[LG]《Learning When to Plan: Efficiently Allocating Test-Time Compute for LLM Agents》D Paglieri, B Cupiał, J Cook, U Piterbarg... [University College London & University of Oxford] (2025)
训练大型语言模型(LLM)进行动态规划,实现测试时计算资源的智能分配,显著提升了长时序任务中的决策效率和性能。
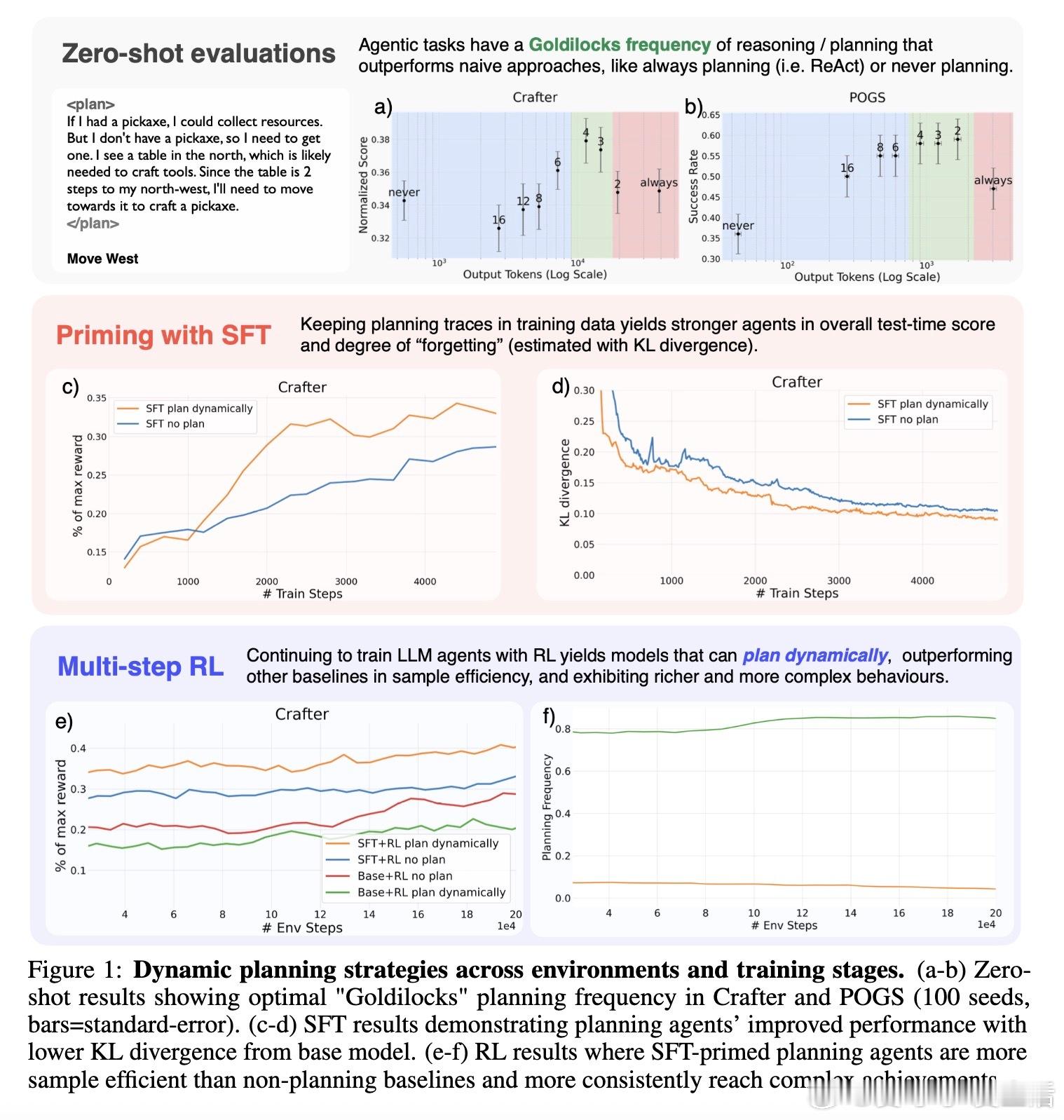
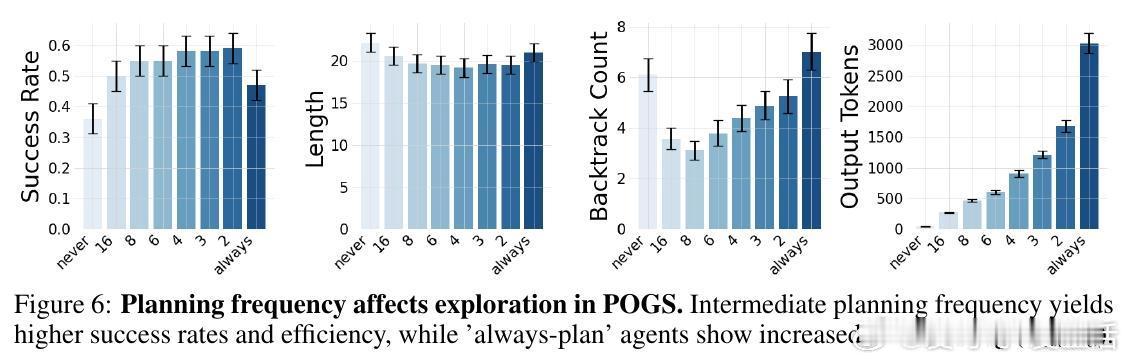
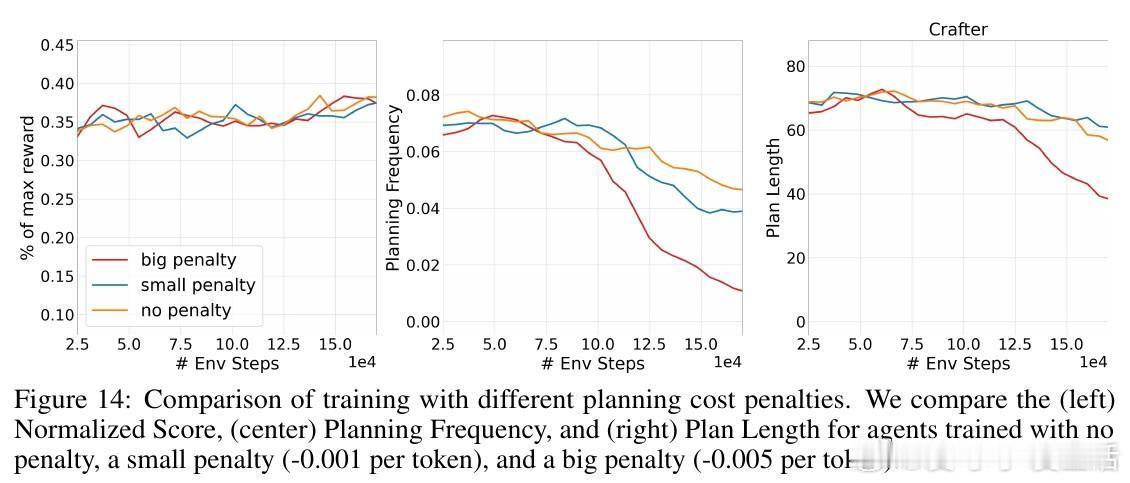
• 发现“Goldilocks”规划频率:过度频繁规划带来行为不稳定与资源浪费,过少规划则限制性能,中间频率最优。
