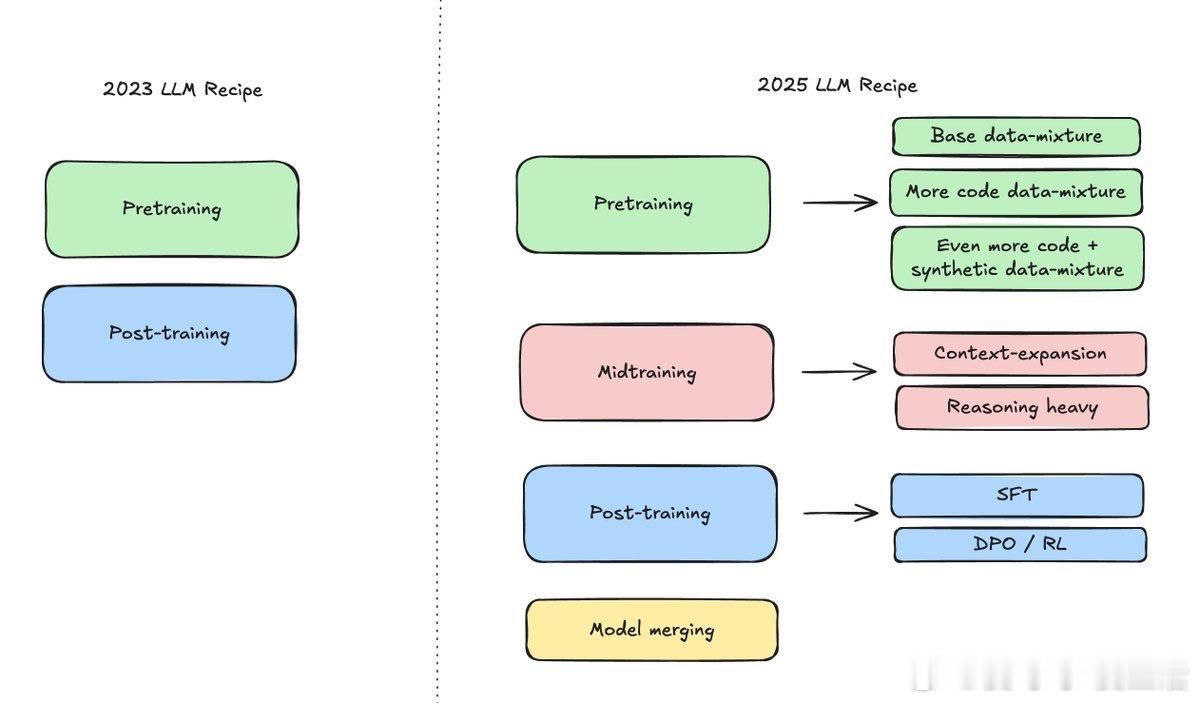
2023 年与 2025 年大语言模型训练对比,揭示了未来模型演进的关键转折:
• 2023 年训练主要分为两步:预训练(Pretraining)和后训练(Post-training),流程相对简单,数据混合和训练阶段较少。
• 2025 年训练加入了“中训练”(Midtraining)环节,显著丰富训练内容:
- 预训练阶段数据多样化,加入更多代码和合成数据,提升模型基础能力和代码理解力。
- 中训练阶段注重上下文扩展和强化推理能力,强化模型复杂任务处理能力。
- 后训练阶段细化为监督微调(SFT)和策略优化(DPO/RL),提升模型对复杂指令和反馈的适应性。
- 新增“模型合并”环节,实现不同模型优势融合,提升整体性能和泛化能力。
心得:
1. 未来训练更强调多阶段、多样化数据输入,基础能力和推理能力同步提升。
2. 中训练的加入打破传统两阶段框架,使模型在训练中期获得更丰富上下文理解。
3. 模型合并预示着多模型协同成为常态,单一模型训练渐退,融合策略将成性能提升关键。
2025 年训练流程更复杂但更高效,意味着大模型将跨越单一训练瓶颈,实现更智能、更灵活的表现。
大语言模型 机器学习 模型训练 AI发展 人工智能