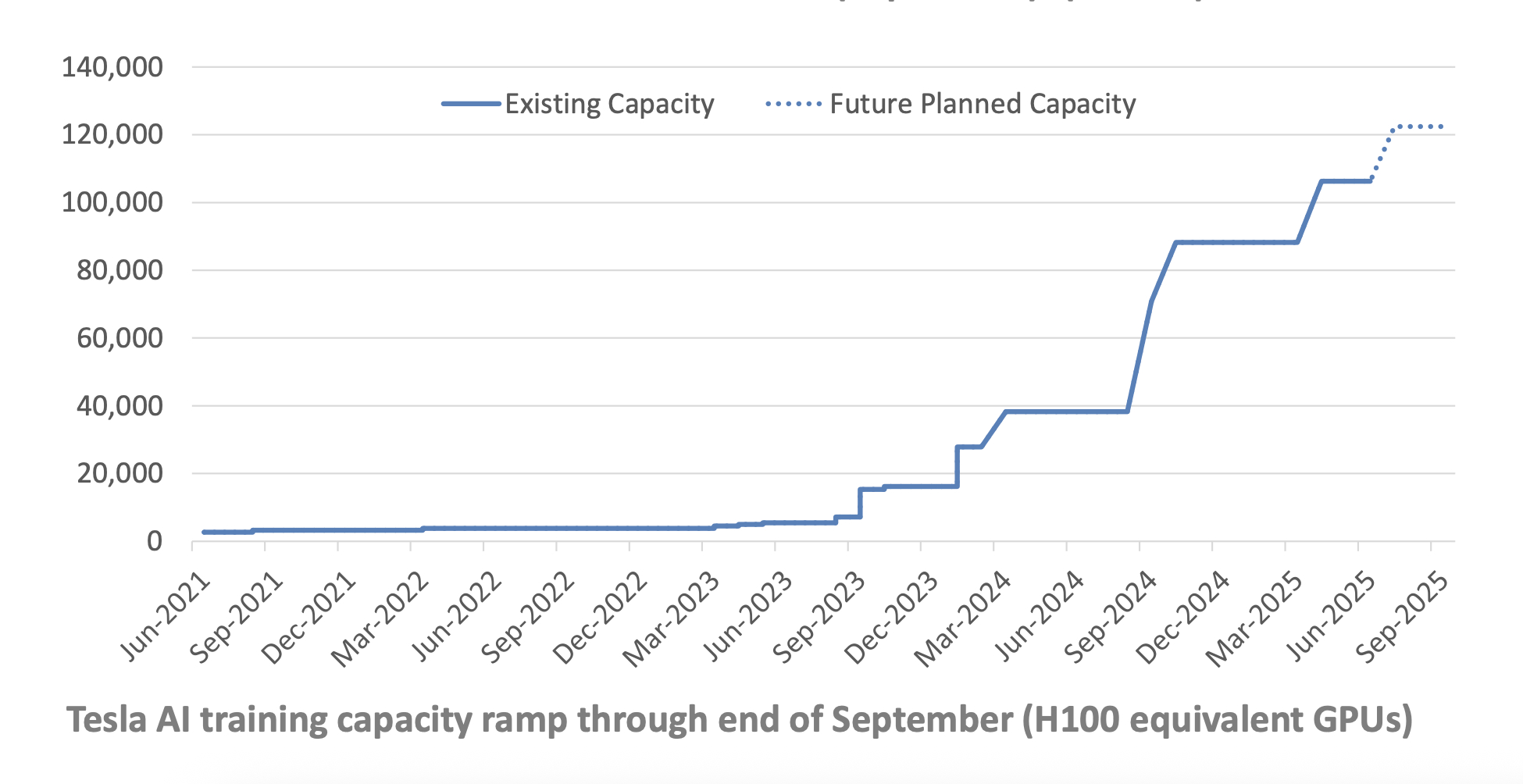
例行同步:截至目前,特斯拉算力集群总规模等效约 11 万张 H100,即 110 EFLOPS。
这其中位于 Giga Texas 的 Cortex 集群有几万张 H100 和 1.6 万张 H200,等效 6.7 万张 H100。在加州和纽约还有一些独立的 GPU 以及 Dojo 集群。
结合 FSD 的进展,FSD v13 实现了两个阶段性目标:1. 在全球各大市场验证模型的泛化性能;2. 将端到端的安全下限大幅提高,提到比最好的 rule-based 方案(辅助驾驶,非 L4)还要高。
下一阶段,FSD v14 的参数量目标比 FSD v13 增加 10 倍,这会让 AI4 的内存带宽一下顶到极限。其实 FSD v14 不过是 AI4 平台的第二个模型,但一下 10x,基本就到头了。
从 FSD v13 和 Robotaxi 版软件的进展线性推演,跨国市场还看不清楚,用 FSD v14 实现在美国本土实现跨州的 Robotaxi 和无监督 FSD 是可以预期的。