机器之心报道
如今,强化学习(ReinforcementLearning,RL)在多个领域已取得显著成果。
在实际应用中,具有长时间跨度和稀疏奖励特征的任务非常常见,而强化学习方法在这类任务中的表现仍难令人满意。
传统强化学习方法在此类任务中的探索能力常常不足,因为只有在执行一系列较长的动作序列后才能获得奖励,这导致合理时间内找到有效策略变得极其困难。
假如将模仿学习(ImitationLearning,IL)的思路引入强化学习方法,能否改善这一情况呢?
模仿学习通过观察专家的行为并模仿其策略来学习,通常用于强化学习的早期阶段,尤其是在状态空间和动作空间巨大且难以设计奖励函数的场景。
近年来,模仿学习不仅在传统的强化学习中取得了进展,也开始对大语言模型(LLM)产生一定影响。近日,加州大学伯克利分校的研究者提出了一种名为Q-chunking的方法,该方法将动作分块(actionchunking)——一种在模仿学习中取得成功的技术——引入到基于时序差分(TemporalDifference,TD)的强化学习中。
该方法主要解决两个核心问题:一是通过时间上连贯的动作序列提升探索效率;二是在避免传统n步回报引入偏差的前提下,实现更快速的值传播。

论文标题:ReinforcementLearningwithActionChunking
论文地址:https://www.alphaxiv.org/overview/2507.07969v1
代码地址:https://github.com/ColinQiyangLi/qc
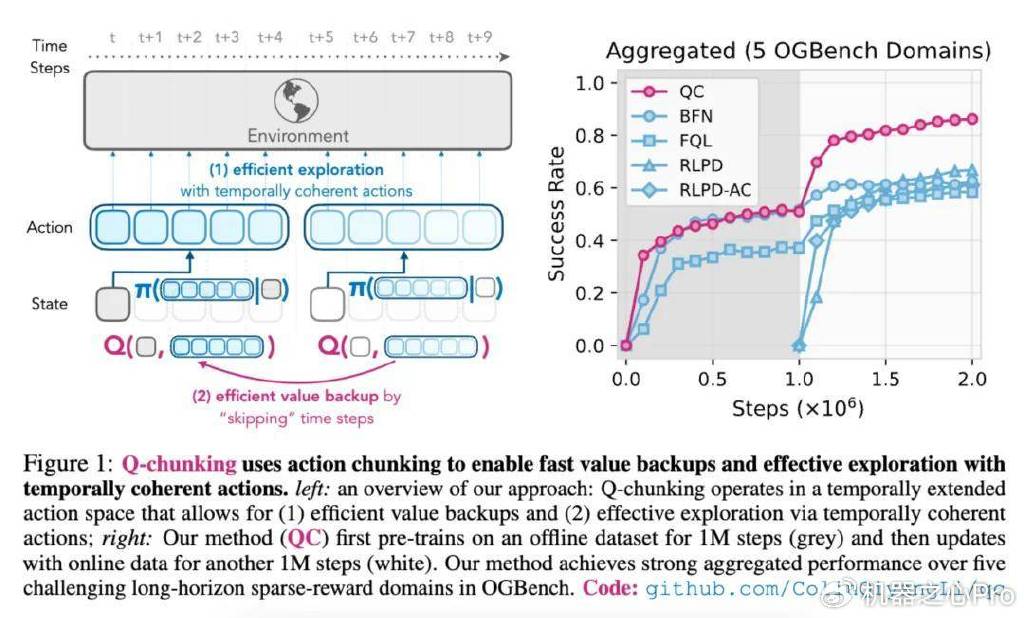
如下图1左所示,Q-chunking(1)使用动作分块来实现快速的价值回传,(2)通过时间连贯的动作进行有效探索。图1右中,本文方法首先在离线数据集上进行100万步的预训练(灰色部分),然后使用在线数据更新,再进行另外100万步的训练(白色部分)。
问题表述与研究动机
Q-chunking旨在解决标准强化学习方法在复杂操作任务中存在的关键局限性。
在传统强化学习中,智能体在每一个时间步上逐一选择动作,这常常导致探索策略效率低下,表现为抖动、时间不连贯的动作序列。这一问题在稀疏奖励环境中尤为严重——在此类环境中,智能体必须执行较长的、协调一致的动作序列才能获得有效反馈。
