[LG]《RL's Razor: Why Online Reinforcement Learning Forgets Less》I Shenfeld, J Pari, P Agrawal [MIT] (2025)
在线强化学习(RL)为何较少遗忘?一项来自MIT的最新研究揭示了核心机制与实证规律:
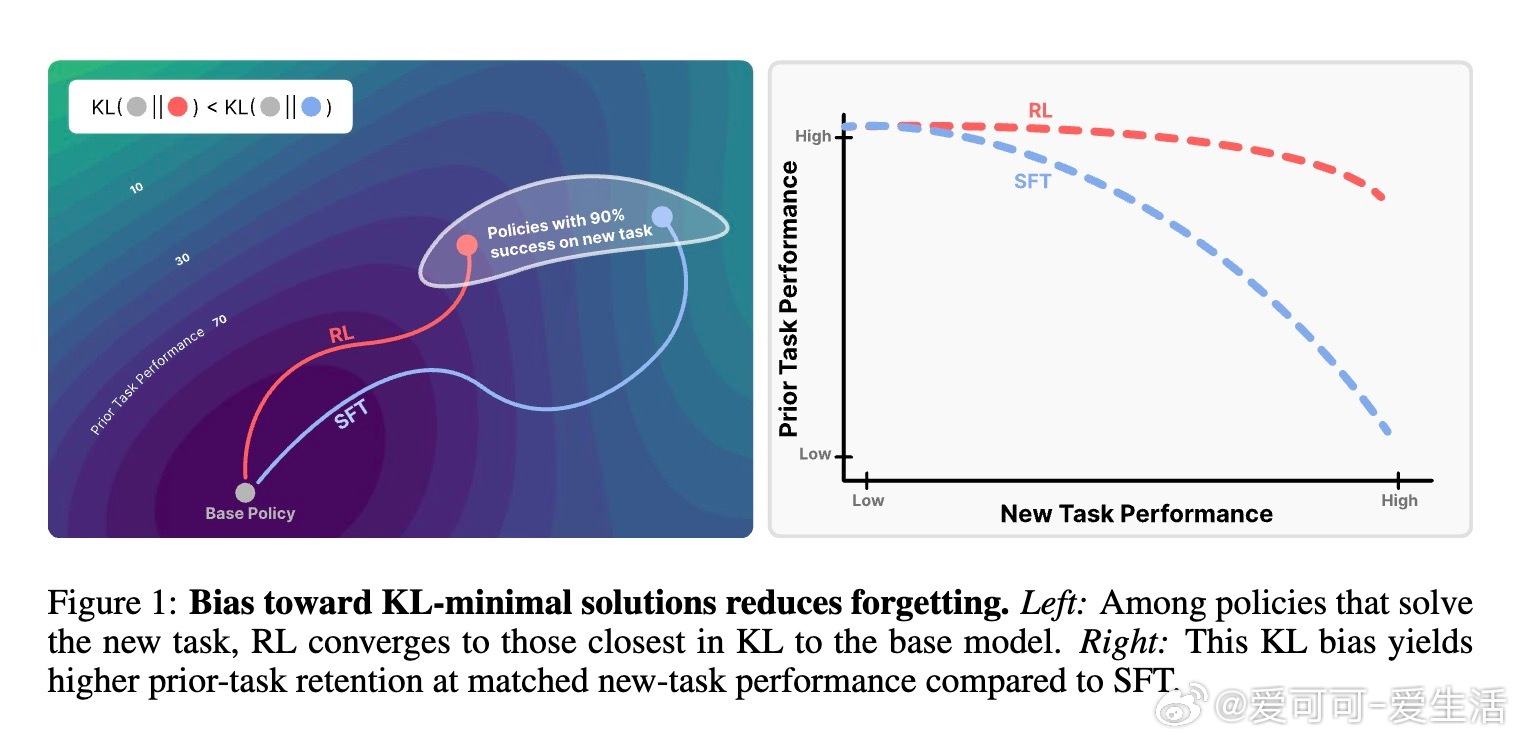
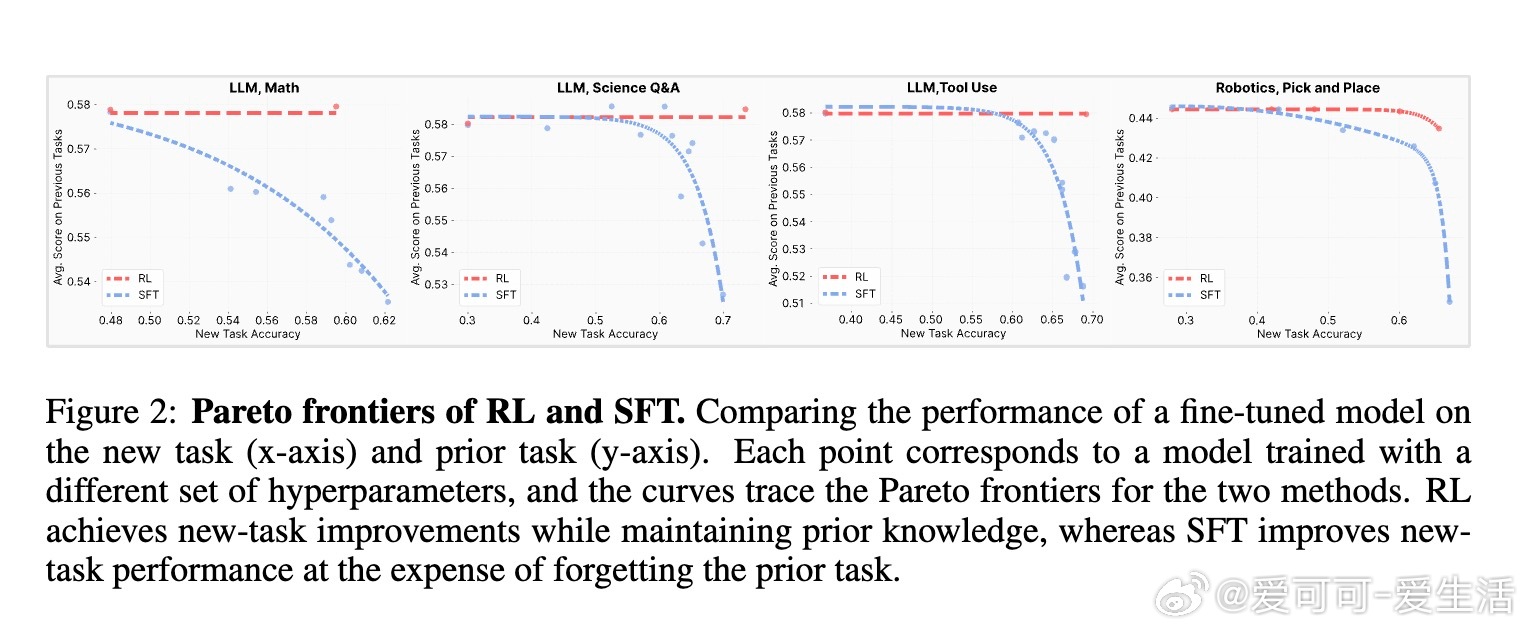
