当下机器学习和人工智能蓬勃发展的使python语言成了香饽饽。但是在涉及大量数值计算时候,需要我们使用一些“数学”化的技巧(算法)才能达到简洁而高效的结果。本文虫虫就给大家介绍一种比较通用的这种技巧,即矢量化计算。矢量化计算可以替代数值计算中的循环操作,尤其是在进行大规模数的时候。
概述关于矢量化?矢量化是在数据集上实现 (NumPy) 数组运算的技术。在底层的算法中,通过使用线性代数中的矩阵运算可以一次性将操作应用于数组或所有列表对象(与一次操作一行的“for”循环不同)。本文我们将简单介绍几个常见计算用例,分别用循环和矢量化两种方法进行计算,对比起消耗时间。
求和首先,我们将看一个在 Python 中使用循环和向量化求数字和的基本示例,随机生成150万个数字,对其求和:
循环算法
import timestart = time.time()total = 0for item in range(0, 1500000):total = total + itemprint('sum is:' + str(total))end = time.time()print(end - start)
矢量化方法
import numpy as npstart = time.time()print(np.sum(np.arange(1500000)))end = time.time()print(end - start)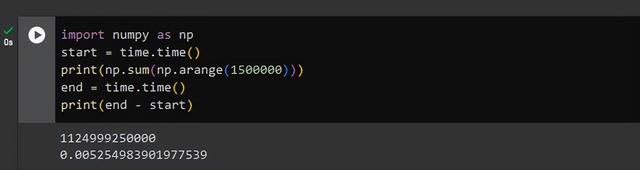
矢量化的执行时间减少了约18倍与使用range函数的迭代相比。 在使用Pandas DataFrame时,这种差异将变得更加显着。
数据框操作在数据科学中,在使用数据框时,开发人员使用循环通过数学运算创建新的派生列。在下面的示例中可以轻松地将循环运算矢量化。
基本操作创建数据框
数据框(DataFrame)是行和列形式的表格数据,比如创建一个包含500万行,a,b,c,d为标头4列的数据框,并对其用0-50的随机数赋值。
import numpy as npimport pandas as pddf = pd.DataFrame(np.random.randint(0, 50, size=(5000000, 4)), columns=('a','b','c','d'))df.shapedf.head()
将创建一个新列“ratio”来查找“d”列和“c”列的比率。
循环方法
import timestart = time.time()for idx, row in df.iterrows():# creating a new columndf.at[idx,'ratio'] = 100 * (row["d"] / row["c"])end = time.time()print(end - start)
结果用了6分多钟
矢量方法
start = time.time()df["ratio"] = 100 * (df["d"] / df["c"])end = time.time()print(end - start)
可以返现DataFrame情况下,两种方法耗时存指数级明显差异,循环方式慢的几乎无法让人接受,而矢量化方法耗时仅用0.1秒。
If-else分支实现的许多操作需要使用“If-else”类型的逻辑,可以轻松地将这些逻辑替换为矢量化操作。下面的例子中沿用上面创建的DataFrame,假设现在要求列“a”的某些条件创建一个新列“e”。
使用循环
