[LG]《Optimal Learning from Label Proportions with General Loss Functions》L Applebaum, T Dick, C Gentile, H Kaplan... [Google] (2025)
学习标签比例的最佳方案:突破性低方差无偏估计,覆盖多种损失函数,兼顾二分类与多分类场景
• 解决部分监督学习中仅能获得样本组(bags)标签比例的问题,聚焦个体样本标签预测。
• 创新低方差去偏方法,估计方差独立于组大小k,极大提升样本效率,远优于以往随k线性增长的方差估计。
• 兼容广泛损失函数,支持二分类及多分类(包括全直方图与总计数两种聚合标签形式)。
• 采用Median-of-Means tournament算法,实现基于无偏估计的高置信度模型选择,理论样本复杂度达到最优k/β收敛速率。
• 多分类中,细粒度全直方图标签能维持类别数c无关的误差界,粗粒度总计数标签误差界随c²增长。
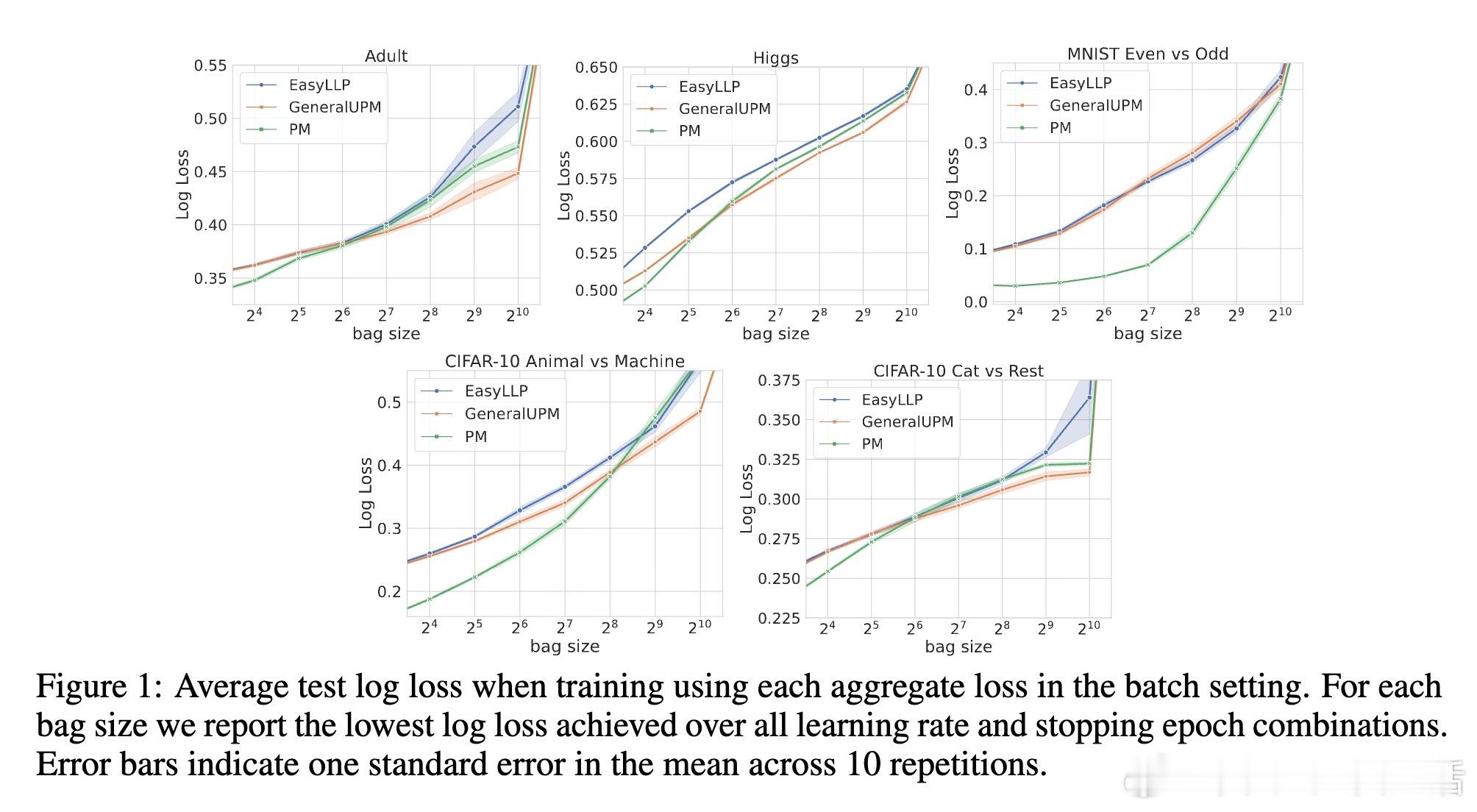
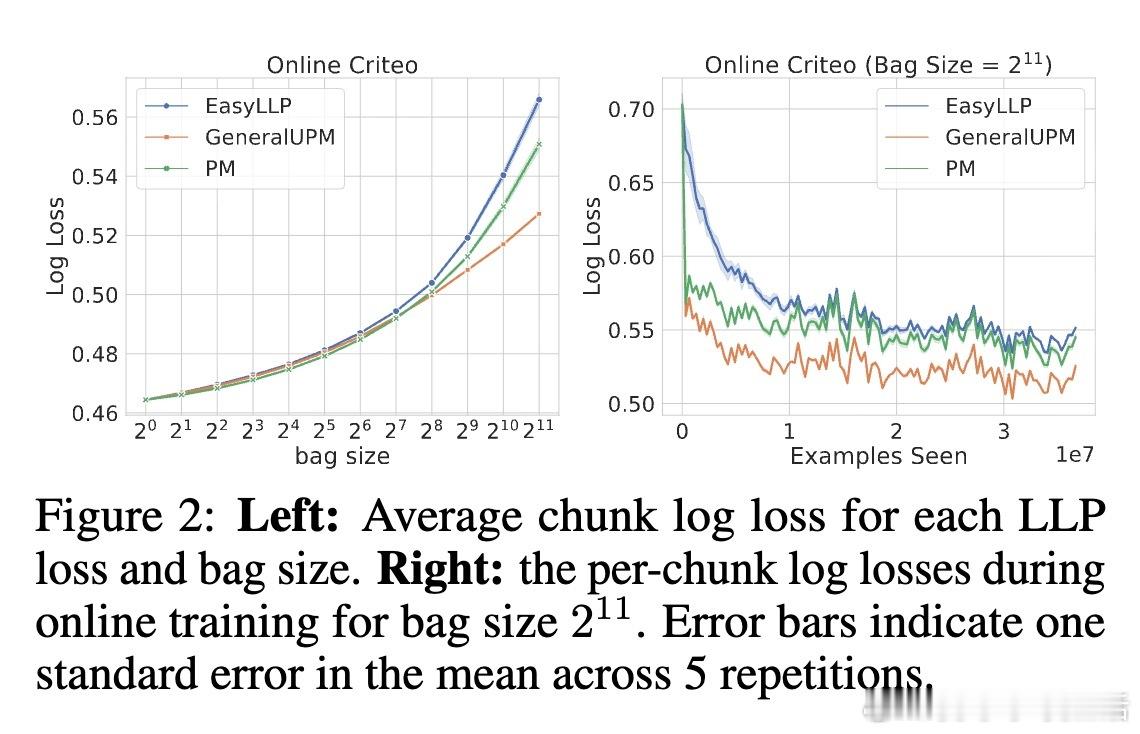