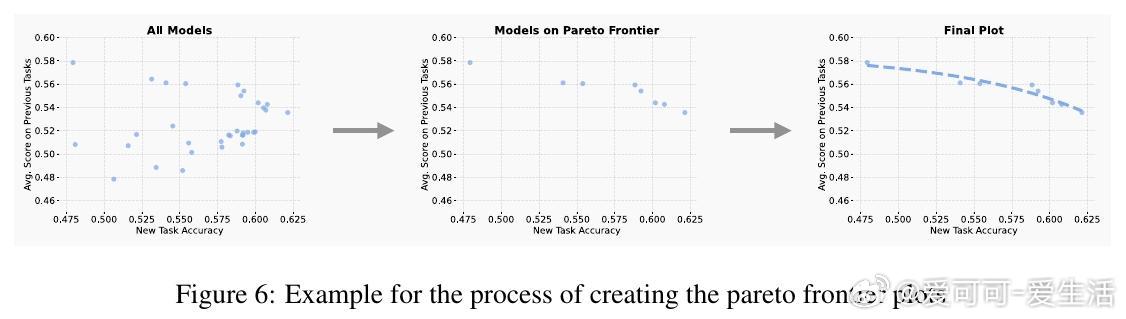
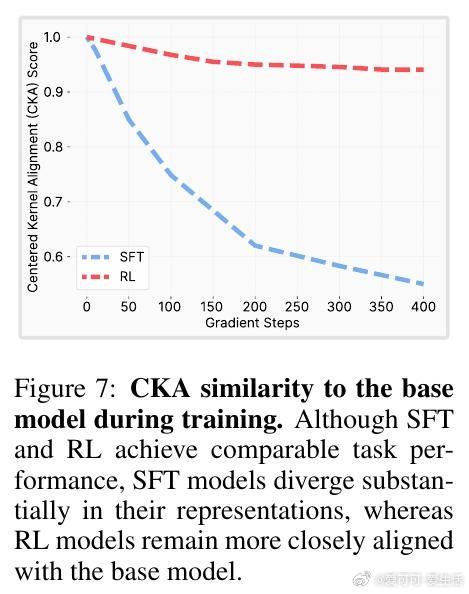
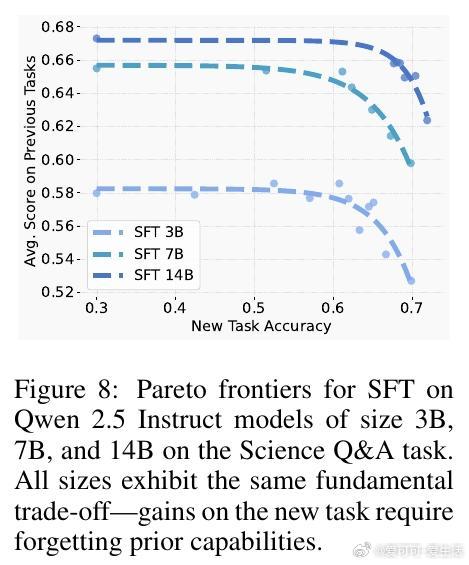
• RL与监督微调(SFT)在新任务性能相当时,RL显著保留了更多先前学到的知识和能力,降低灾难性遗忘风险。
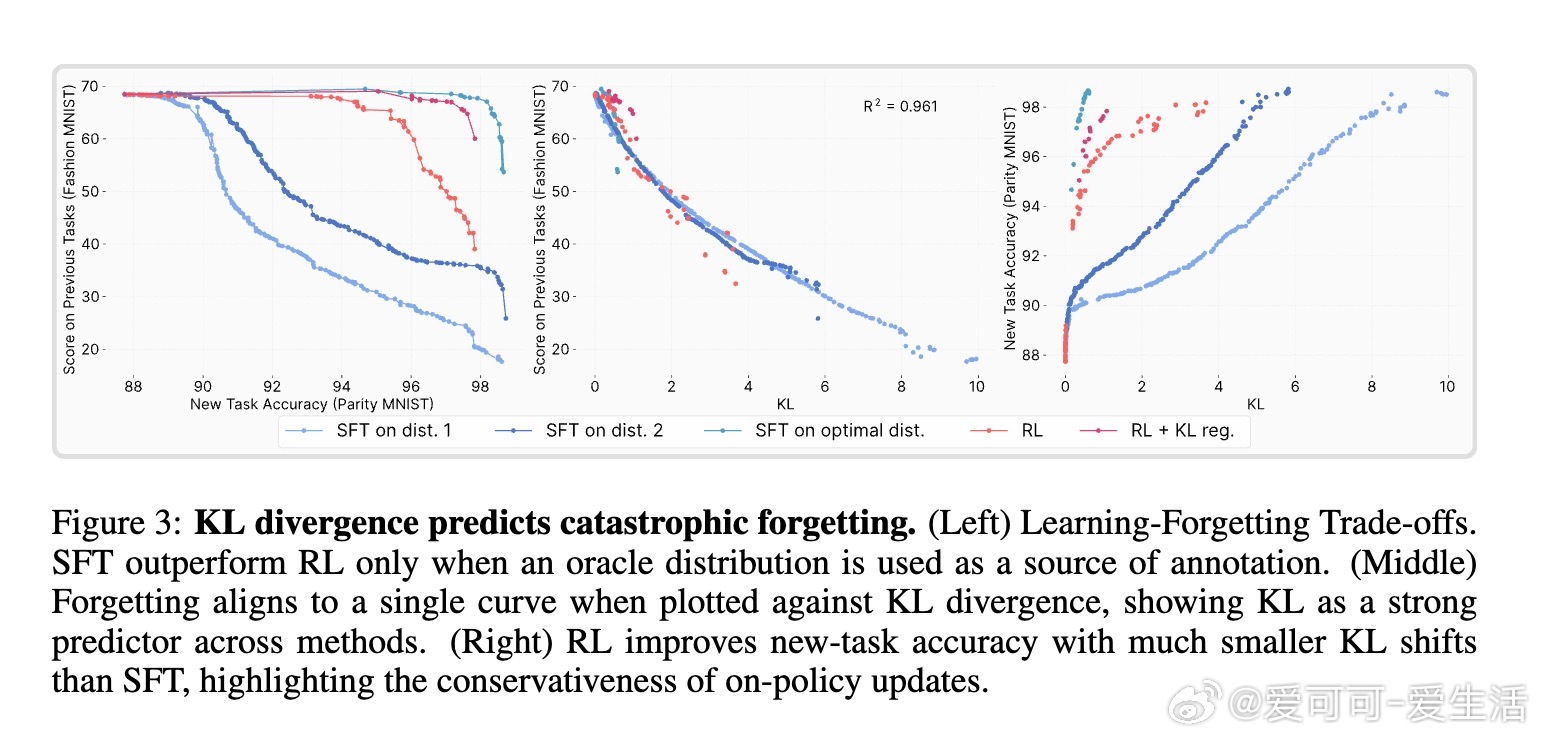
