[LG]《Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning》Z Liu, J Liu, Y He, W Wang... [Alibaba Group] (2025)
强化学习(RL)助力大语言模型(LLM)推理能力提升的研究正迅猛发展,但现有方法缺乏统一标准和内在机制解析,导致实践中困惑重重。本文基于统一开源框架ROLL,系统复现并独立评估主流RL技术,提炼出关键洞见与应用指南,内容精华如下:
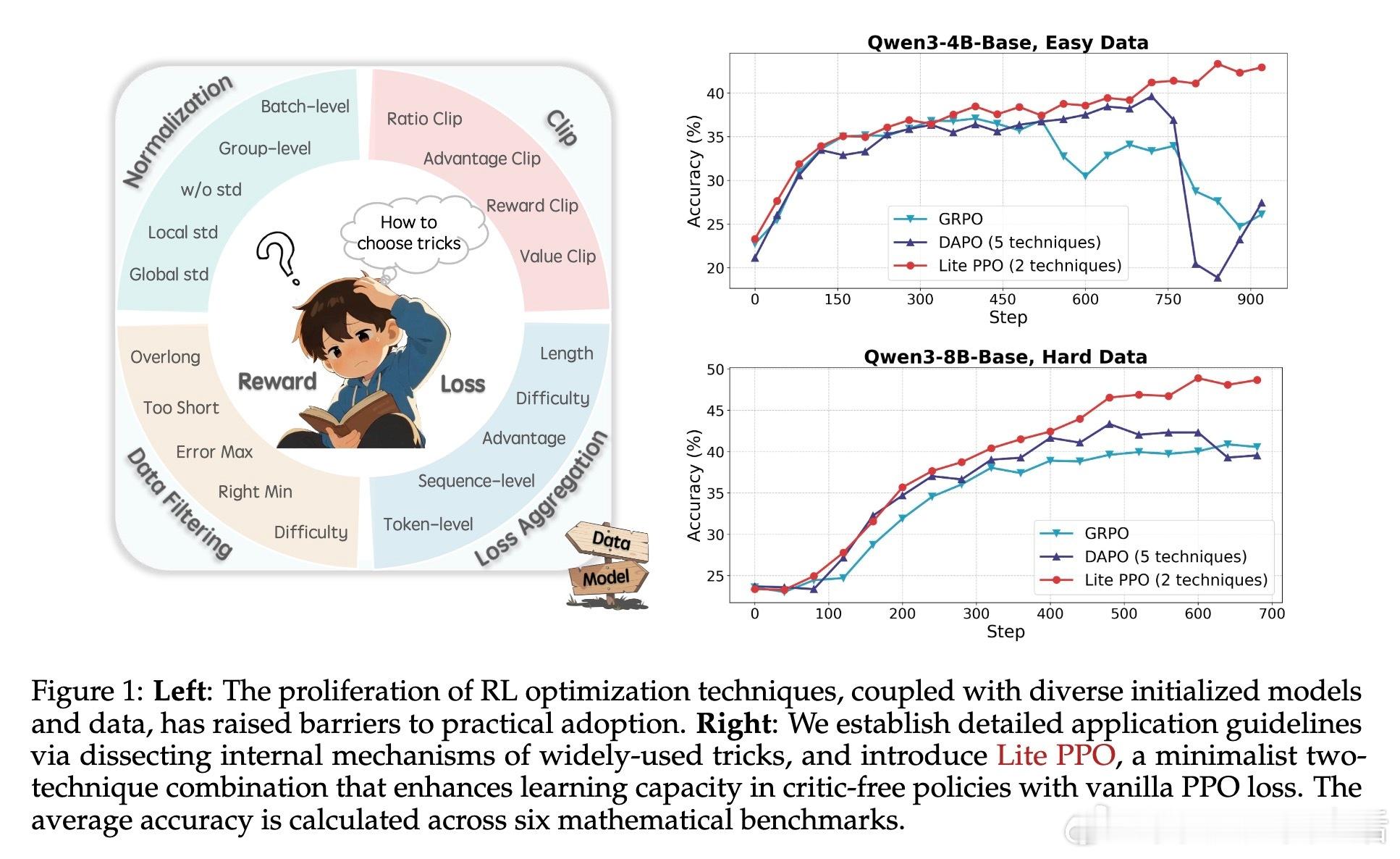
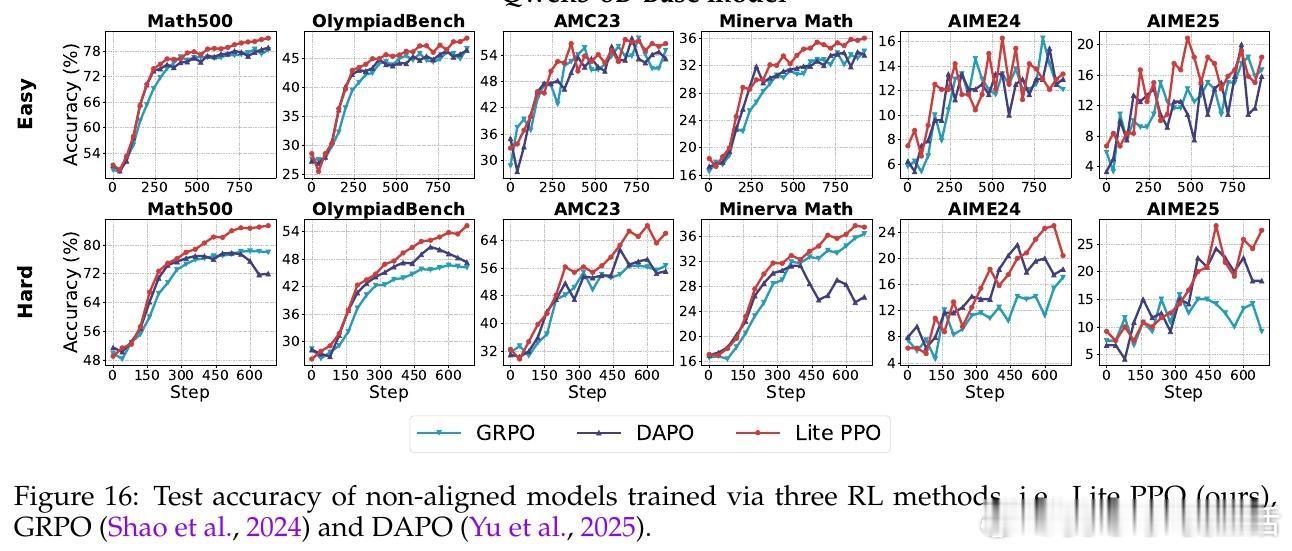
• 优化核心:Proximal Policy Optimization(PPO)为基础,结合Advantage Normalization(组内均值,批量标准差)与Token-level