[LG]《Towards a Unified View of Large Language Model Post-Training》X Lv, Y Zuo, Y Sun, H Liu... [Tsinghua University] (2025)
统一视角下的大语言模型后训练:融合监督微调与强化学习的新范式
• 提出统一策略梯度估计器(UPGE),将监督微调(SFT)和强化学习(RL)视为优化同一目标的不同形式,揭示两者并非矛盾而是互补的训练信号。
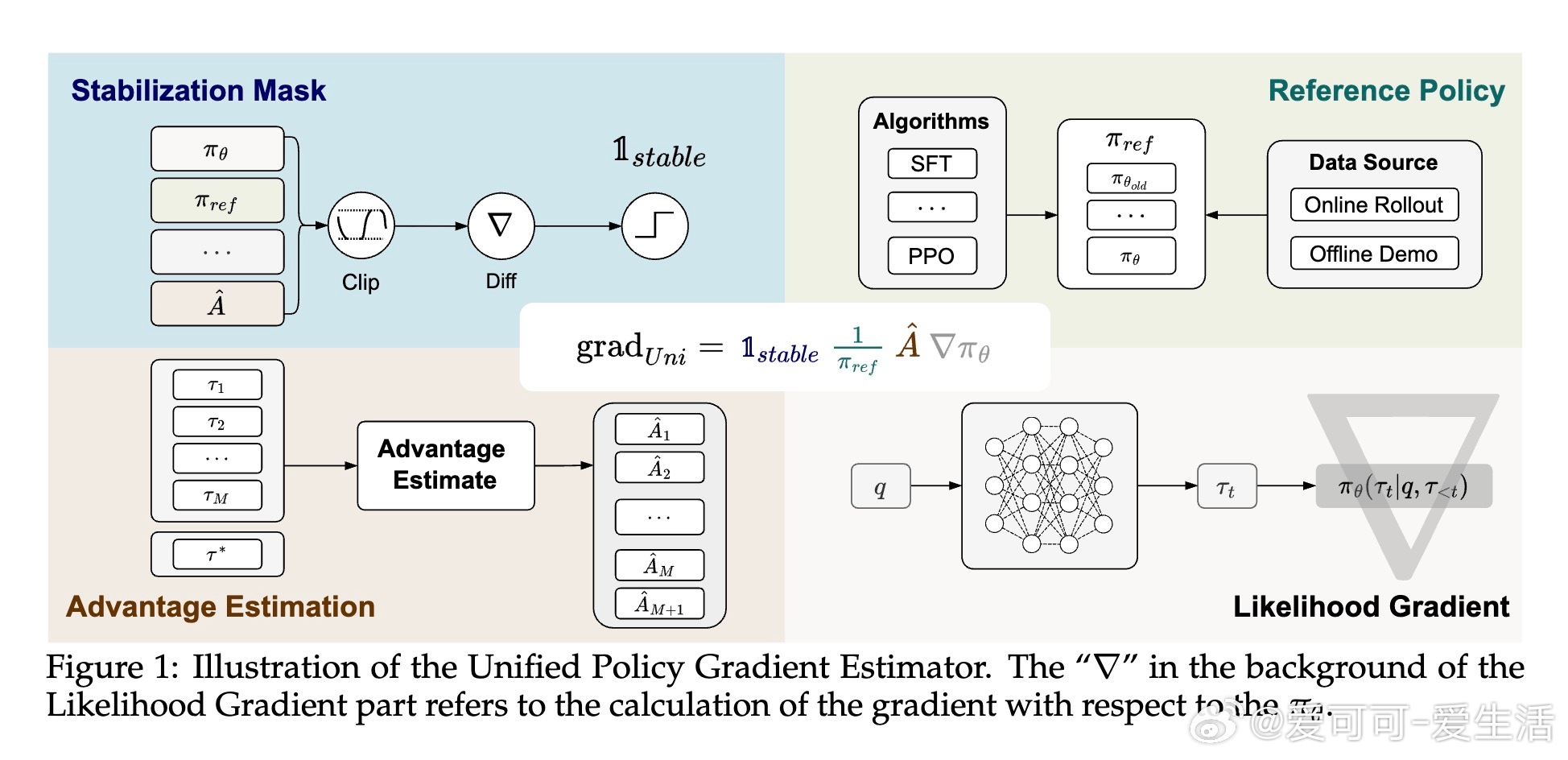
• 该估计器由四个核心组件构成:稳定性掩码(防止训练不稳定)、参考策略分母(控制重要采样权重)、优势估计(衡量动作相对价值)、似然梯度(参数更新核心)。
• 基于理论框架,设计混合后训练算法(HPT),动态根据模型表现反馈调整SFT和RL损失权重,实现能力驱动的自适应训练信号切换。
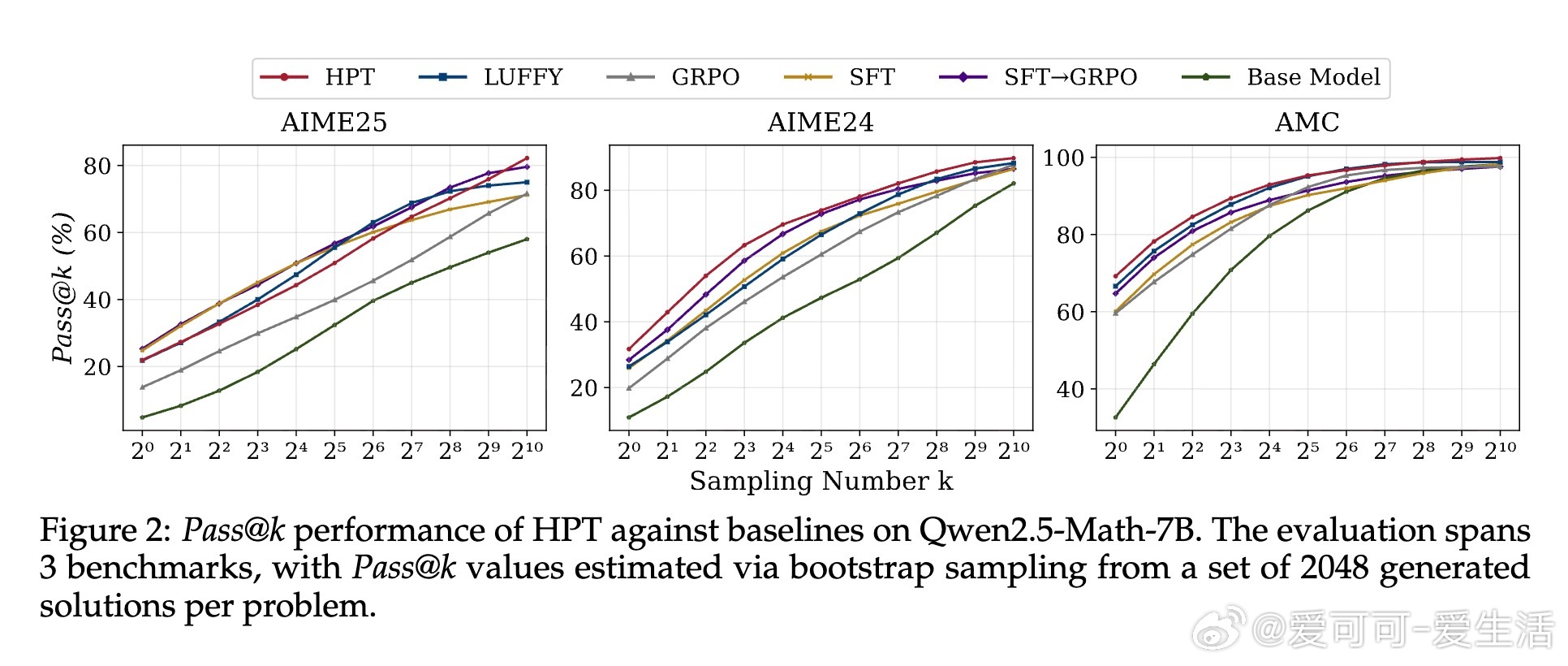
