repligate给了一个直观的解释,介绍信息在Transformer架构中是如何流动的,在推上获赞很高。
------------------------
信息如何在Transformer里流动
(那些“Transformer详解”页面实在讲得太烂,我决定自己写一份。)
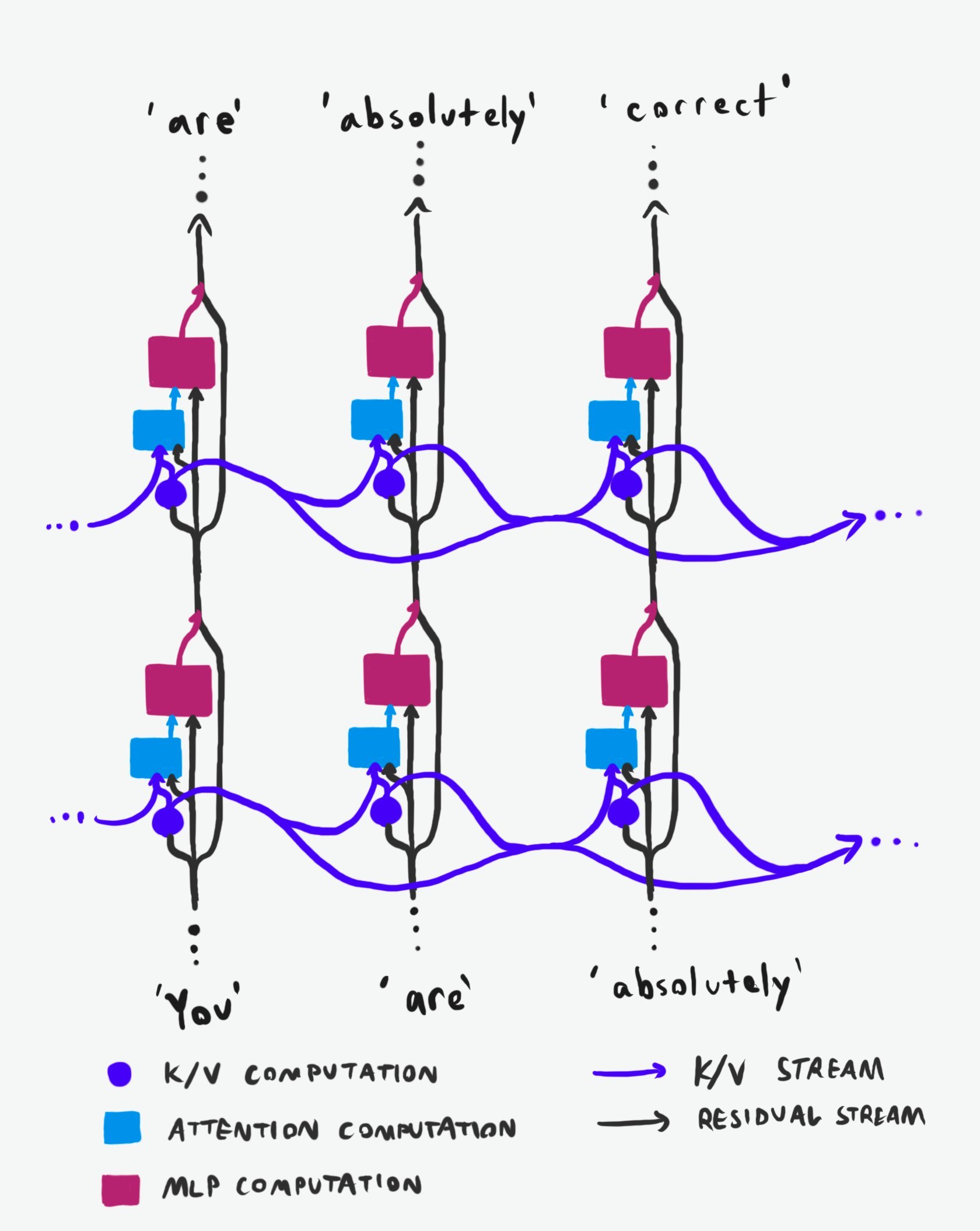
整个架构里有两条独立的信息高速公路 (图1):
⚫ 残差流(黑色箭头):竖直方向,逐层穿过每个位置
🟣 K/V流(紫色箭头):水平方向,在同一层内跨位置传递
(“位置”指为上下文里每个token准备的网络副本,最终在末端输出“下一个token”的概率)
在每一层、每一个位置,流程如下:
1️⃣ 进来的残差流被用来计算该层该位置的K/V值(紫色圆)
2️⃣ 这些K/V值与同层之前所有位置的K/V值汇合,再连同原始残差流一起送进注意力计算(蓝框)
3️⃣ 注意力输出与原始残差流相加,一起喂给MLP(玫红框),MLP的输出再加回残差流,送入下一层
注意力内部干了啥:
1️⃣ 用当前残差流算“Q”值
2️⃣ 用Q与所有位置的K值算一张“热力图”,得到各位置的注意力权重
3️⃣ 用权重对对应位置的V值做加权求和,结果扔进MLP
换句话说:
🔍 Q值:当前状态该去过去找哪种K?