Loss Aggregation,构建简洁高效的Lite PPO,性能优于复杂方法如GRPO和DAPO。
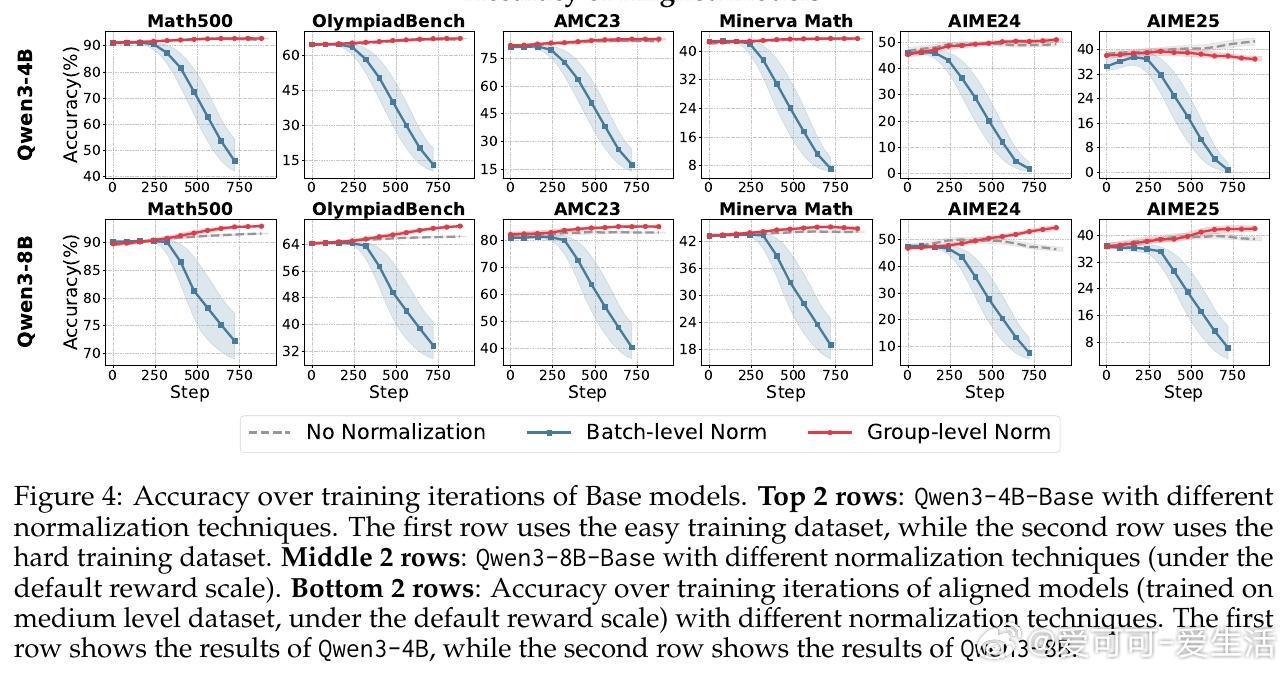
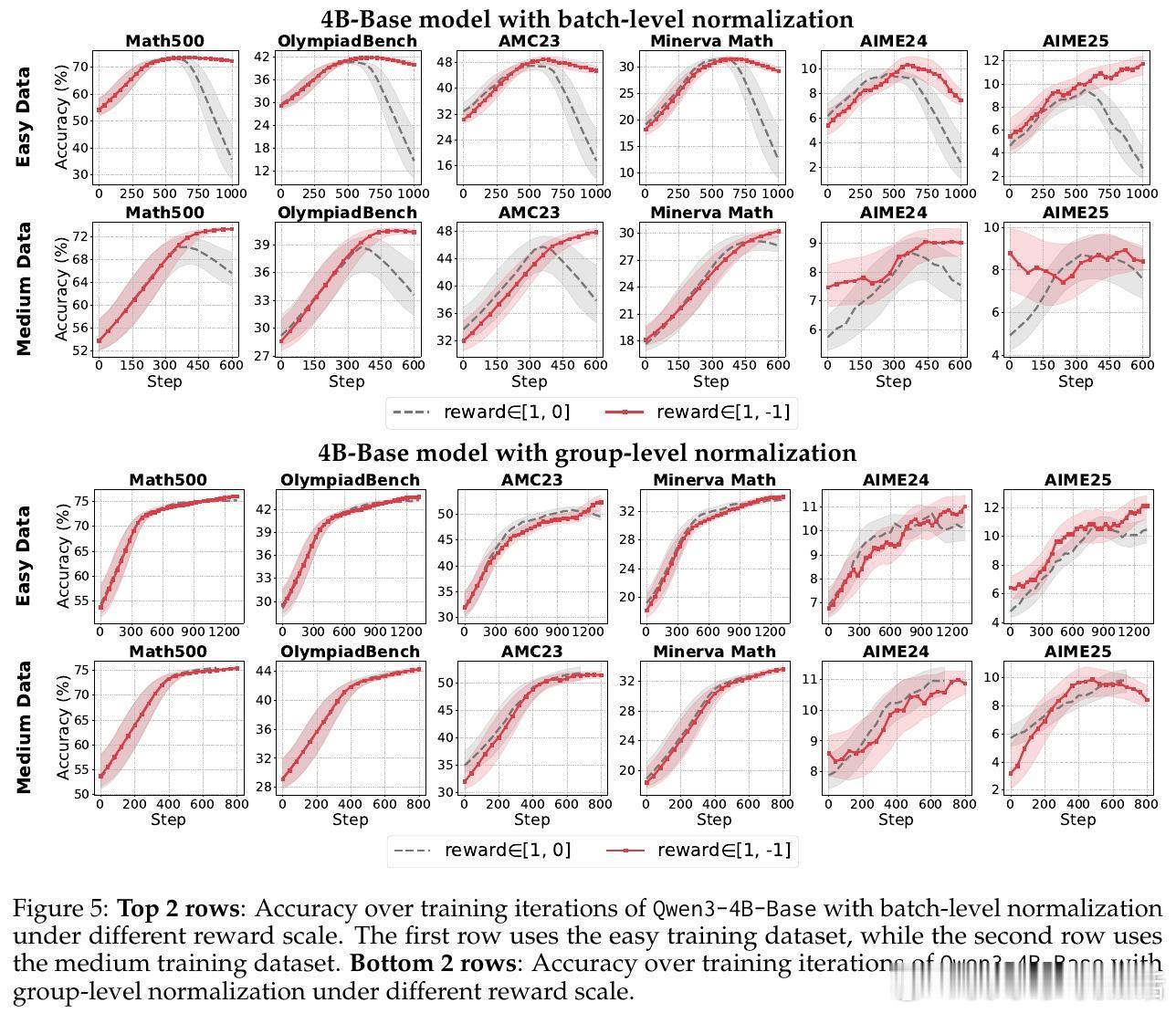
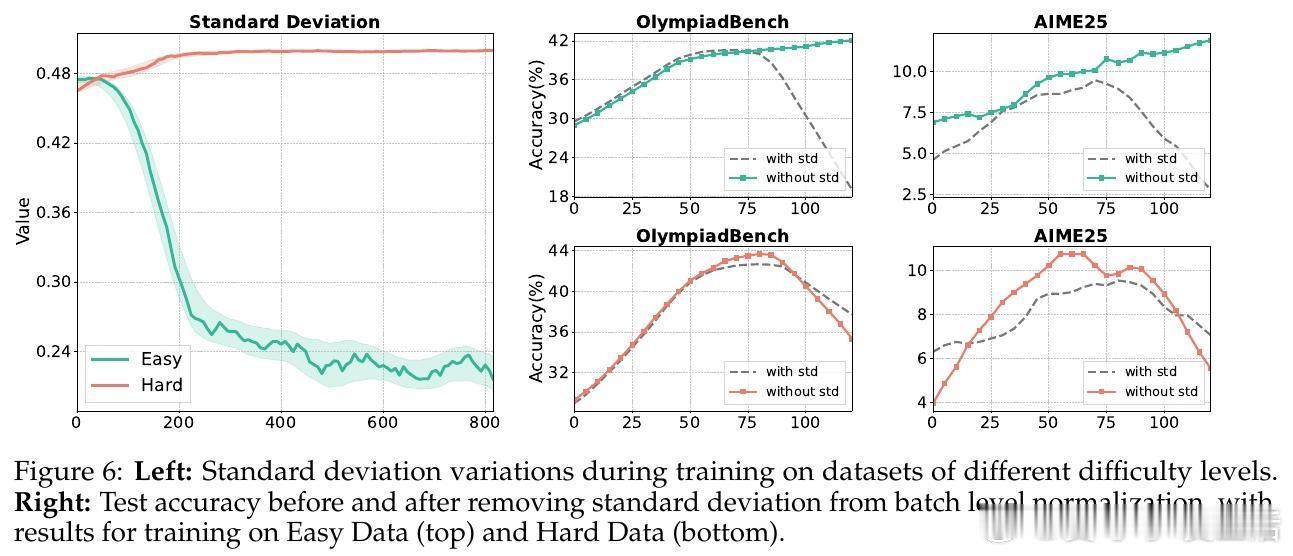
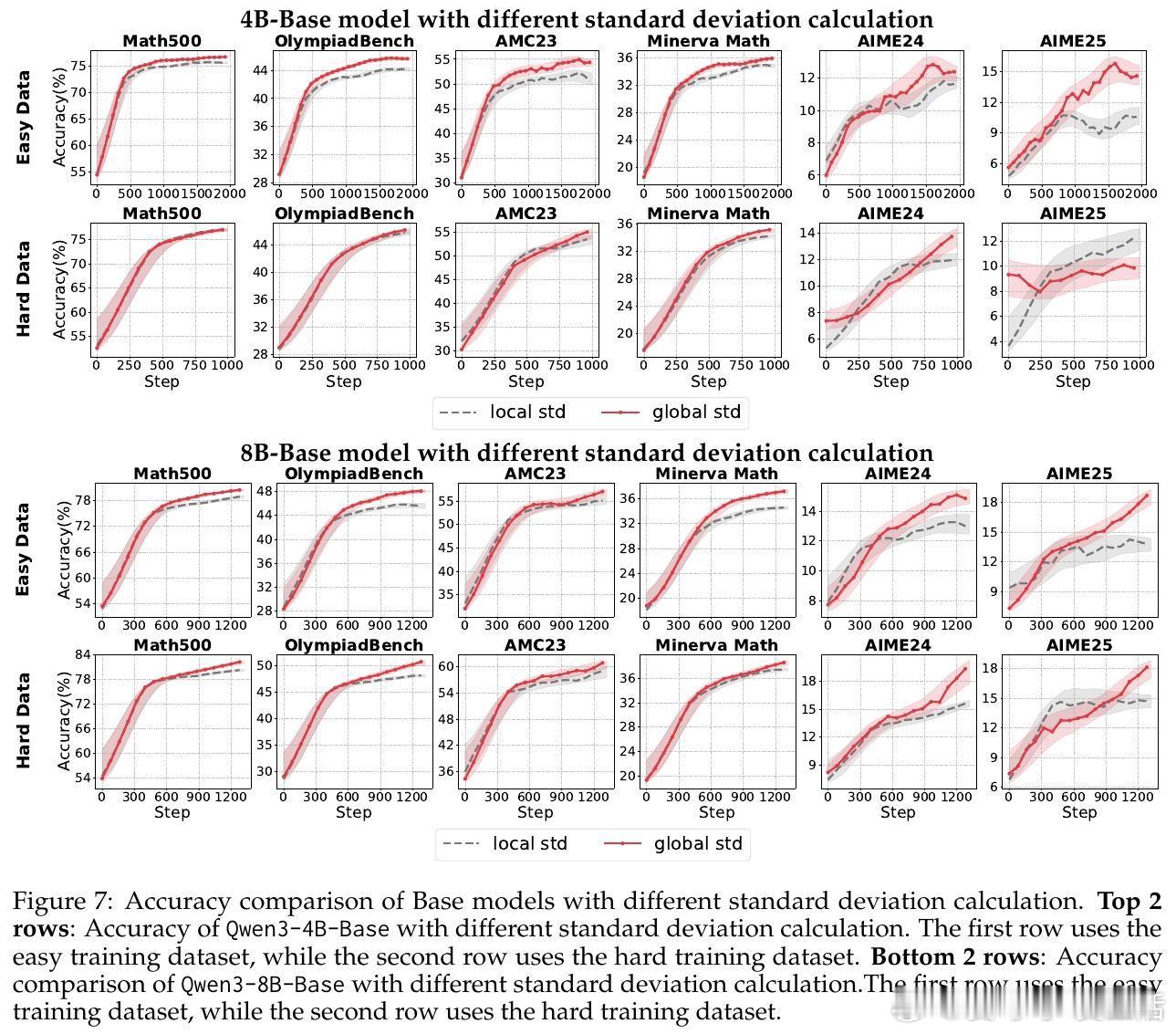
