强化学习的策略优化正迎来全新突破,9种创新技术重塑LLM、VLM及agent训练范式:
• GSPO(Group Sequence Policy Optimization)
从token级别跃升到序列级别优化,通过序列裁剪和奖励提升稳定性,兼顾token细调。
• LAPO(Length-Adaptive Policy Optimization)
两阶段RL框架,自动学习并调节推理长度,提升推理效率与简洁度。
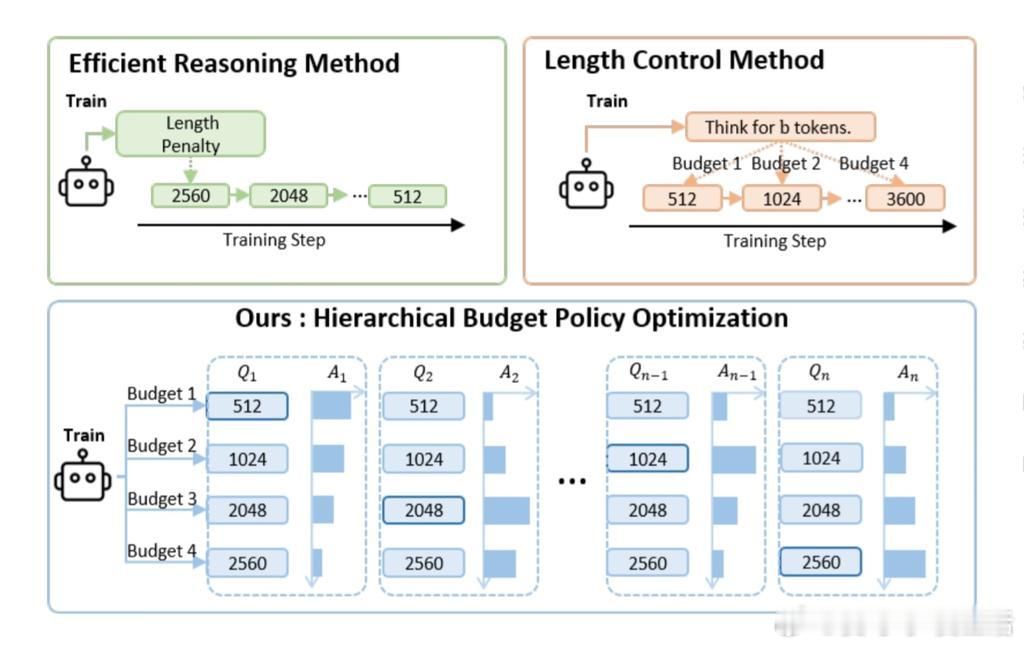
• HBPO(Hierarchical Budget Policy Optimization)
按问题复杂度自适应推理深度,基于token预算分组训练,奖励匹配任务难度。
• SOPHIA(Semi-off-policy RL)
结合VLM的在线视觉理解与LM的离线推理,逆向传播视觉奖励以强化慢思考推理。
• RePO(Replay-Enhanced Policy Optimization)
在on-policy RL中引入重放缓冲,利用多样离线样本扩充单提示训练数据,丰富模型视野。
• CISPO(Clipped Importance Sampling Policy Optimization)
采用重要性采样权重裁剪,避免token级裁剪丢失关键信息,不依赖KL惩罚,提升学习全面性。
• PAPO(Perception-Aware Policy Optimization)
增加基于KL的感知损失,强化视觉语言任务中的视觉对齐,准确率提升4–8%,感知错误减少约30%。
• OPO(On-Policy RL with Optimal Baseline)
微软提出,严格采用最新策略采样,减少off-policy偏差,降低梯度方差,无需辅助模型和正则化。
• EXPO(Expressive Policy Optimization)
结合大模型与轻量编辑策略,选择最优动作,无需对大模型反向传播,训练更高效。
本质上,这些方法突破传统单一token优化,强调序列级别、灵活预算、视觉感知与多样数据重用,推动RL在语言和视觉多模态任务中的长期进化。深入理解这些技术框架,有助于构建更稳健、高效、自适应的智能体训练体系。
详细解析🔗 huggingface.co/posts/Kseniase/659752309280422
强化学习 大模型训练 策略优化 多模态AI 机器学习 人工智能