[LG]《Set Block Decoding is a Language Model Inference Accelerator》I Gat, H Ben-Hamu, M Havasi, D Haziza... [FAIR at Meta] (2025)
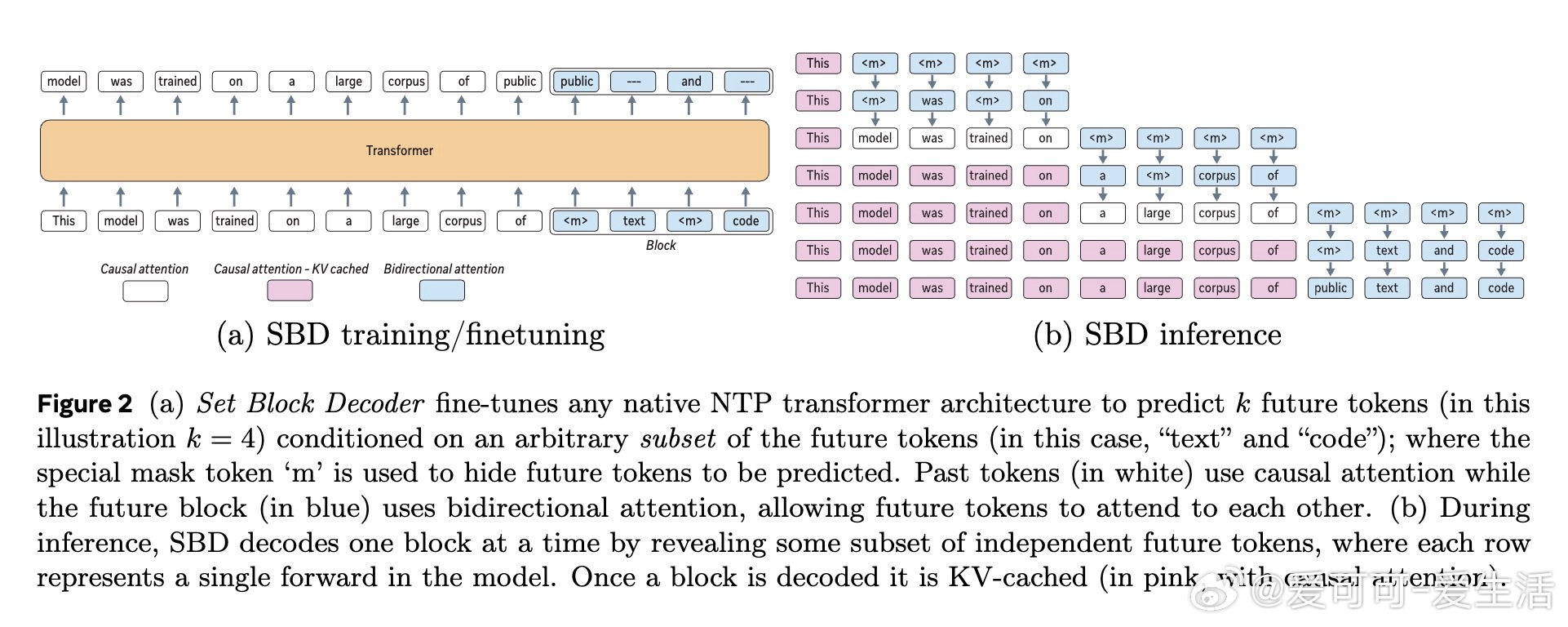
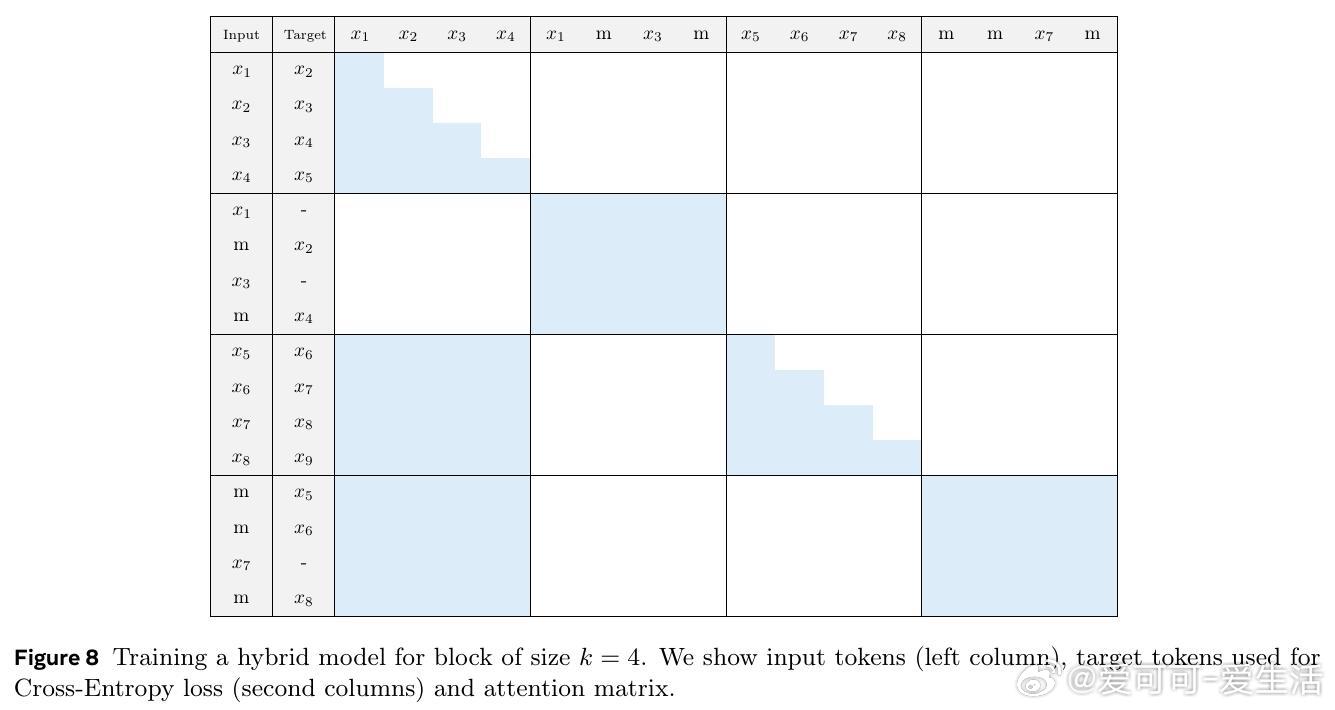