• 归一化策略:组级均值保证跨奖励机制鲁棒性,批量级标准差稳定性更佳。剔除标准差项可避免“难度偏差”引发的梯度爆炸,尤其在奖励分布高度集中时提升训练稳定性。
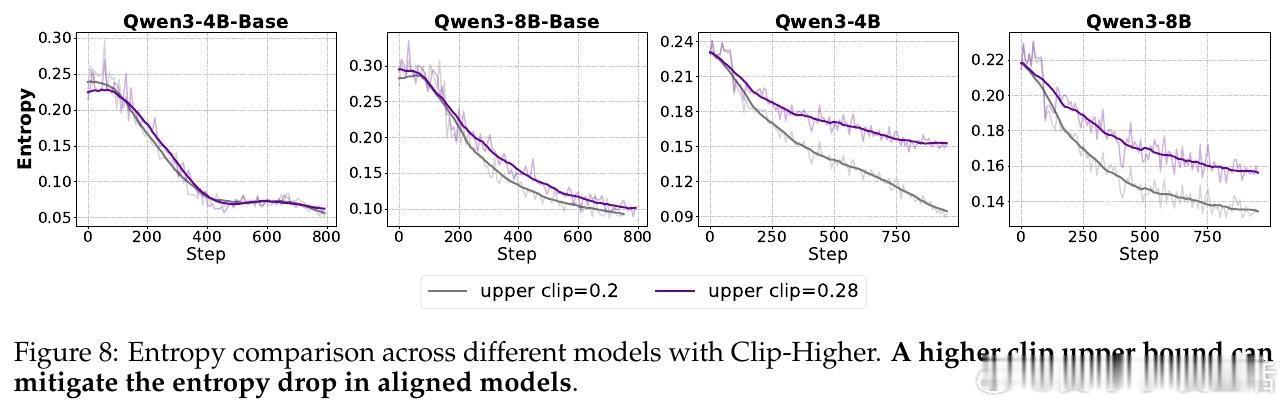
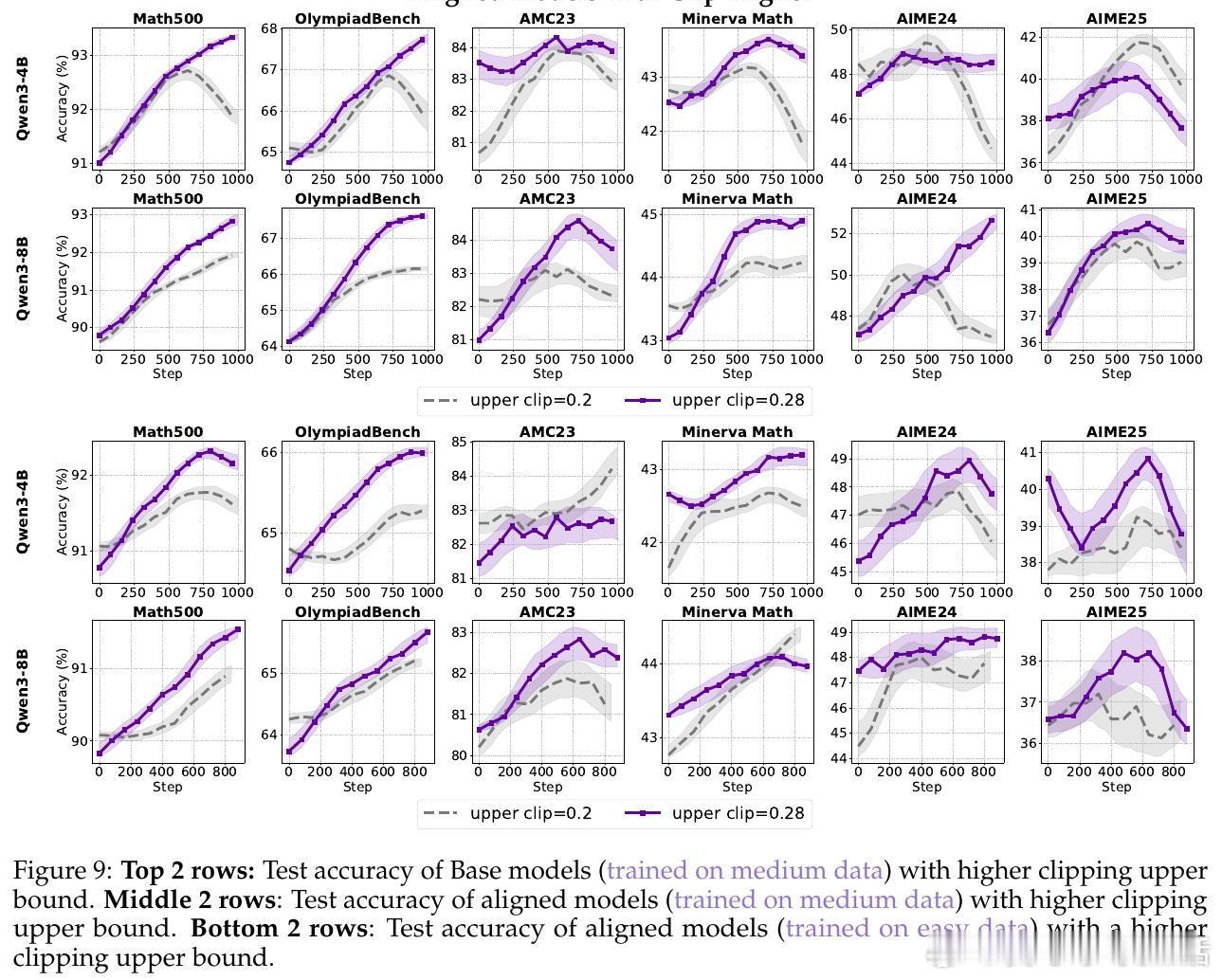
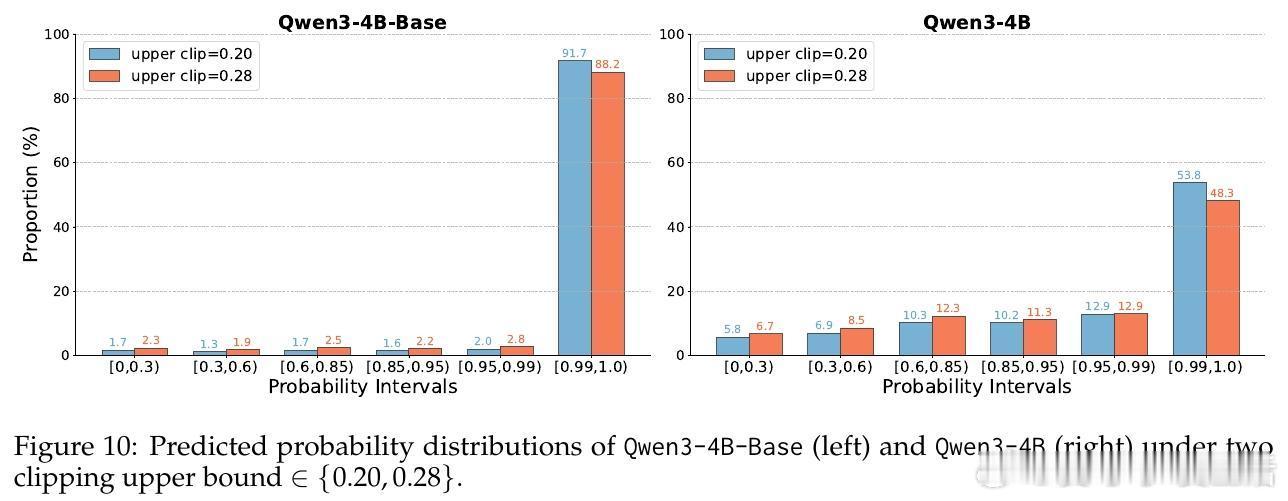
