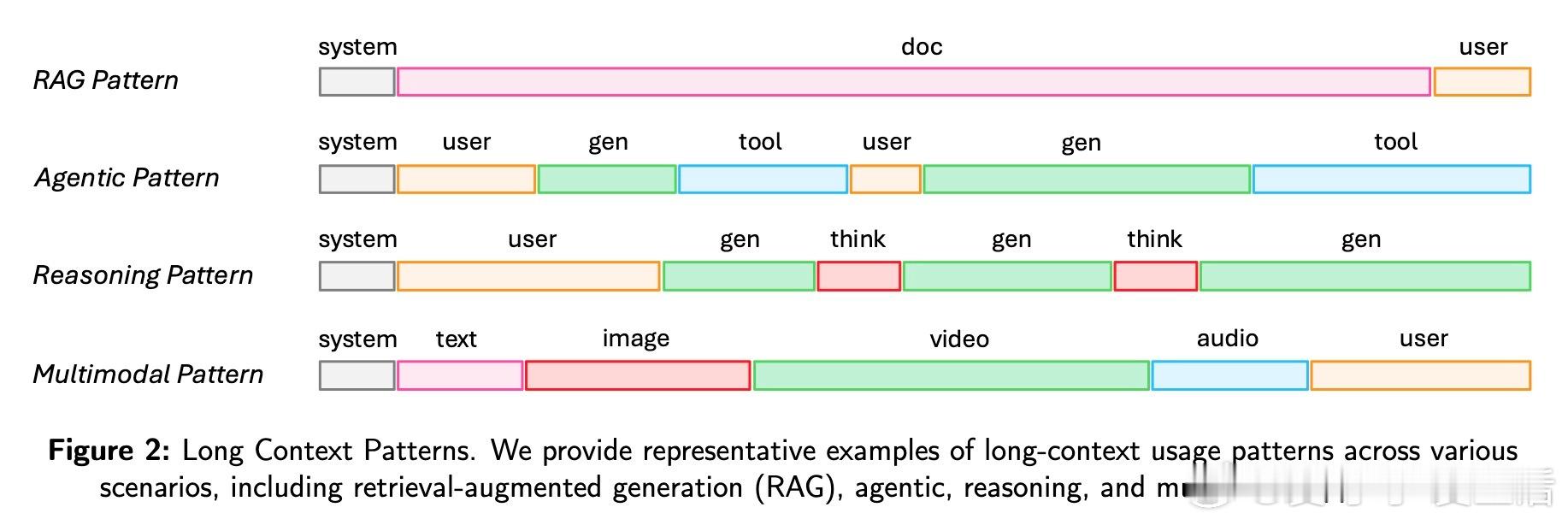
[CL]Speed Always Wins: A Survey on Efficient Architectures for Large Language Models
深度解读了提升大语言模型(LLMs)效率的核心架构创新,系统总结了七大范式:
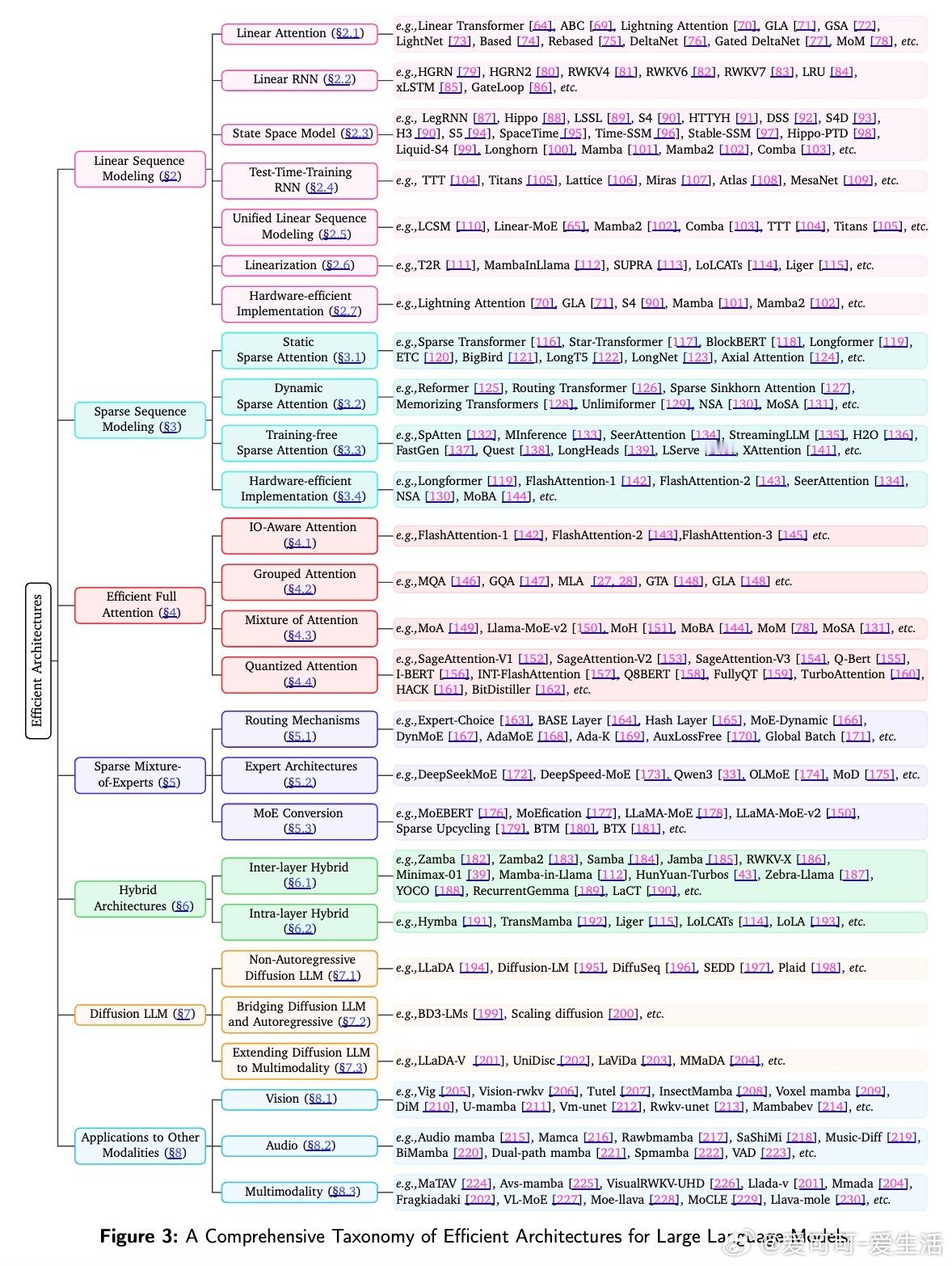
• 线性序列建模:通过线性注意力、线性RNN、状态空间模型(SSM)和测试时训练RNN,实现从传统Transformer的O(N²)到O(N)的复杂度跃升,极大降低计算和内存需求。引入门控机制与delta学习规则提升记忆表达能力和训练稳定性,代表模型如Linear Transformer、RetNet、S4、Mamba、RWKV系列。
• 稀疏序列建模:静态稀疏(如Longformer、BigBird)和动态稀疏(如Reformer、Routing Transformer)注意力机制,选择性关注部分token交互,保持性能同时削减开销。训练自由稀疏注意力则针对推理阶段优化,典型方案包括SpAtten、StreamingLLM、SeerAttention等。
• 高效全注意力:FlashAttention系列(FlashAttention-1/2/3)通过IO意识设计和硬件友好算法,优化内存访问与计算流水线,实现标准softmax注意力的加速;Grouped Attention(MQA/GQA/MLA/GLA)则通过KV缓存压缩减少内存带宽瓶颈。