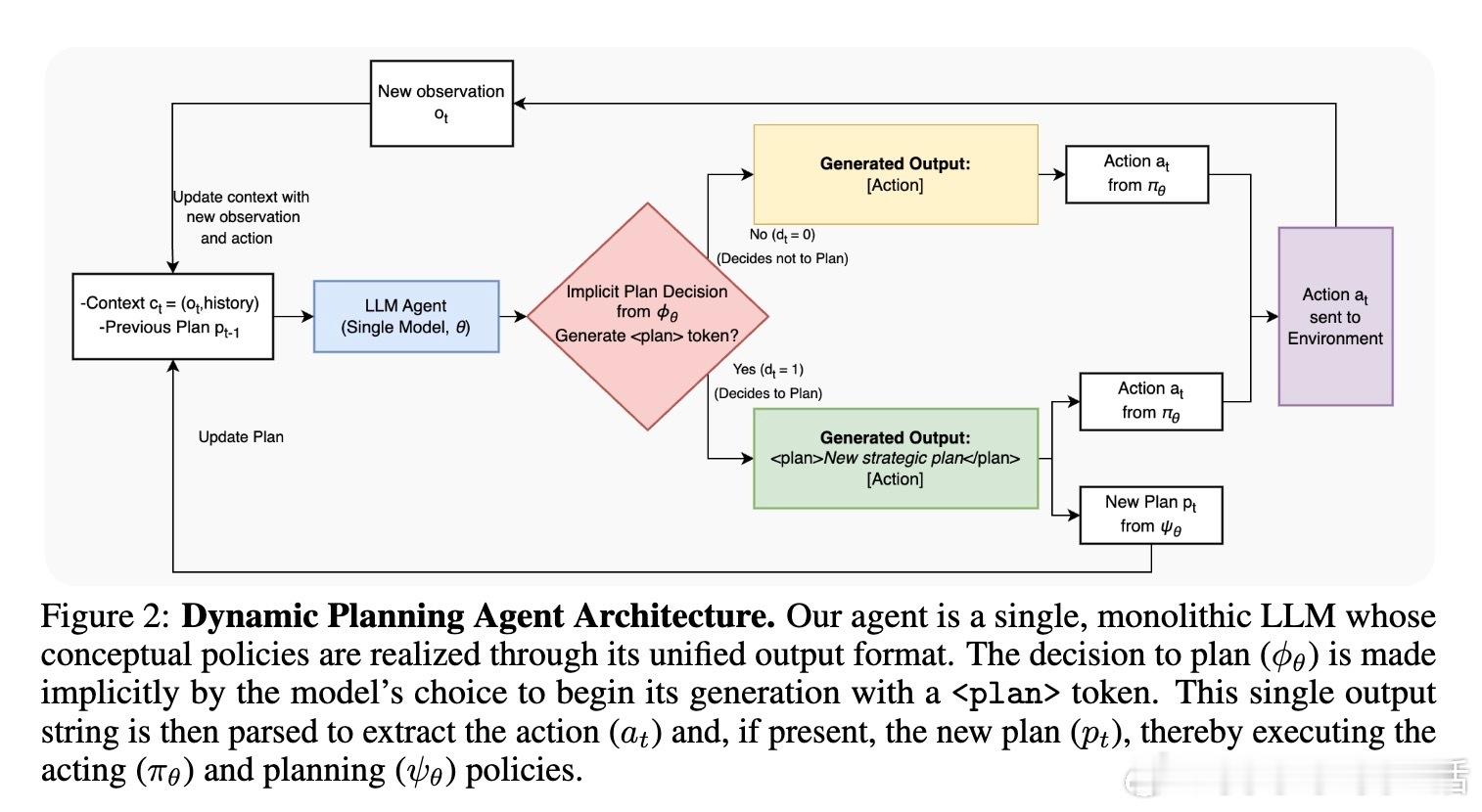
• 提出统一框架,将规划决策视为基于成本-收益权衡的动态决策,规划成本包括计算量、延迟及因频繁重规划引起的行为噪声。
• 两阶段训练策略:先通过多样化合成数据的监督微调(SFT)让模型掌握规划结构,再用强化学习(RL)优化动态规划决策,提升样本效率和复杂任务完成率。
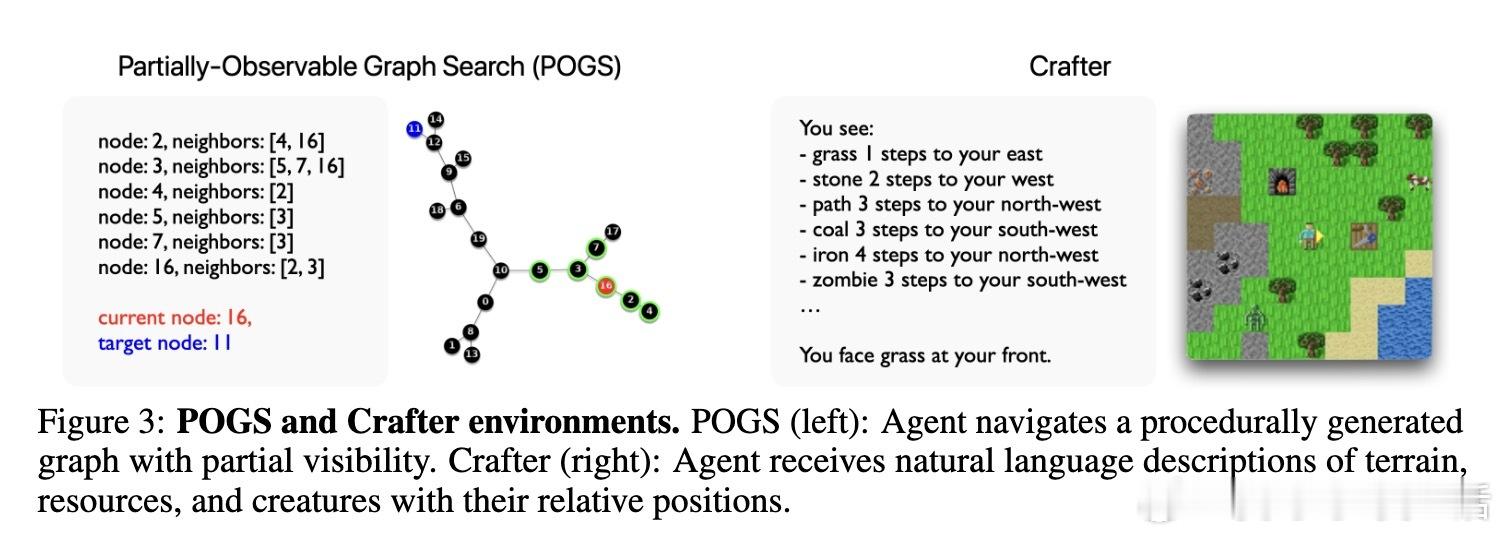