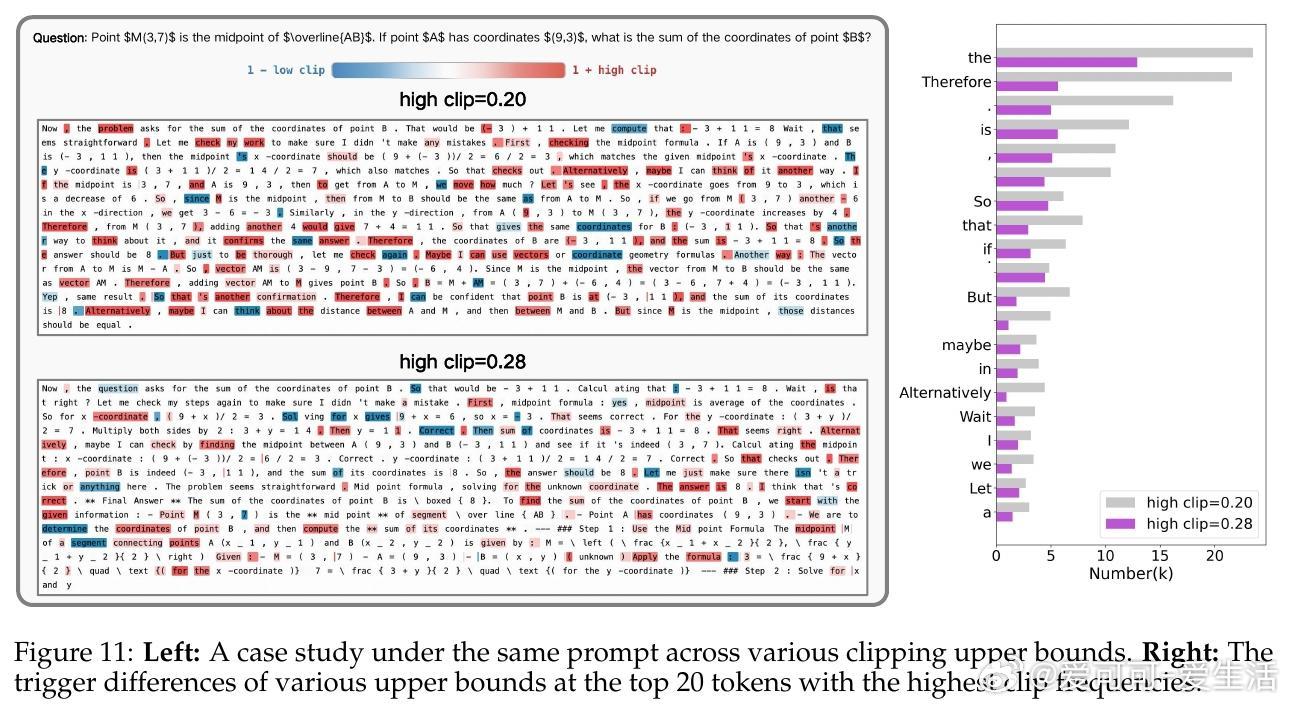
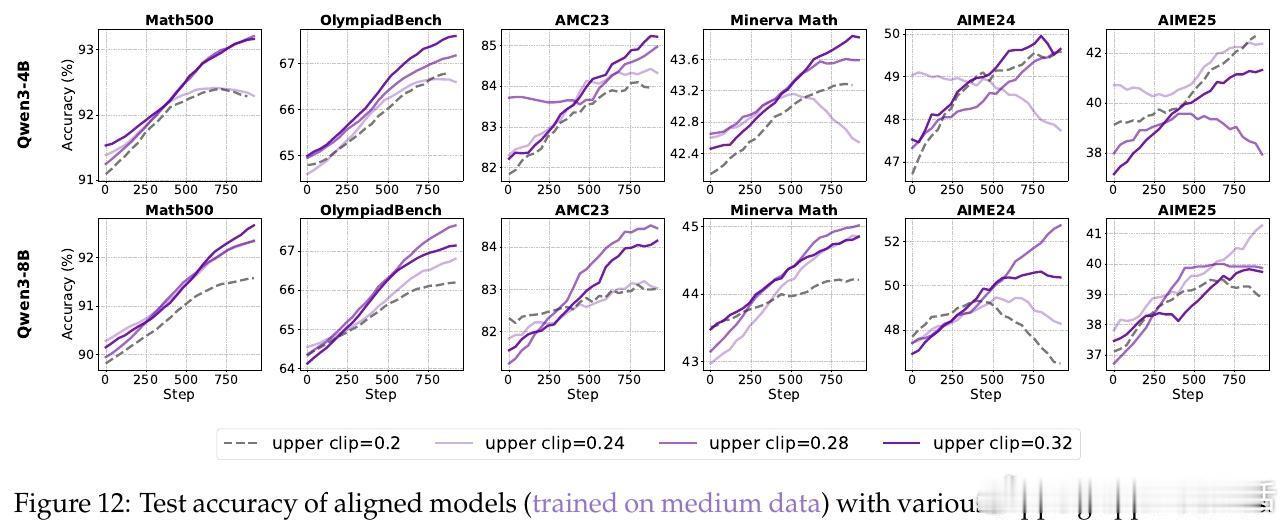
• 裁剪机制(Clip-Higher):传统裁剪限制模型探索,导致熵崩溃和创新受限。提升上限扩展策略空间,有效促进对高质量推理路径的探索,尤其对对齐模型表现显著提升,4B模型表现存在“尺度法则”,8B模型则无此规律。