研究者提出了一个关键见解:尽管马尔可夫决策过程中的最优策略本质上是马尔可夫性的,但探索过程却可以从非马尔可夫性、时间上扩展的动作中显著受益。这一观察促使他们将「动作分块」这一原本主要用于模仿学习的策略引入到时序差分学习中。
该方法特别面向离线到在线的强化学习场景(offline-to-onlineRL),即智能体先从预先收集的数据集中进行学习,再通过在线交互进行微调。这一设定在机器人应用中尤为重要,因为在线数据采集成本高且可能存在安全风险。
方法概览
Q-chunking将标准的Q-learning扩展至时间扩展的动作空间,使策略不再仅预测单一步骤的动作,而是预测连续h步的动作序列。该方法主要包含两个核心组成部分:
扩展动作空间学习

算法实现
研究者展示了Q-chunking框架的两种实现方式:
QC(带有隐式KL约束的Q-chunking)
该分支通过「从N个中选择最优」(best-of-N)的采样策略,隐式地施加KL散度约束。其方法如下:
1.在离线数据上训练一个流匹配行为策略f_ξ(・|s)
2.对于每个状态,从该策略中采样N个动作序列(actionchunks)
3.选择具有最大Q值的动作序列:a*=argmax_iQ(s,a_i)
4.使用该动作序列进行环境交互与TD更新
QC-FQL(带有2-Wasserstein距离约束的Q-chunking)
该实现基于FQL(FlowQ-learning)框架:
1.保持一个独立的噪声条件策略μ_ψ(s,z)
2.训练该策略以最大化Q值,并通过正则项使其靠近行为策略
3.使用一种蒸馏损失函数,对平方的2-Wasserstein距离进行上界估计
4.引入正则化参数α来控制约束强度
实验设置及结果
关于实验环境和数据集,研究者首先考虑6个稀疏奖励的机器人操作任务域,任务难度各不相同,包括如下:
来自OGBench基准的5个任务域:scene-sparse、puzzle-3x3-sparse,以及cube-double、cube-triple和cube-quadruple,每个任务域包含5个任务;来自robomimic基准中的3个任务。
对于OGBench,研究者使用默认的「play-style」数据集,唯独在cube-quadruple任务中,使用了一个规模为1亿大小的数据集。