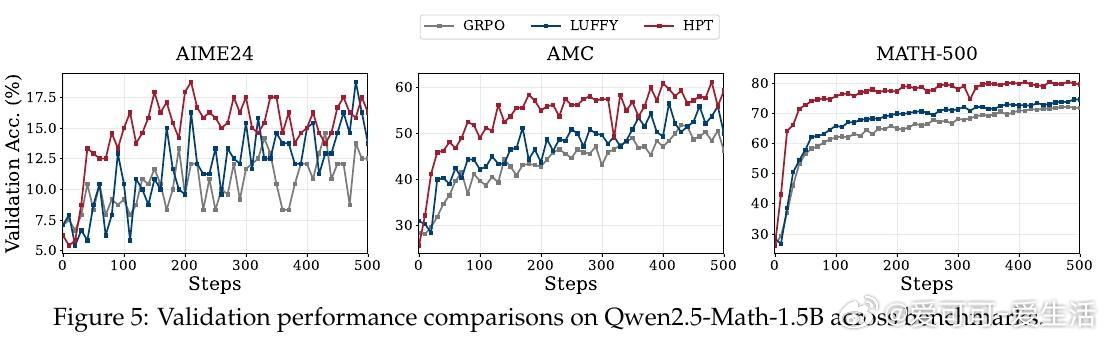
• HPT在多种模型(如Qwen2.5-Math系列、LLaMA3.1-8B)和六个数学推理基准上均取得领先性能,显著超越传统SFT、纯RL及多阶段SFT→RL流程,且展现更佳的探索能力与泛化表现。
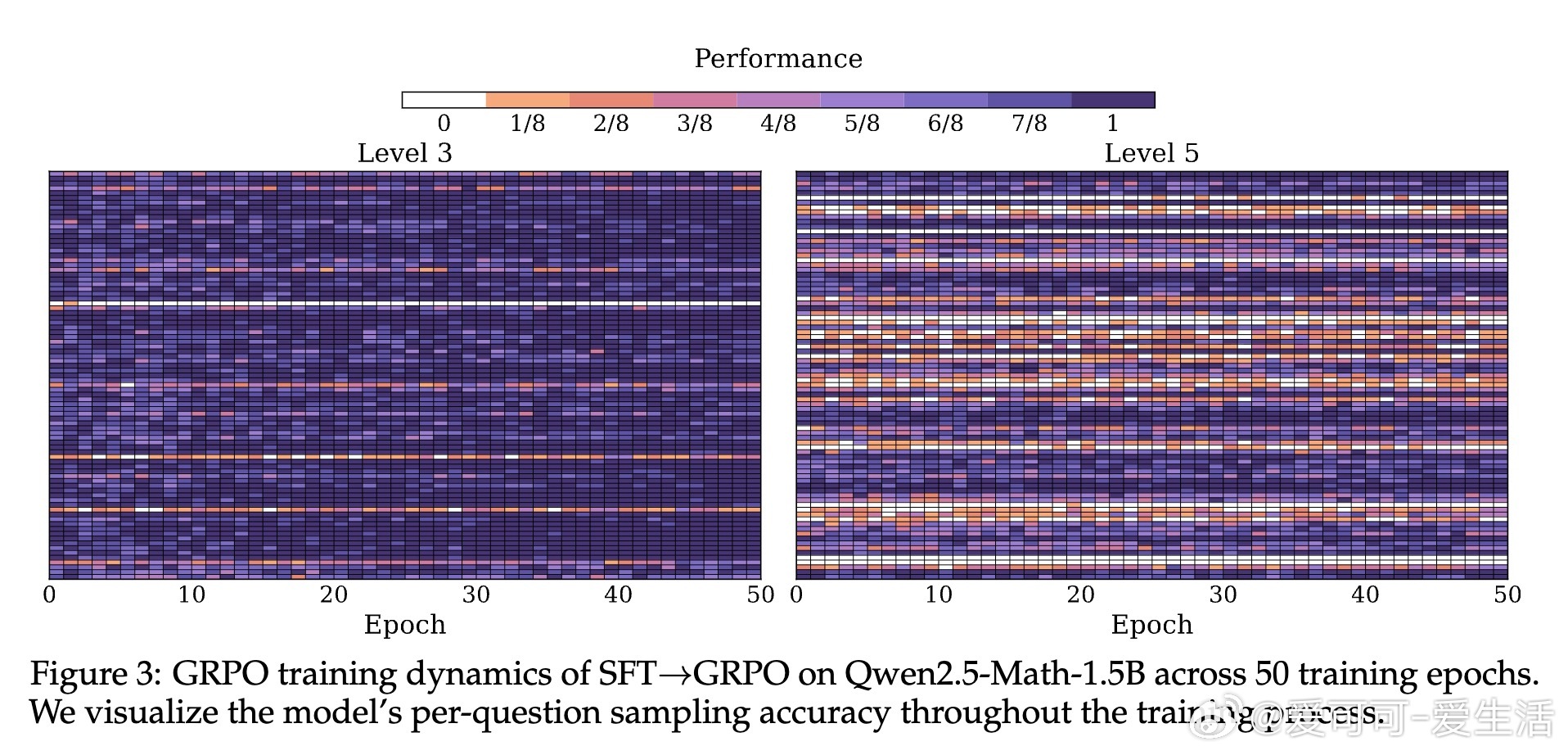
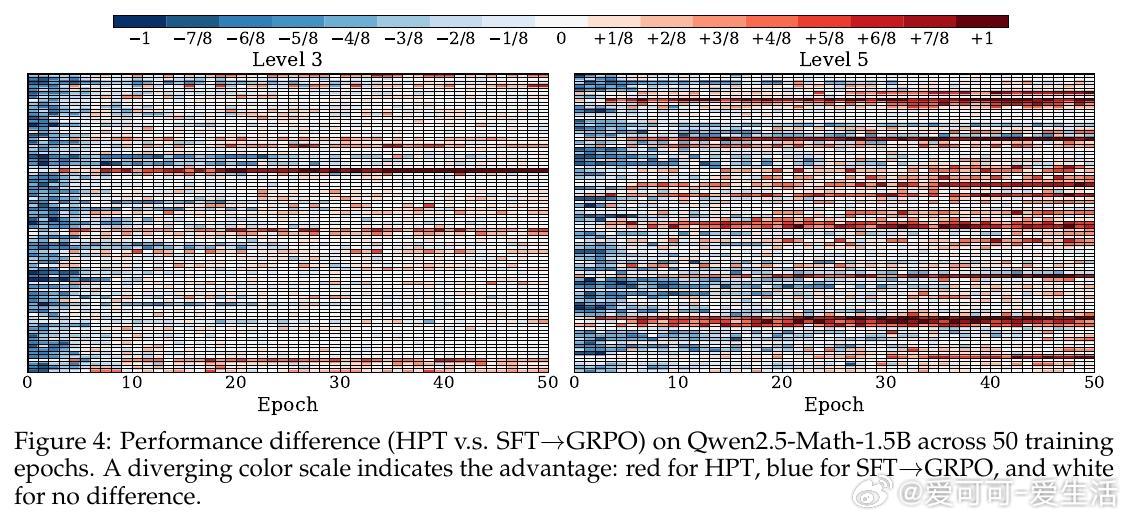