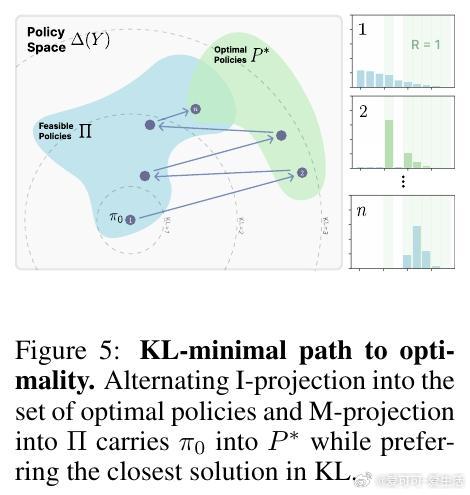
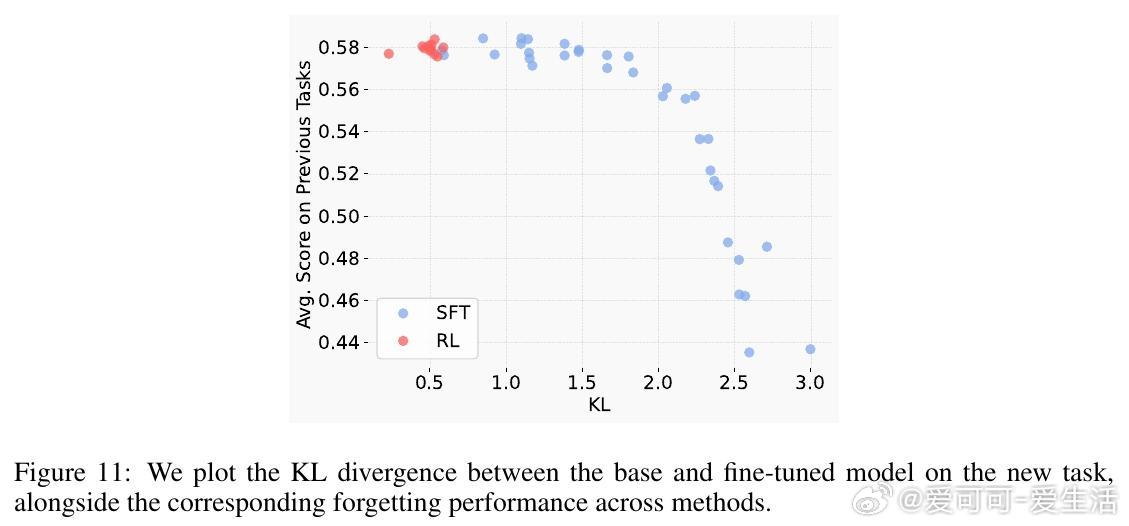
• 遗忘程度由新任务上的KL散度(即微调后策略与原始策略的分布差异)强烈预测。KL散度越小,遗忘越少。
• RL的“on-policy”训练本质上偏向KL最小解:它通过采样当前模型分布的输出并重新加权,逐步调整策略,限制了向远离原模型的分布转变。
• SFT则可能收敛到与基模型分布差异很大的解,导致显著遗忘。