import timestart = time.time()for idx, row in df.iterrows():if row.a == 0:df.at[idx,'e'] = row.delif (row.a <= 25) & (row.a > 0):df.at[idx,'e'] = (row.b)-(row.c)else:df.at[idx,'e'] = row.b + row.cend = time.time()print(end - start)
矢量化方法
start = time.time()df['e'] = df['b'] + df['c']df.loc[df['a'] <= 25, 'e'] = df['b'] -df['c']df.loc[df['a']==0, 'e'] = df['d']end = time.time()print(end - start)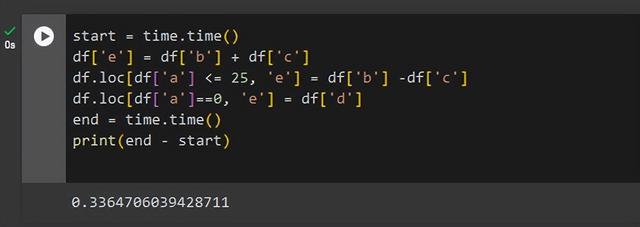
与循环方法相比矢量化操作所花费的时间快了近1700多倍
机器学习问题深度学习要求我们解决多个复杂的方程,并且需要解决数百万和数亿行的问题。在Python中运行循环来求解这些方程非常慢,矢量化则是适合的解决方案。例如,要计算以下多元线性回归方程中数百万行的y值:
Y= M1X1 + M2X2 + M3X3 + M4X4+ M5X5 + C这类问题也可以用矢量化代替循环。m1,m2,m3…的值是通过使用与x1,x2,x3…对应的数百万个值求解上述方程来确定的(为简单起见,只实现一个简单的乘法步骤)
首先创建数据
import numpy as npm = np.random.rand(1,5) x = np.random.rand(5000000,5)
x = np.random.rand(5000000,5)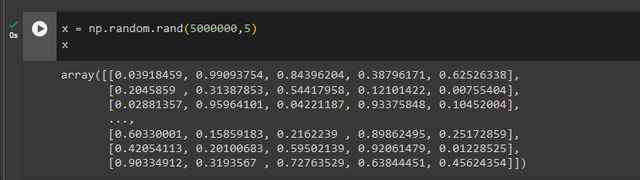
循环方法
import numpy as npm = np.random.rand(1,5)x = np.random.rand(5000000,5)total = 0start = time.process_time()cc=np.zeros(5000000,dtype=float)for i in range(0,5000000):total = 0for j in range(0,5):total = total + x[i][j]*m[0][j]cc[i]=totalend = time.process_time()print (end-start)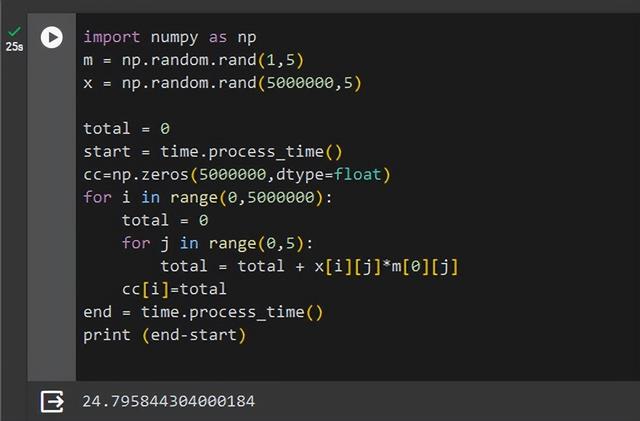
矢量化方法
该方法在矢量计算中实际上就是几个矢量的点积,熟悉线代同学应该都知道其计算原理,不了解同学可以看下图理解:
 start = time.process_time()np.dot(x,m.T)end = time.process_time()print (start-end)
start = time.process_time()np.dot(x,m.T)end = time.process_time()print (start-end)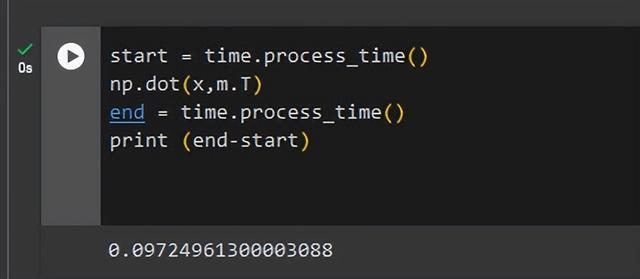
np.dot在后端实现矢量化矩阵乘法,比循环方法快了255倍。
总结
在Python数值计算中需要处理非常大的数据集时,Python 中的矢量化可以简化代码和极大的提高计算性能,矢量化计算可以作为一个通用的算法进行普遍使用,这对提高Python的计算非常有意义,而这种“数学化”编程思路也值得广泛采纳和使用。