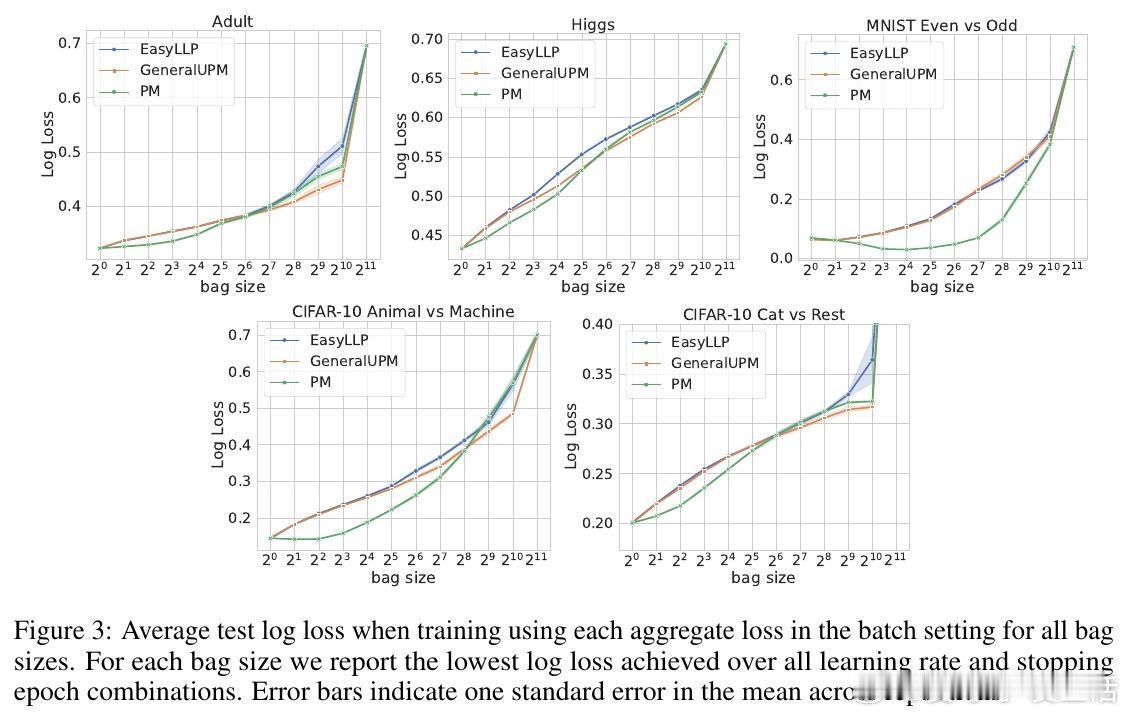
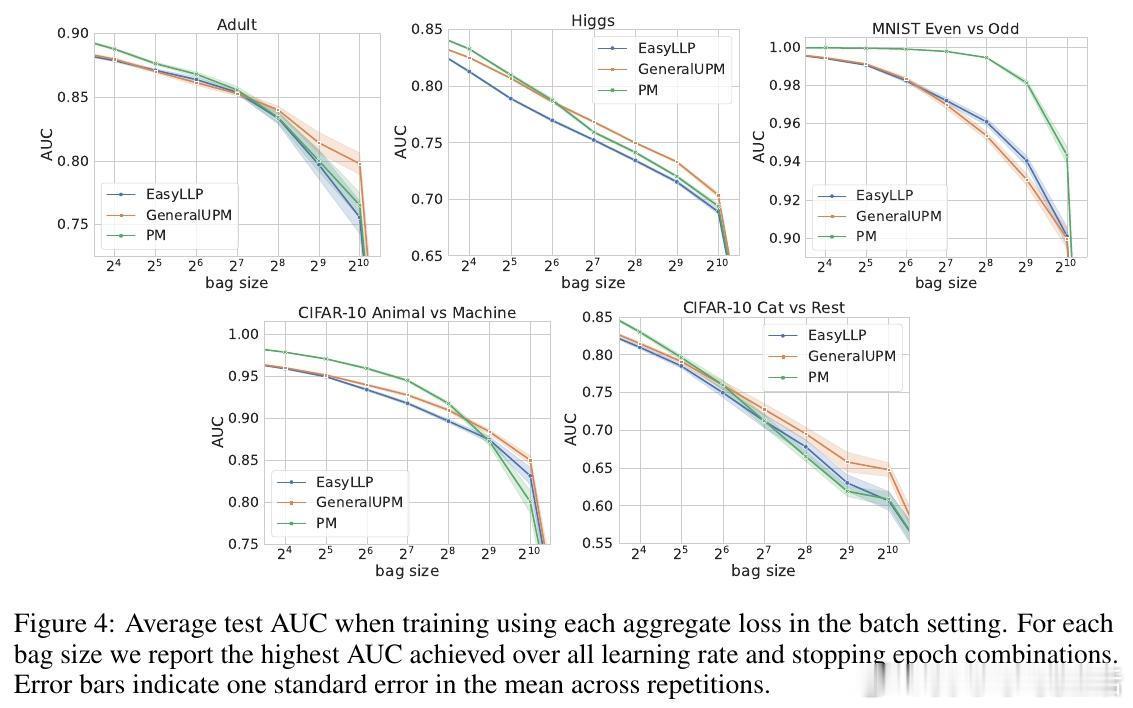
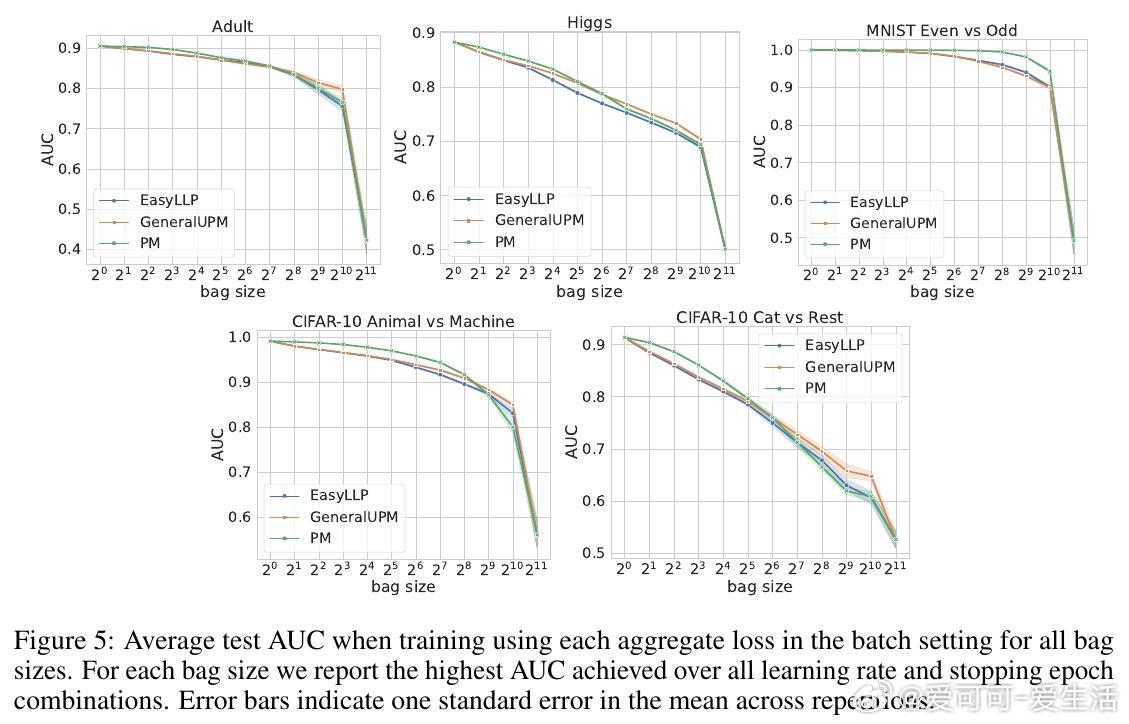
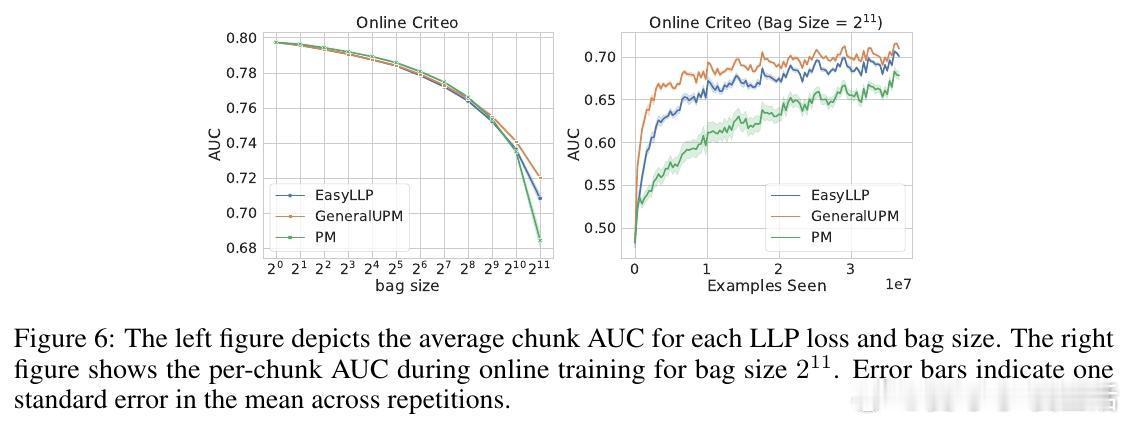
• 大规模在线广告转化率预测等实际任务中,实验验证该方法在大bag尺寸下显著优于EasyLLP和传统比例匹配基线,尤其在交叉熵损失优化上表现突出。
• 实验涵盖MNIST、CIFAR-10、Higgs、Adult和Criteo广告点击数据,支持深度神经网络训练,展现强泛化能力。
心得:
1. 聚合标签信息可逆转为无偏个体损失估计,且方差独立于bag大小,打破传统直觉中“信息越粗化,学习效果越差”的局限。
2. Median-of-Means策略对抗非均匀性和无界损失,实现鲁棒的高置信度模型选择,适合实际非理想分布。
3. 多分类中的标签粒度差异决定误差规模,启发设计更高效的标签采集和隐私保护机制。
详情🔗 arxiv.org/abs/2509.15145
机器学习弱监督学习标签比例学习在线广告统计学习理论低方差估计多分类