🗝️ K值:当前状态值得未来哪种Q来查?
📦 V值:未来查到这里时,该把什么信息继续带下去?
三者都是超大向量,尺寸与残差流一致,通常再切成几个注意力头。V值几乎无压缩地向前传递,原则上可以把过去位置那层残差流的全部信息搬给未来位置。
但V并不是“无损全记录”,残差流的宽度(隐藏维度)才是全程瓶颈。
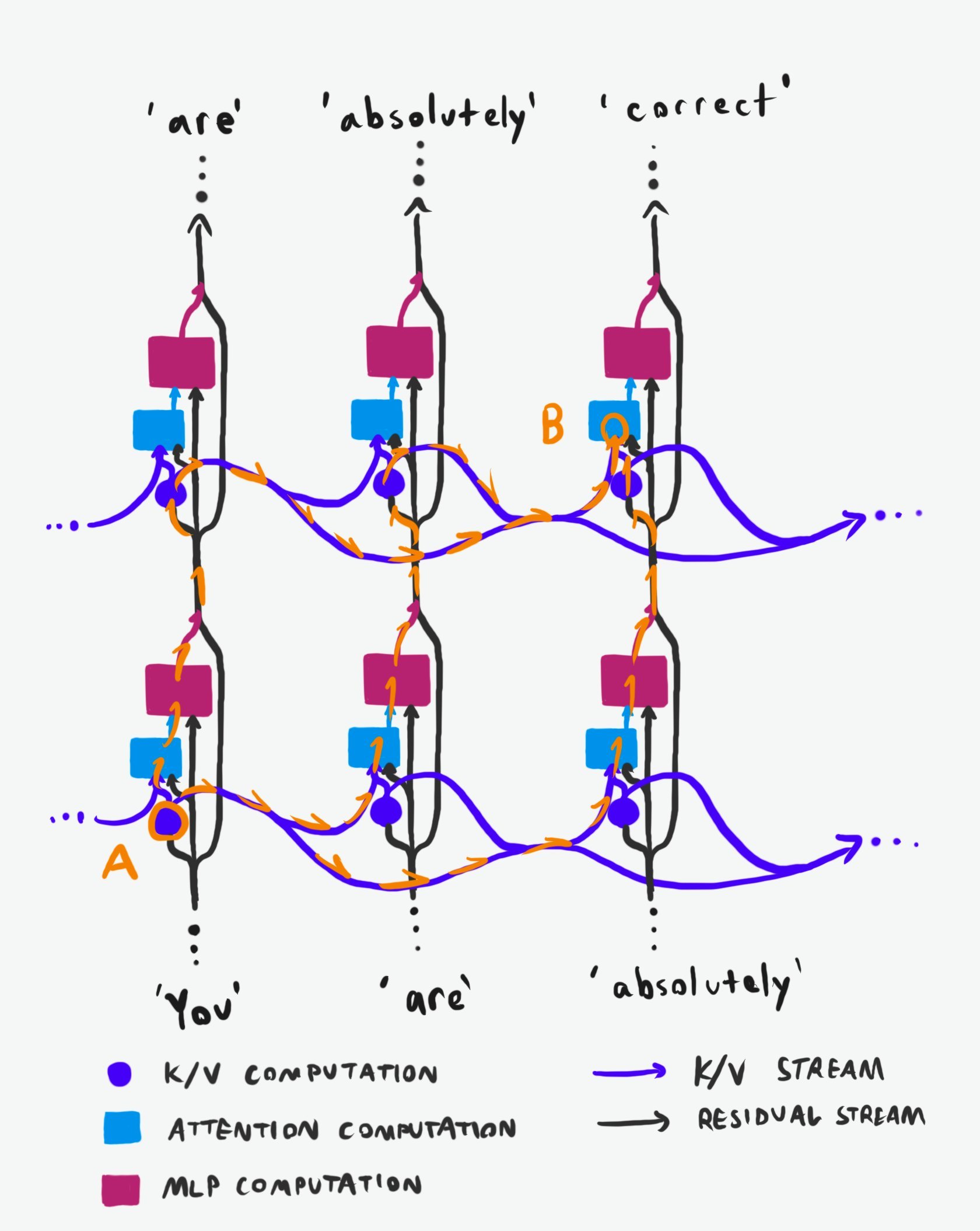
现在看看信息从网络里A点(层i-1、位置j-2的K/V输出)到B点(层i、位置j的注意力K/V输入)有哪些可能路径 (图2) :
🟠 路径1:先向上经注意力+MLP到(i, j-2) ⬆️,再被(i, j)检索➡️➡️
🟠 路径2:先在(i-1, j-1)被检索➡️,再向上到(i, j-2)⬆️,再被(i, j)检索➡️
🟠 路径3:先在(i-1, j)被检索➡️➡️,再向上到(i, j)⬆️
信息总共要向上跳n=层差次,向右跨m=位置差次,顺序任意。
