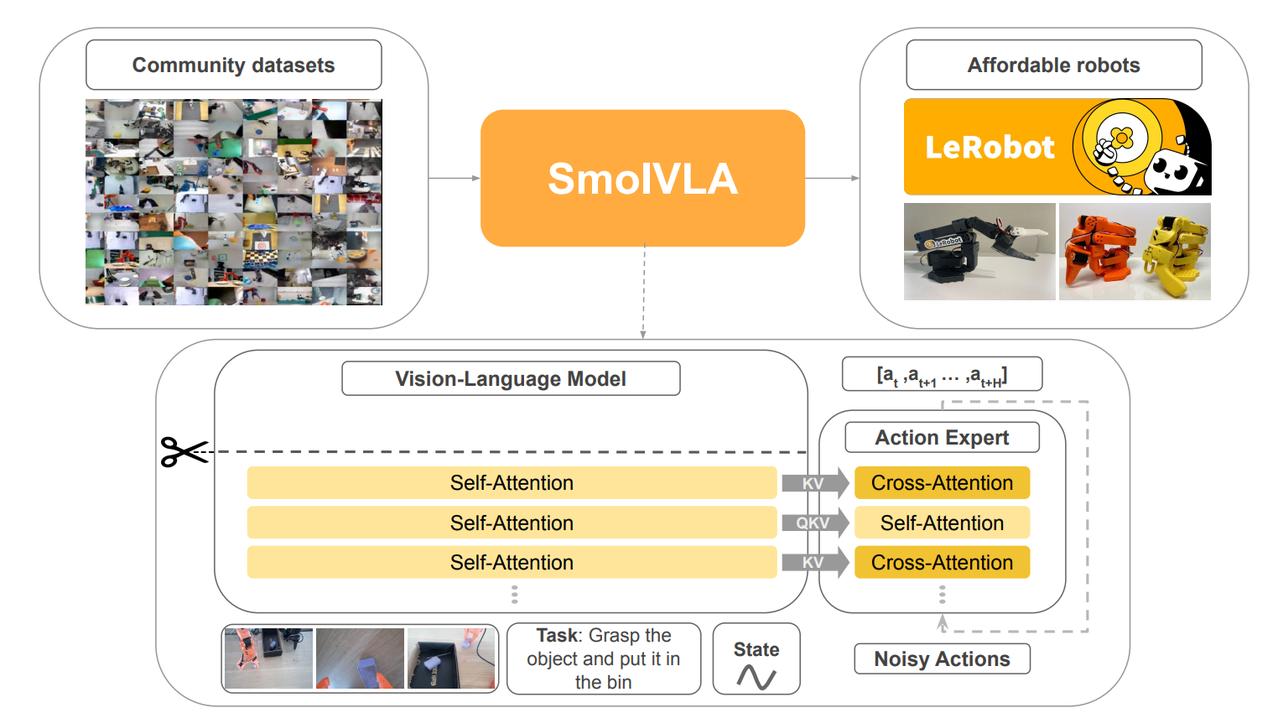
Face发布SmolVLA Hugging Face又整了个新活儿:一个能在MacBook上跑的机器人AI模型——SmolVLA。 有网友表示:这是我第一次距离机器人如此近,它堪称是最“亲民”的机器人AI。 具体来说,SmolVLA是一个450M参数量的视觉-语言-动作(Vision-Language-Action, 简称VLA)模型,目标是让更多人能低门槛地做出能“看、听、动”的机器人系统。 它的几个重点信息可以简单概括成: - 轻量但强大:比大模型更小更快,但在虚拟环境和真实机器人任务中的表现还更好; - 开源社区训练:数据都来自Hugging Face平台上的社区用户贡献,低成本、覆盖多样; - 硬件友好:不用集群服务器,普通消费级GPU甚至MacBook都能跑; - 异步推理机制:动作和视觉分开处理,机器人响应更快,控制更稳; - 实测性能不虚:在SO100、SO101这两个真实机器人测试集上,成功率和大模型相当,效率更高。 下面盘一盘技术方面,SmolVLA之所以能在轻量模型上跑出不俗表现,靠的不只是参数少,而是多个架构和工程层面的精细优化:【图1】 1. 感知层:SmolVLM-2视觉语言模型 使用SigLIP视觉编码器+SmolLM语言解码器组合。输入包括多路RGB图像、自然语言指令和机器人状态信息,全部转化为统一token送入Transformer。图像只保留64个视觉token,压缩比高达16倍。 2. 动作层:Flow Matching Transformer 与传统回归或离散token解码不同,SmolVLA用flow matching机制训练动作专家模块。简单说,就是让模型学会“从有噪声的动作预测回正确路径”,可以快速、非自回归地输出连续动作,控制更平稳。 3. 异步推理架构:推理和动作执行解耦,机器人在执行当前动作时,下一组动作在后台预判。通过early trigger机制+线程分离+chunk拼接,保持机器人持续响应,不停顿、不卡顿。 上述技术可以总结为:用尽可能少的参数、尽可能轻的推理路径,完成尽可能多样的真实控制任务。是一次对“小模型大能力”的系统性挑战。 话说,这并不是Hugging Face首次涉足机器人方向,之前他们还推出了LeRobot项目和几款廉价机器人设备,并收购了法国的机器人初创公司Pollen Robotics。SmolVLA算是这个体系里的核心模型之一。 目前,SmolVLA已在Hugging Face上线开放下载,感兴趣的开发者可以直接接入训练、微调或部署到家里的机器人臂上。有用户已经用它控制第三方机械臂跑起来了。 SmolVLA地址:huggingface.co/blog/smolvla