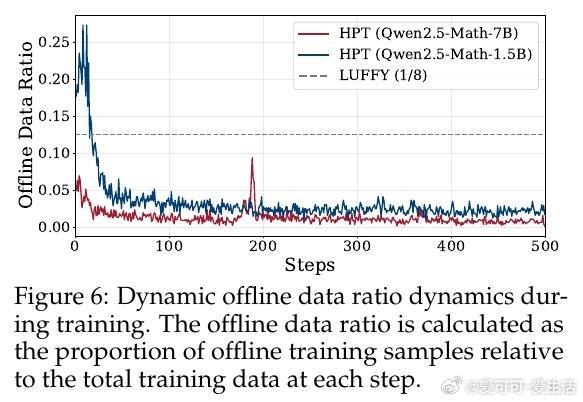
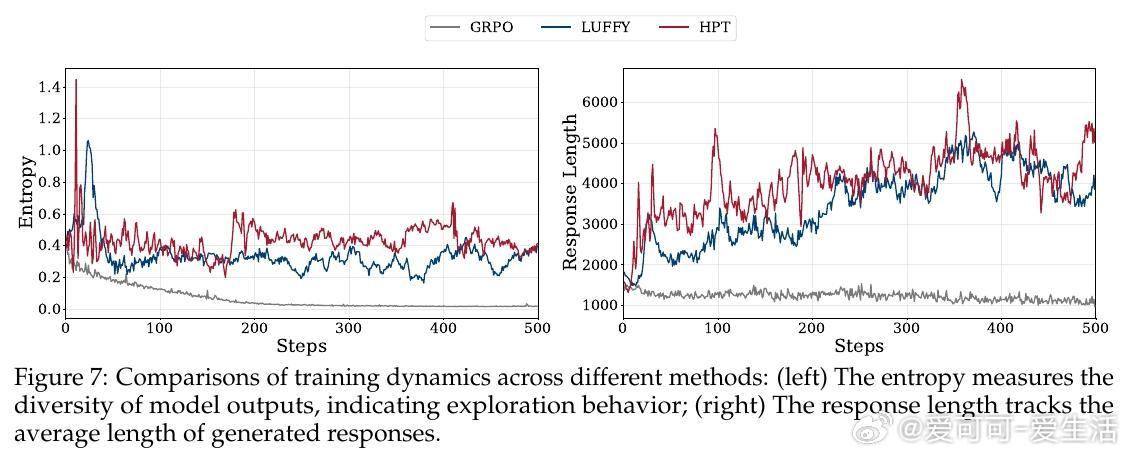
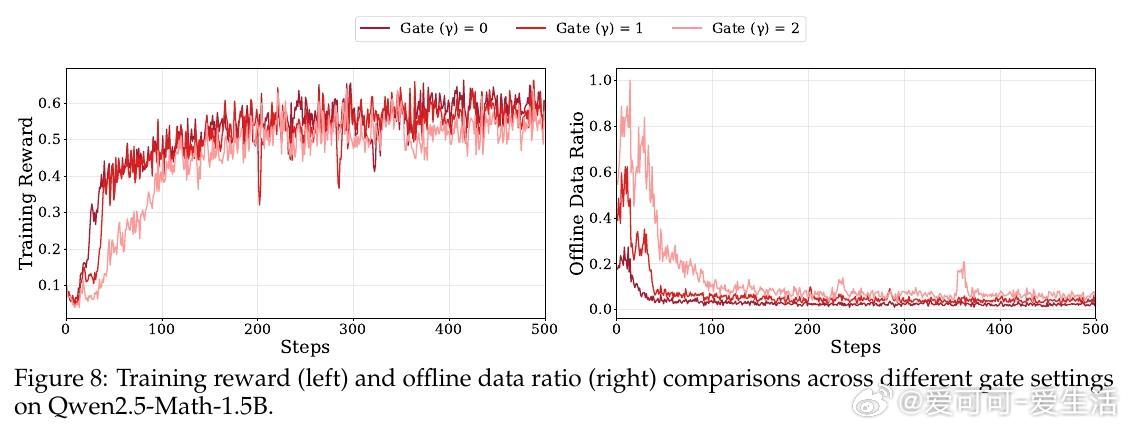
• 实验深入揭示:HPT有效缓解RL训练中的高方差和SFT的过拟合风险,保持模型长期吸收离线示范知识同时激励在线探索;动态门控机制确保探索与利用平衡,提升训练稳定性与效率。
心得:
1. SFT与RL的“对立”实为优化路径的偏差,不同训练信号本质上共同推动模型向更优策略收敛。
2. 通过动态调节训练信号权重,可让模型在能力不足时依赖示范指导,能力提升后转向强化探索,兼顾稳健性与创新性。
3. 统一梯度框架为设计更高效、鲁棒的后训练算法提供了理论依据,推动LLM训练方法从经验驱动向原理驱动转变。
详见🔗arxiv.org/abs/2509.04419
大语言模型强化学习监督微调机器学习理论模型训练