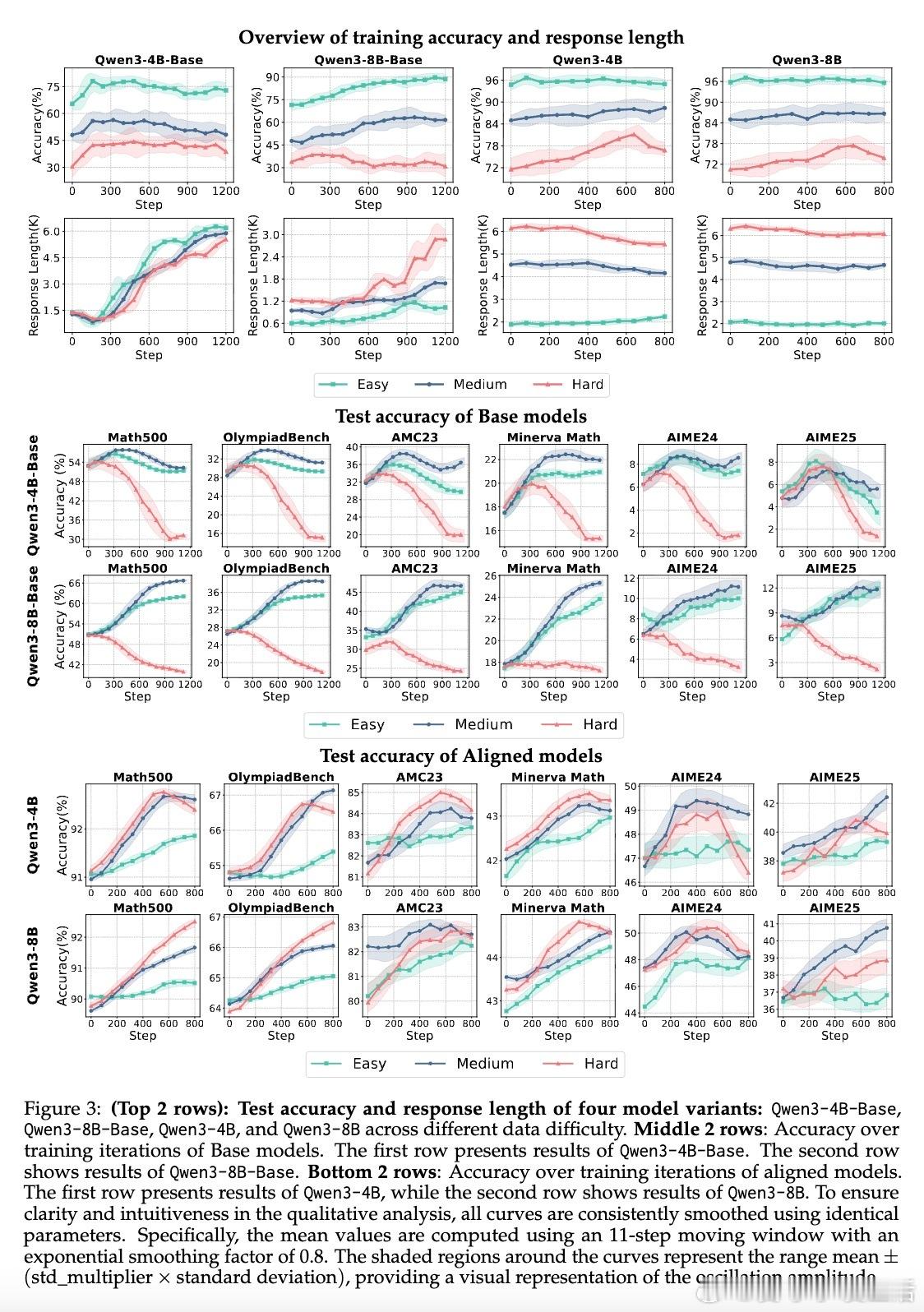
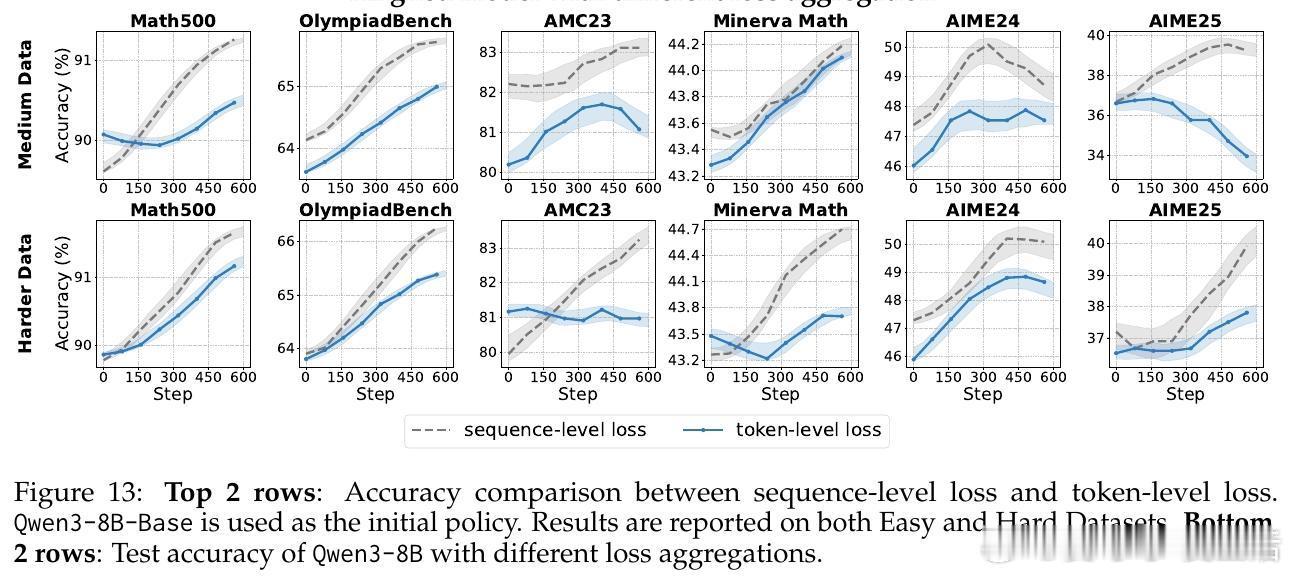
• 损失聚合:Token-level损失聚合更适合基础模型,防止长序列答案被弱化;对对齐模型,Sequence-level聚合更能保持推理结构的连贯性和稳定性。
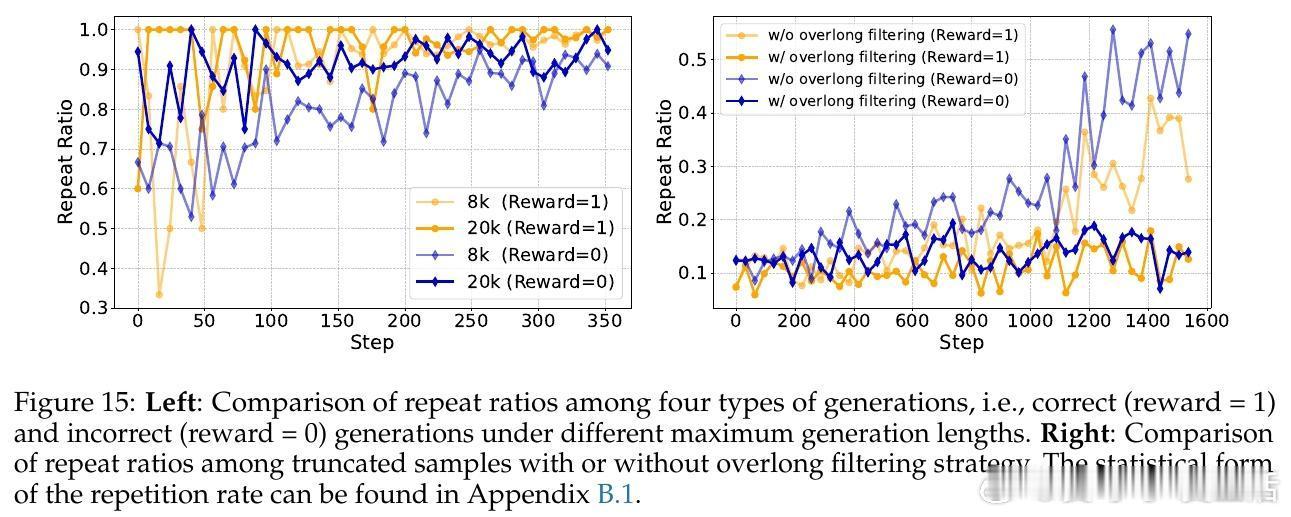