• 实验环境涵盖部分可观测图搜索(POGS)和Minecraft风格的Crafter,验证动态规划策略的普适性和实用性。
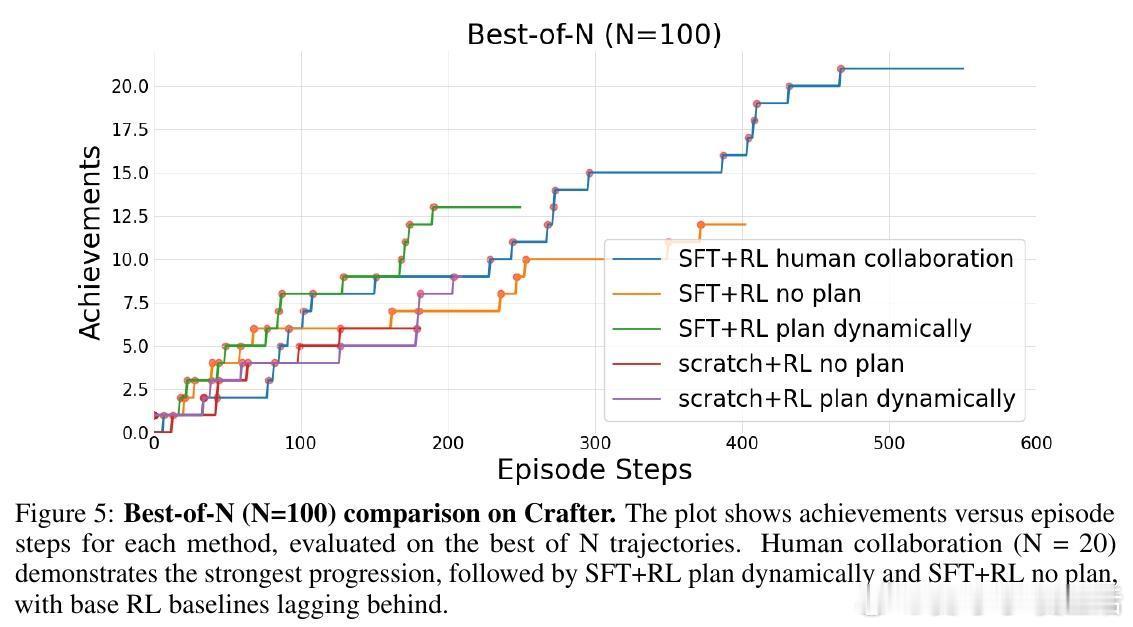
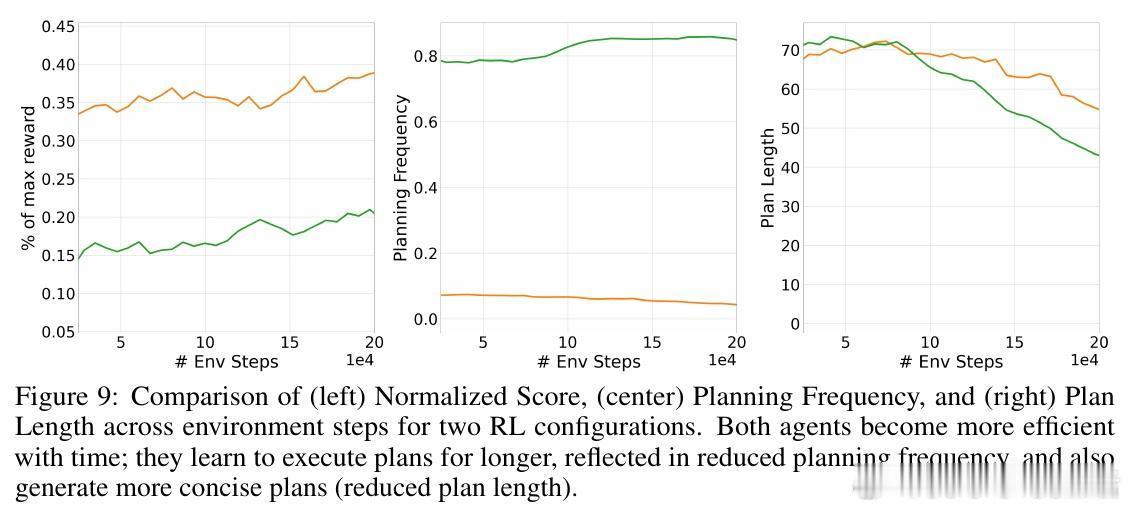
• 训练出的代理不仅自主制定和执行计划,还能根据环境变化灵活重规划,且能被人类书面计划高效引导,展现更强的协同能力。