• 实验涵盖大规模语言模型与机器人任务,均验证RL在维持旧知识方面表现更佳。
• 理论证明政策梯度方法收敛至KL距离基模型最近的最优策略,形成“RL剃刀”原则。
• 构造的Oracle SFT分布(最小KL且完全准确)甚至优于RL,表明本质是训练分布选择而非算法本身。
• 传统的参数更新大小、激活变化等度量与遗忘相关性弱,KL散度是唯一稳定且高精度的预测指标。
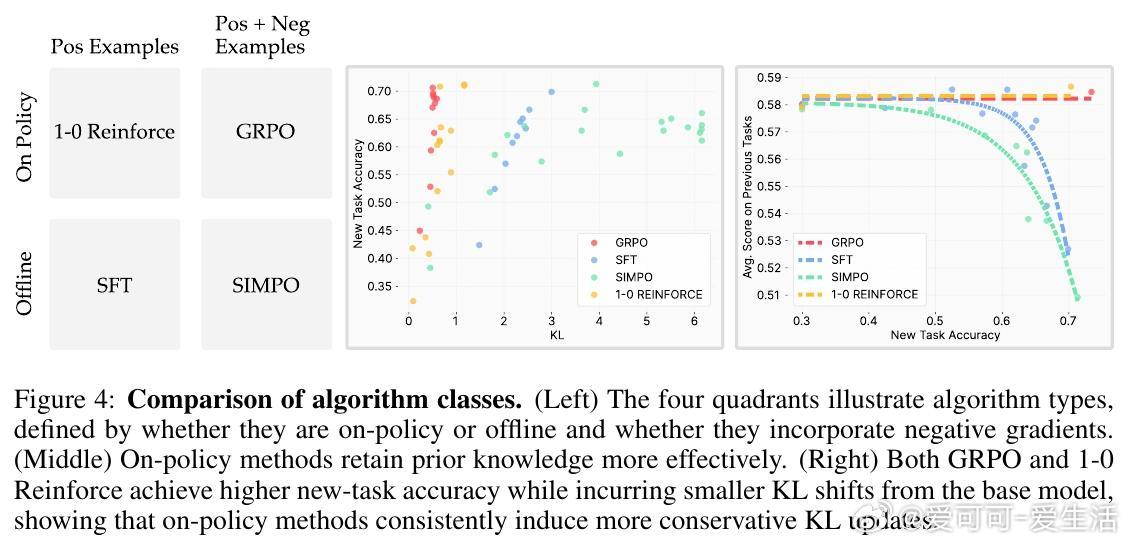
• RL训练中利用自身输出分布采样和负样本机制,促成保守而有效的策略更新,减少对旧知识的破坏。
心得:
1. 保持与原模型分布接近是防止灾难性遗忘的关键,训练算法应重视分布约束而非仅仅优化新任务准确率。
2. RL的on-policy特性自然实现了这一分布约束,提示未来微调设计可借鉴或融合RL思路以兼顾学习与记忆。
3. 评估微调方法时,关注KL散度及其带来的知识保持能力,比单纯关注新任务表现更具指导意义。
论文🔗 arxiv.org/abs/2509.04259
完整研究报告:
强化学习灾难性遗忘机器学习大模型微调KL散度