Set Block Decoding(SBD)提出了一种简洁高效的语言模型推理加速方案,将传统的下一Token预测(NTP)与掩码Token预测(MATP)融合于一体,实现了非连续未来多个令牌的并行采样,显著降低解码阶段的计算开销。
• 单一模型架构,无需结构改动或额外训练超参,支持精确KV缓存,便于快速微调现有NTP模型。
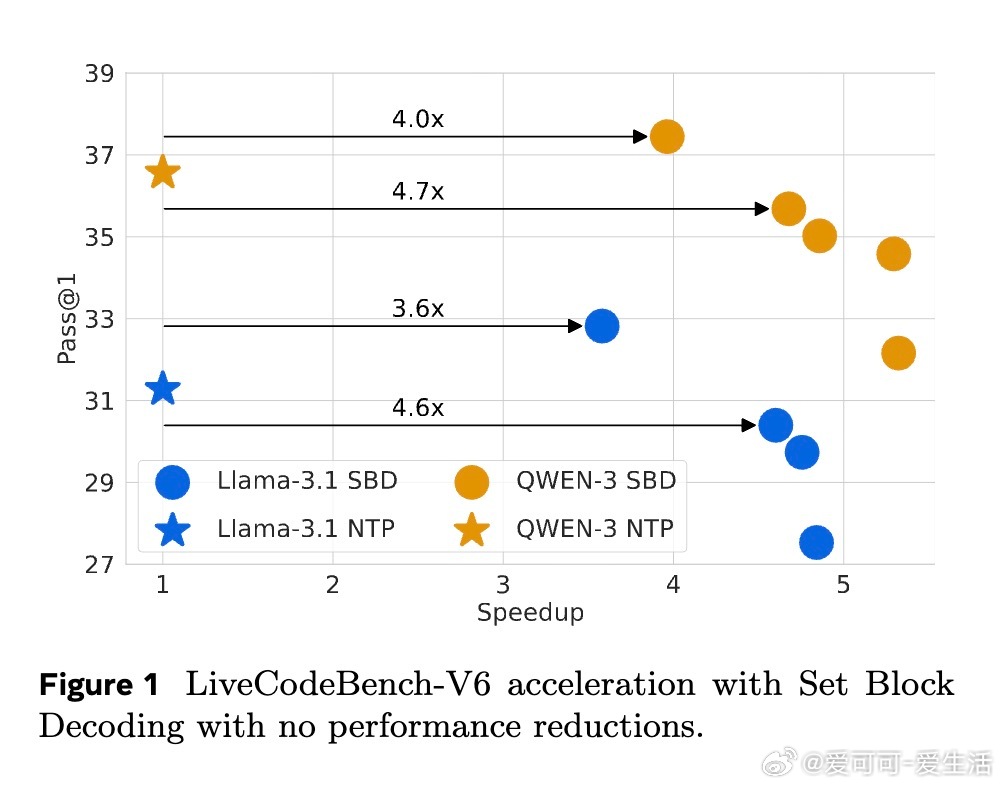
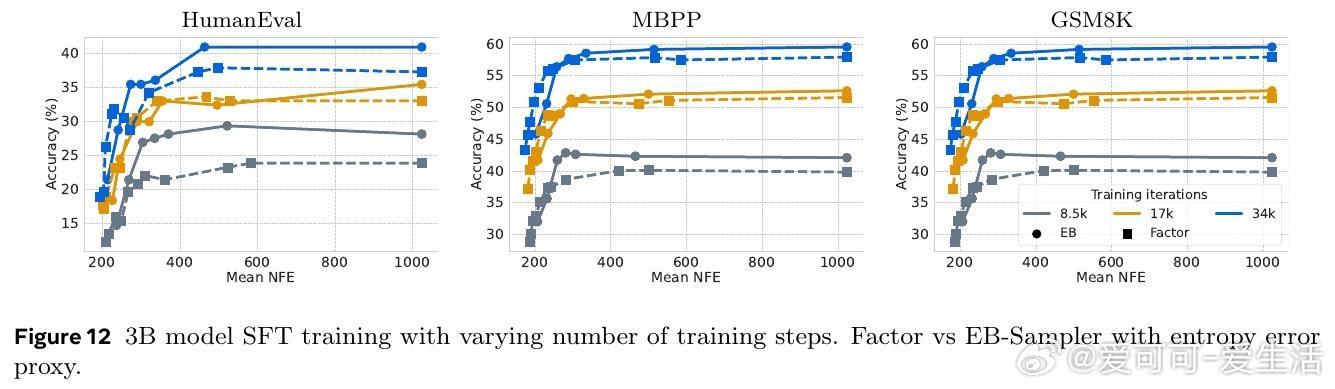
• 灵活利用离散扩散领域先进采样器(如Entropy Bounded采样器),以条件独立性为基础动态并行解码,提高采样速度3-5倍,且性能无损。