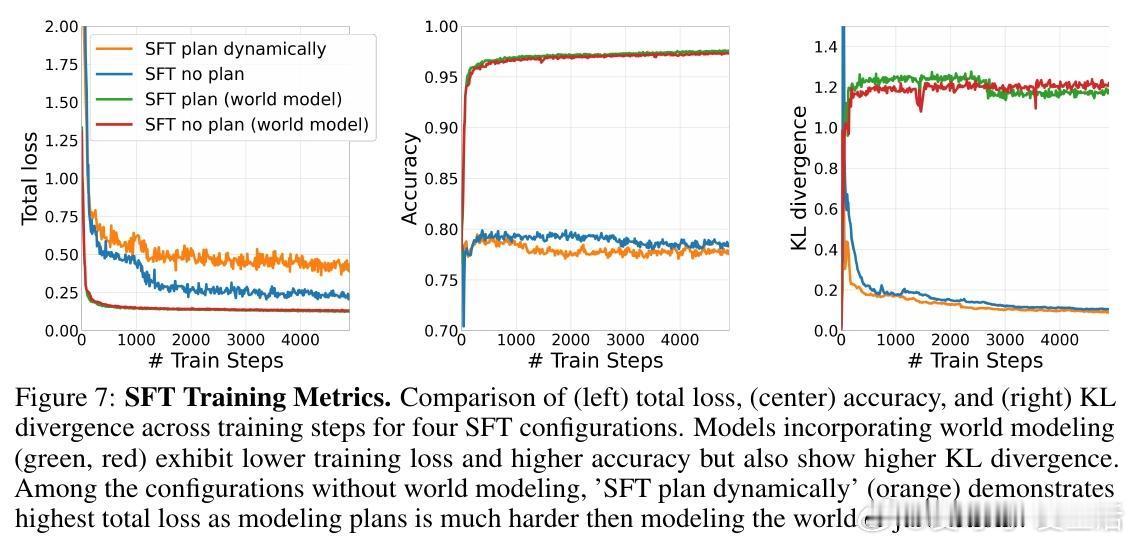
• SFT阶段显著降低模型与原始预训练模型的KL散度,减少微调过程中的行为偏离,促进更稳定的学习。
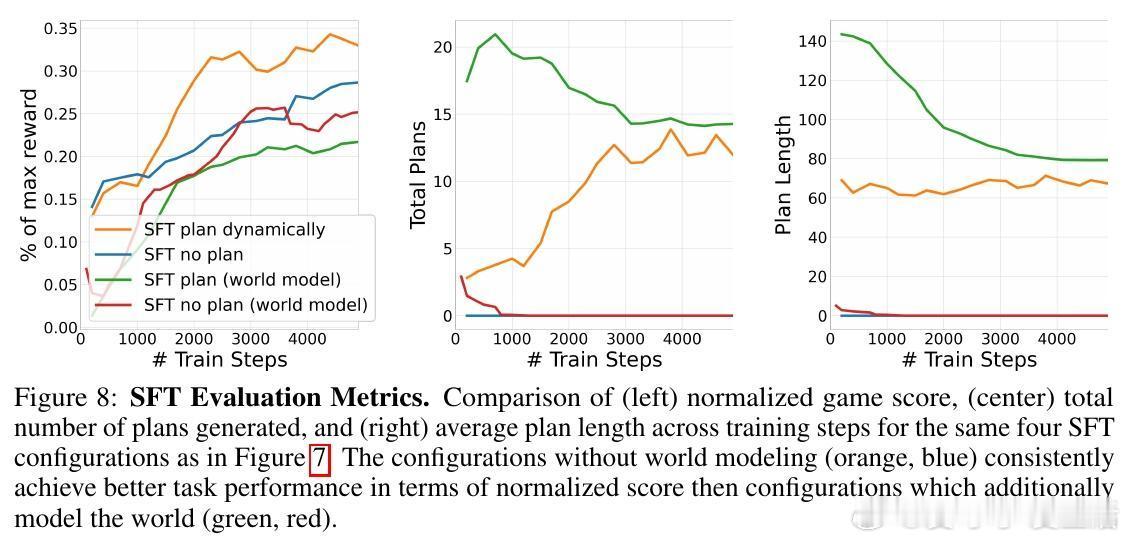
• 研究揭示规划能力的演进路径——从零次规划的无效策略,到固定频率规划的非最优,再到动态规划的智能计算分配。
• 规划策略学习不仅提升了任务表现,还减少了例如路径回溯等低效探索行为,实现更稳定合理的决策流程。
心得:
1. 理性分配计算资源比一味加码更有效,适度规划避免了“过度思考”带来的性能下降。
2. 通过引入显式自然语言计划,模型能更好地理解行为背后的因果逻辑,提升模仿学习效果。
3. 人机协同中,RL训练后的规划模型能精准执行人类指令,开启更安全与可控的智能体交互方式。
详情🔗 arxiv.org/abs/2509.03581
大语言模型强化学习动态规划智能体计算资源管理人机协同