• 稀疏专家混合(MoE):利用路由机制激活部分专家,扩展模型容量而不线性增加计算,支持动态top-k路由与负载均衡,专家结构多样(细粒度、共享、深度混合等),并提供从密集模型转换为MoE的多种策略,典型模型包括DeepSeekMoE、LLaMA-MoE、DeepSpeed-MoE。
• 混合架构:交替插入软max和线性序列层(层间混合),或层内头部/序列划分(层内混合),兼顾效率和表达力,代表如Zamba、Jamba、Hymba、LoLCATs、Liger等。
• 扩散式大语言模型:非自回归扩散模型(如LLaDA)支持并行解码,解决序列生成延迟和可控性难题,融合强化学习提升推理能力,结合自回归模型优势的混合扩散-AR模型(BD3-LMs)成为新兴方向。
• 跨模态应用:高效架构已广泛应用于视觉(分类、检测、分割、增强、生成)、音频处理及多模态融合,推动医学影像、自动驾驶、遥感等领域发展,典型应用包括Mamba、Vision-RWKV、Audio Mamba、LLaDA-V、MMaDA等。
此外,论文强调未来趋势:
• 算法-系统-硬件协同设计,提升边缘设备与专用芯片上的效率;
• 自适应注意力机制,更灵活地平衡性能与资源消耗;
• 更智能的MoE路由,降低通信与延迟;
• 超大规模模型的稀疏激活与内存架构创新;
• 适合边缘部署的高效小模型设计;
• 扩散模型在多任务和多模态生成中的潜力。
这份全面而系统的综述为高效LLM架构提供了清晰的分类和设计思路,成为推动未来可扩展、低资源开销AI系统的重要理论与实践指导。
详细阅读👉arxiv.org/abs/2508.09834
大语言模型高效架构线性注意力稀疏模型混合模型扩散模型多模态AI