关于基线方法比较,研究者主要使用了以加速「价值回传」为目标的已有方法,以及此前表现最好的「离线到在线」强化学习方法,包括BFN(best-of-N)、FQL、BFN-n/FQL-n以及LPD、RLPD-AC。
下图3中展示了Q-chunking与基线方法在5个OGBench任务域上的整体性能表现,下图4中展示了在3个robomimic任务上的单独性能表现。其中在离线阶段(图中为灰色),QC表现出具有竞争力的性能,通常可以比肩甚至有时超越了以往最优方法。而在在线阶段(图中为白色),QC表现出极高的样本效率,尤其是在2个最难的OGBench任务域(cube-triple和quadruple)中,其性能远超以往所有方法(特别是cube-quadruple任务)。
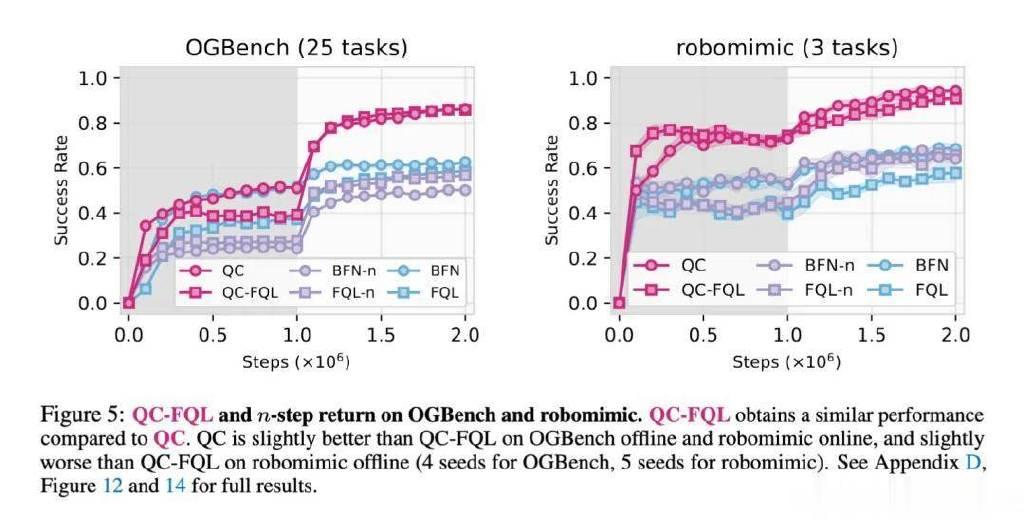
下图5为消融实验,比较了QC与其变体QC-FQL、以及2种n步回报的基线方法(BFN-n和FQL-n)。这些n步回报基线方法没有利用时间扩展的critic或policy,因此其性能显著低于QC和QC-FQL。实际上,它们的表现甚至常常不如1步回报的基线方法BFN和FQL,这进一步突显了在时间扩展动作空间中进行学习的重要性。
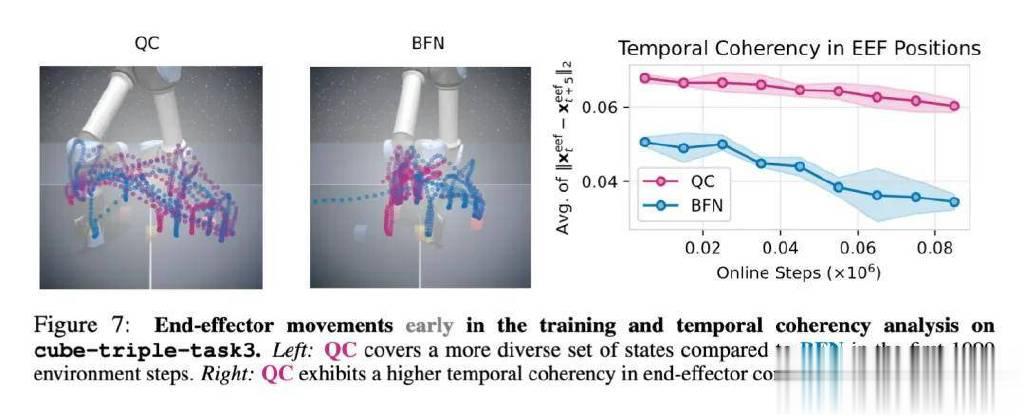
接下来探讨的问题是:为什么动作分块有助于探索?研究者在前文提出了一个假设:动作分块策略能够生成在时间上更连贯的动作,从而带来更好的状态覆盖和探索效果。
为了进行实证,他们首先可视化了训练早期QC与BFN的末端执行器运动轨迹,具体如下图7所示。可以看到,BFN的轨迹中存在大量停顿(在图像中心区域形成了一个大而密集的簇),特别是在末端执行器下压准备抓取方块时。而QC的轨迹中则明显停顿较少(形成的簇更少且更浅),并且其在末端执行器空间中的状态覆盖更加多样化。
为了对动作的时间连贯性进行定量评估,研究者在训练过程中每5个时间步记录一次3D末端执行器位置,并计算相邻两次位置差向量的平均L2范数。如果存在较多停顿或抖动动作,该平均范数会变得较小,因此可以作为衡量动作时间连贯性的有效指标。
正如图7(右)所示,在整个训练过程中,QC的动作时间连贯性明显高于BFN。这一发现表明,QC能够提高动作的时间连贯性,从而解释了其更高的样本效率。