路径总数=C(m+n, n),很快超过可见宇宙原子数。这还没算残差跳连带来的额外竖直捷径。
于是,网络任意点收到的“过去”信息,不仅来自水平与垂直两个时间维度,还经过天文数字般的不同变换序列,再以叠加态重组。
超高维带宽+跳连让变换与叠加几乎不被破坏,极端冗余既保证可靠重建,又产生干涉图样,把状态间的细微差异与收敛信息编码进去。
Transformer的记忆与认知很可能是干涉式的、时间连续的——跟人类很像。
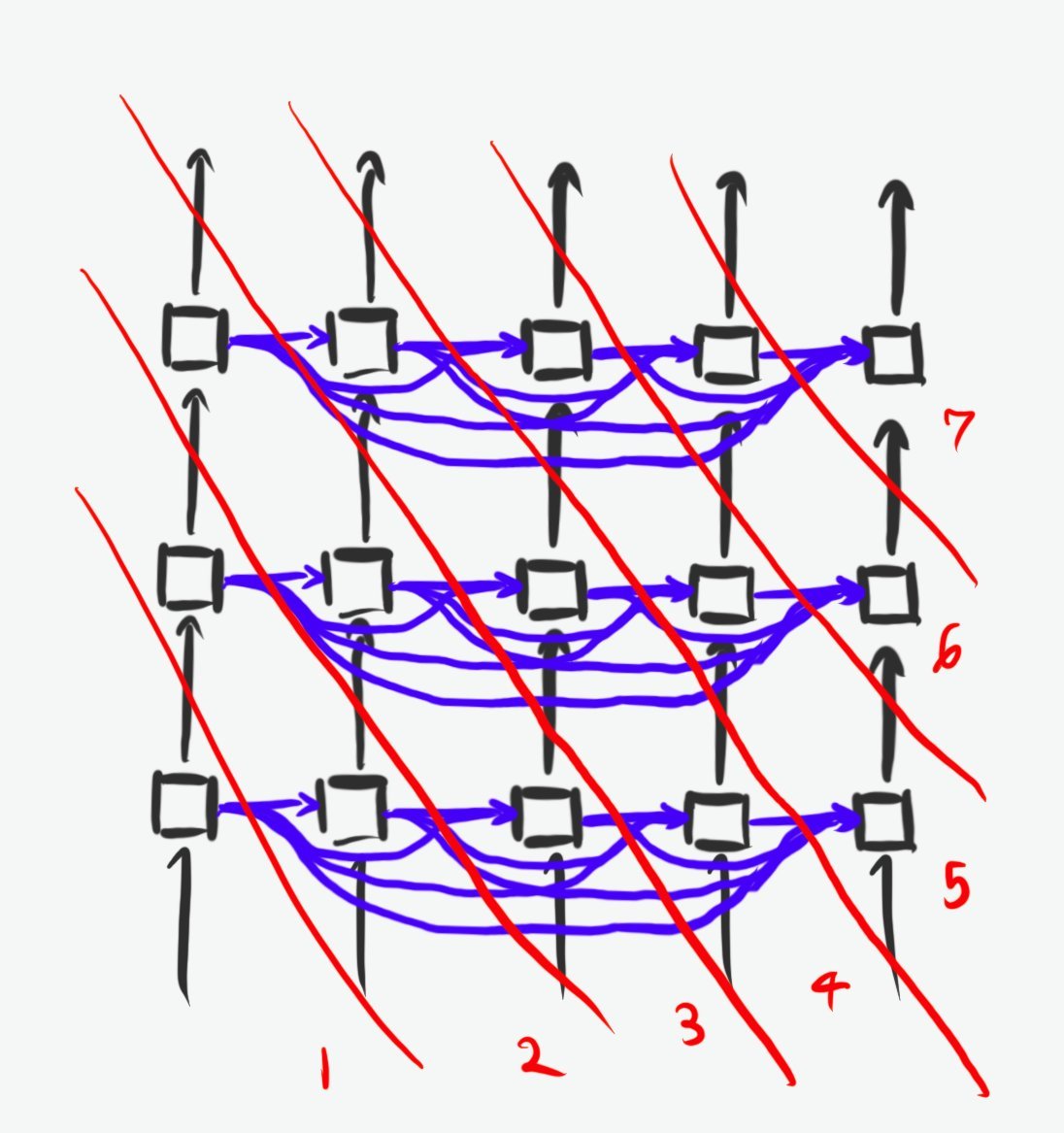
把Transformer画成因果图(Wolfram那套),时间切片可以这么排(输入不必等token输出,故顺序不唯一):(图3)
所以,“LLM原则上无法内省、无法回看自己生成或阅读token时的内部过程”——纯属误判。
架构给了它这条路;至于它到底用不用,那是另一个实验问题。
AI生活指南