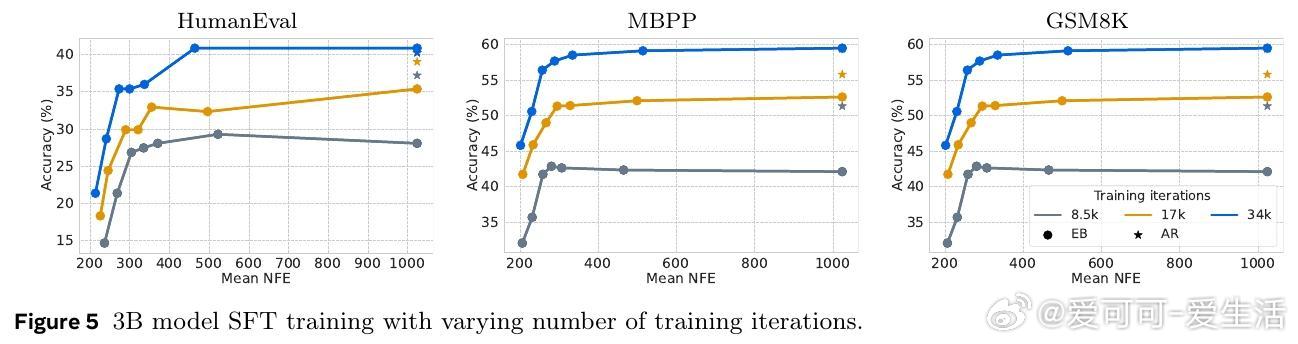
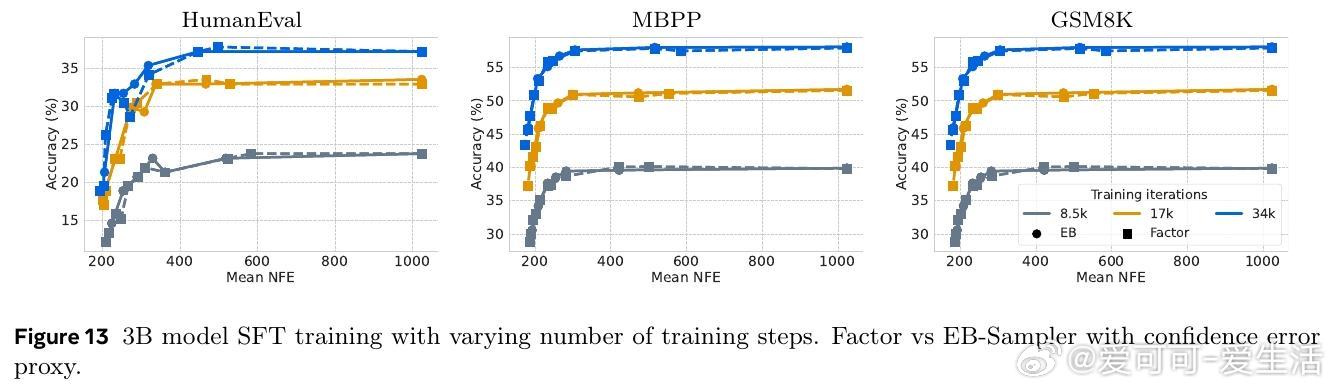
• 通过在Llama-3.1 8B和Qwen-3 8B上的微调验证,SBD在多种推理、编程和数学任务上保持与NTP相当的准确率,同时大幅减少模型前向次数。
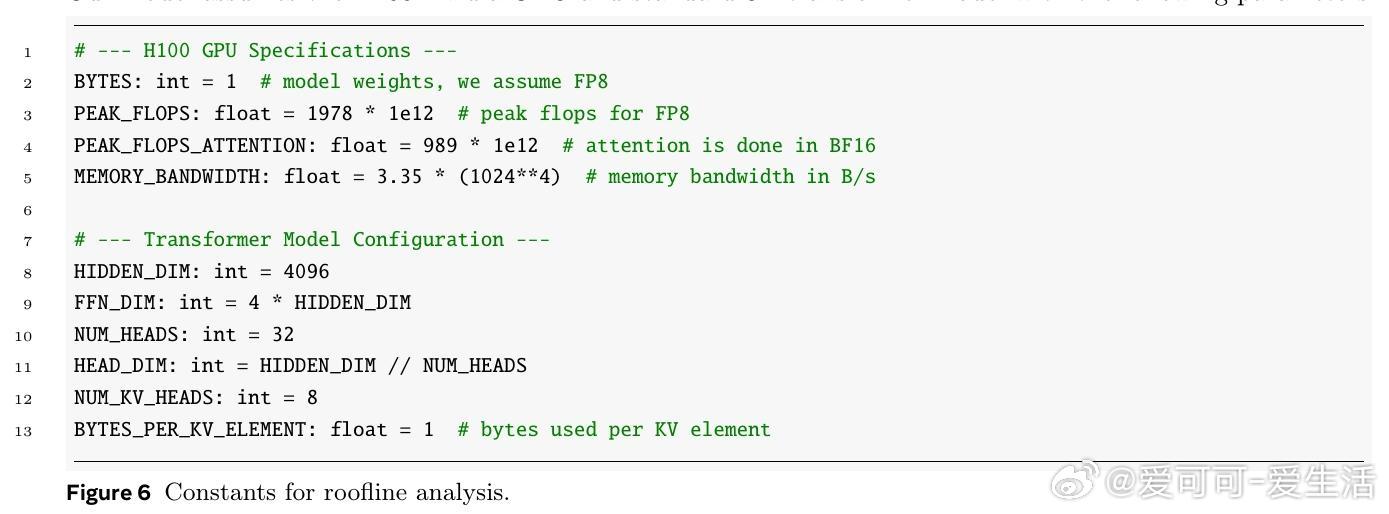
