[LG]《μ-Parametrization for Mixture of Experts》J Małaśnicki, K Ciebiera, M Boruń, M Pióro... [University of Warsaw] (2025)
µ-Parametrization首次拓展至Mixture-of-Experts(MoE)架构,解决超大模型超参数调优难题,助力高效规模化训练。
• 理论创新:针对MoE设计专属µP方案,保证路由器与专家层在不同宽度下均能稳定学习特征。
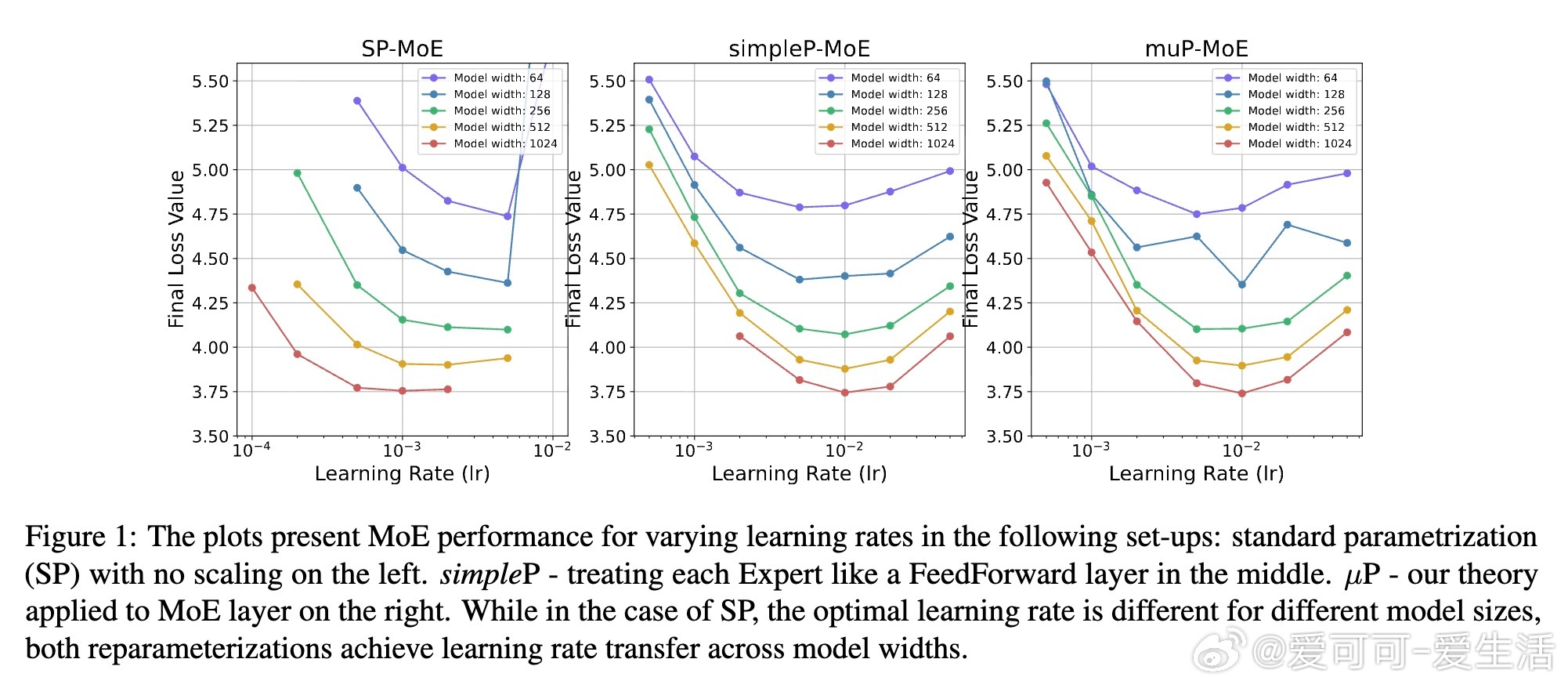
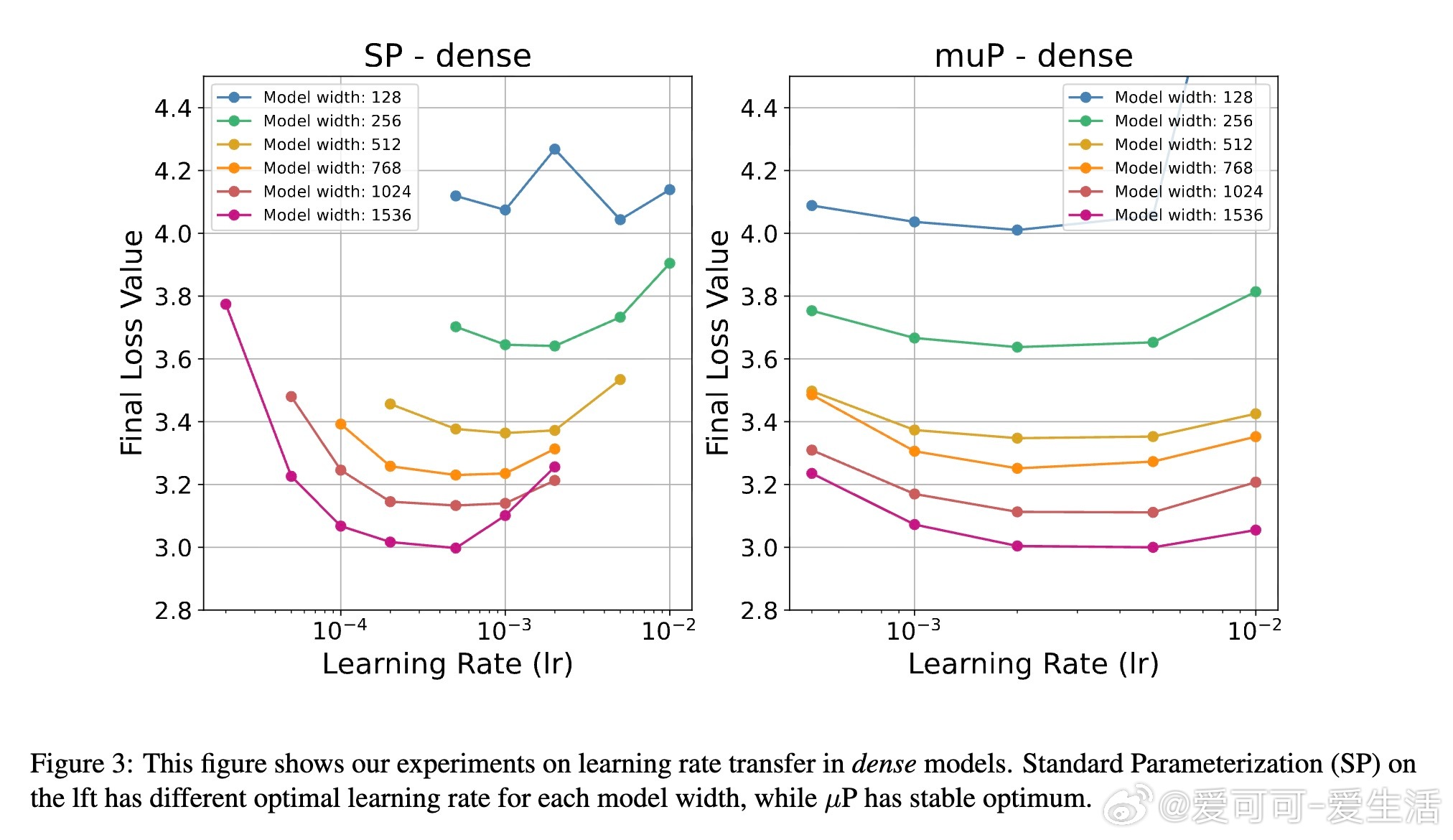
• 实证验证:实验证明该参数化可实现跨模型宽度的学习率零样本迁移,显著降低调参成本。
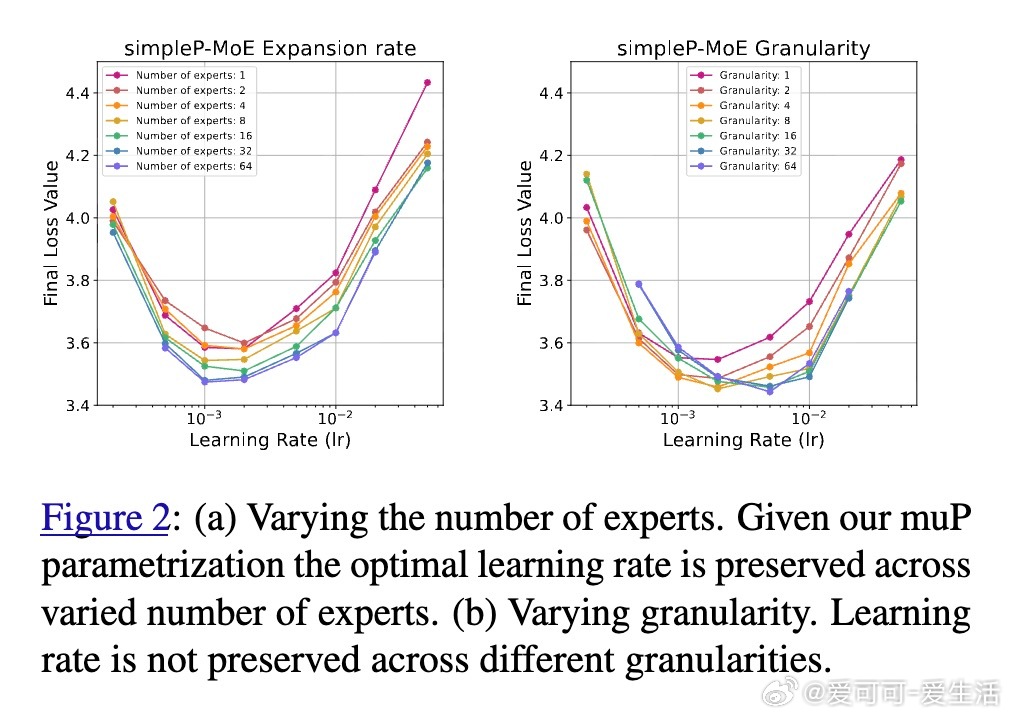
• 细节洞察:扩展专家数量保持学习率迁移性,调整top-k或专家粒度则破坏该性质,揭示MoE规模调整的关键边界。
• 方法底层:基于Tensor Programs V理论,区分路由器(输出权重)与专家(隐藏权重)梯度规模,确保训练动态一致。
• 实验设计:在Switch Transformer架构和C4数据集上,采用AdamW优化,验证不同模型宽度与专家配置对性能和稳定性的影响。
• 未来方向:专家粒度调节引发的学习率迁移失效提示需进一步理论完善,拓展µP在MoE多维度的适用性。
这项工作为大规模稀疏激活模型的训练参数化提供了坚实理论基础和实用指南,是推动高效训练与模型扩展的里程碑。
详情请见🔗 arxiv.org/abs/2508.09752
人工智能大规模模型MixtureOfExperts超参数调优机器学习理论Transformer