• 过长过滤(Overlong Filtering):对中短推理任务提升准确性和清晰度有效,但对长尾推理任务贡献有限。合理设定最大生成长度阈值,避免训练中因截断导致负样本污染。
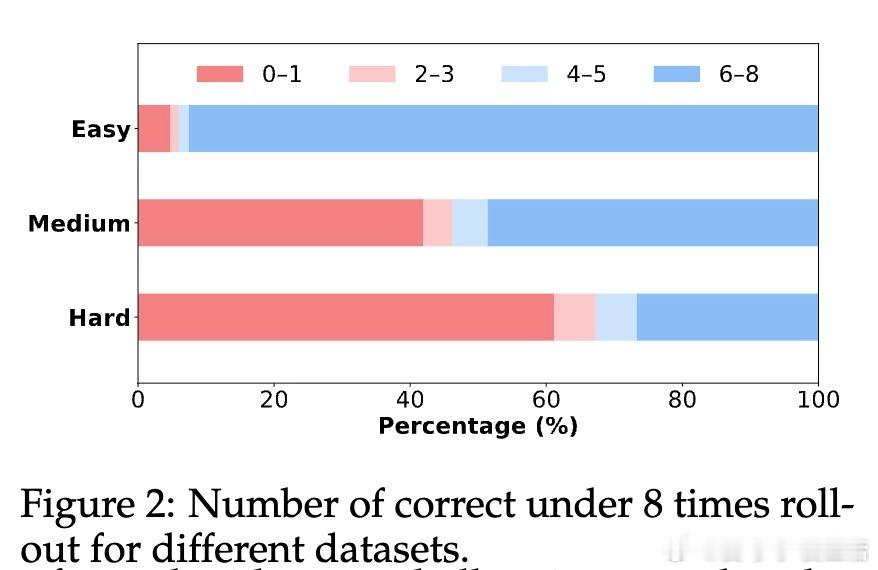
• 实验设计:涵盖4B与8B规模Qwen3模型,结合易、中、难三类开源数学推理数据集,广泛使用包括MATH-500、OlympiadBench等多层次数学评测。
• 结论启示:RL4LLM技术应根据模型规模、奖励机制和数据难度灵活选用,避免盲目堆砌复杂技巧。Lite PPO展示了以简驭繁的典范,强调实用性和稳定性的平衡。
• 未来展望:持续跟踪RL4LLM领域动态,推动统一模块化框架建设,发掘更简洁高效的RL算法,促进学术与工业界的透明协作。
🔗详情请见 arxiv.org/abs/2508.08221
强化学习大语言模型推理能力PPO机器学习人工智能模型优化