• 理论“屋顶线”模型分析表明,实测加速几乎可直接对应模型前向次数减少,尤其在块大小16和批量大小适中时最优。
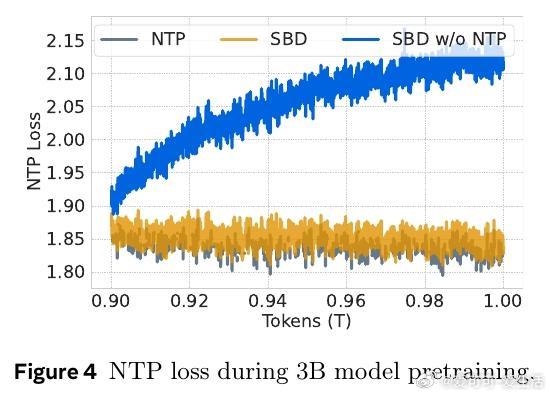
• 训练中融合NTP和掩码预测损失保证自动回归性能,消除单纯掩码训练导致的性能下降风险。
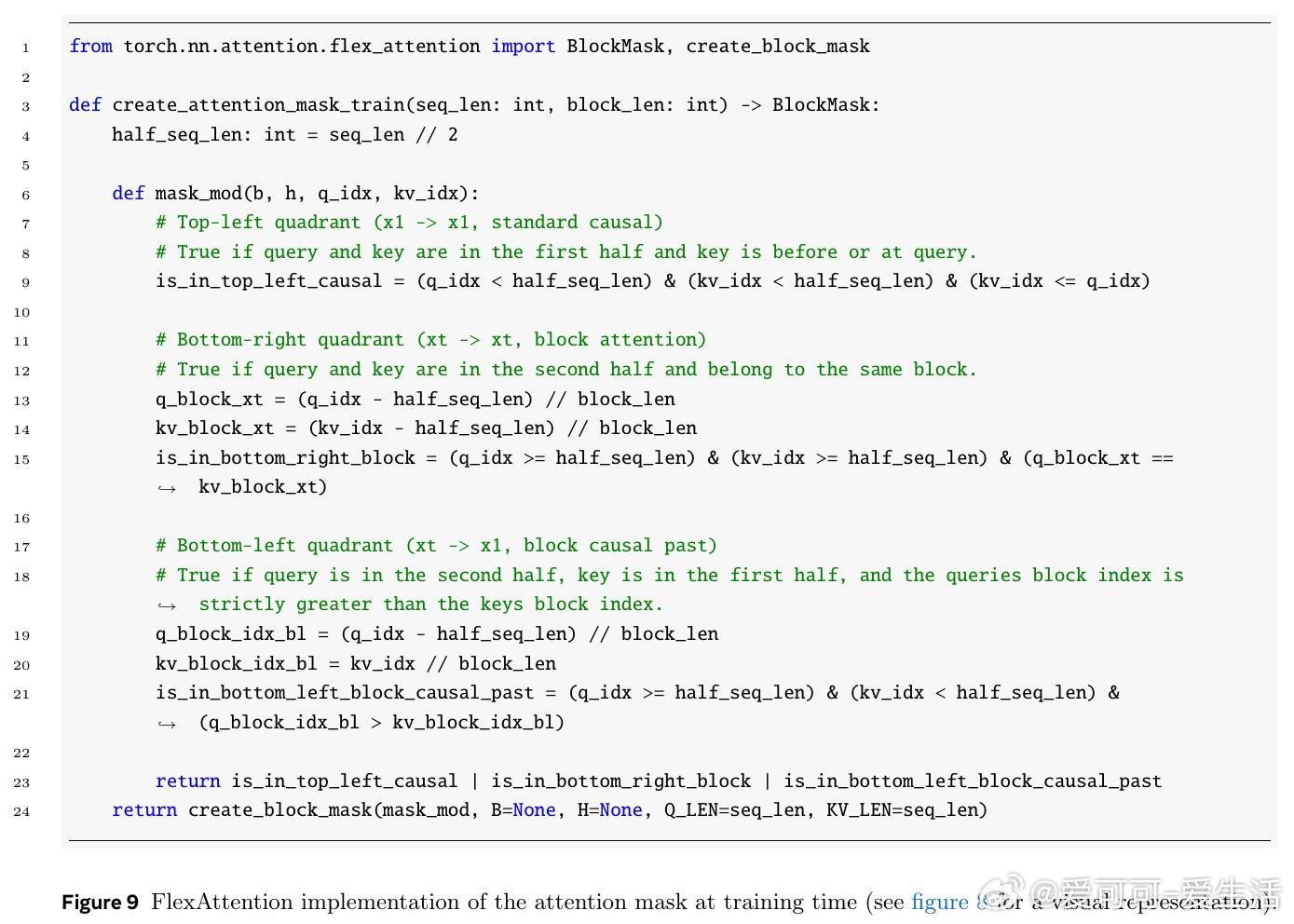
• SBD采样支持任意顺序非连续令牌预测,突破传统线性顺序限制,提升推理调度自由度和效率。
• 相关工作对比显示,SBD免去多模型或复杂多头架构,降低系统复杂度,兼顾性能与效率。
心得:
1. 将NTP与MATP无缝集成,在保持模型原有性能的前提下实现并行解码,揭示了语言模型推理加速的新范式。
2. 以掩码扩散模型的采样策略为灵感,动态选择解码子集,合理利用条件独立假设,兼顾速度与准确率,是提升大模型推理效率的关键。
3. 理论分析与实验证实,减少模型前向次数在硬件层面能有效转化为实际加速,强调了系统设计与算法创新的协同优化必要性。
了解更多🔗arxiv.org/ans/2509.04185
语言模型推理加速自动回归扩散模型并行解码机器学习