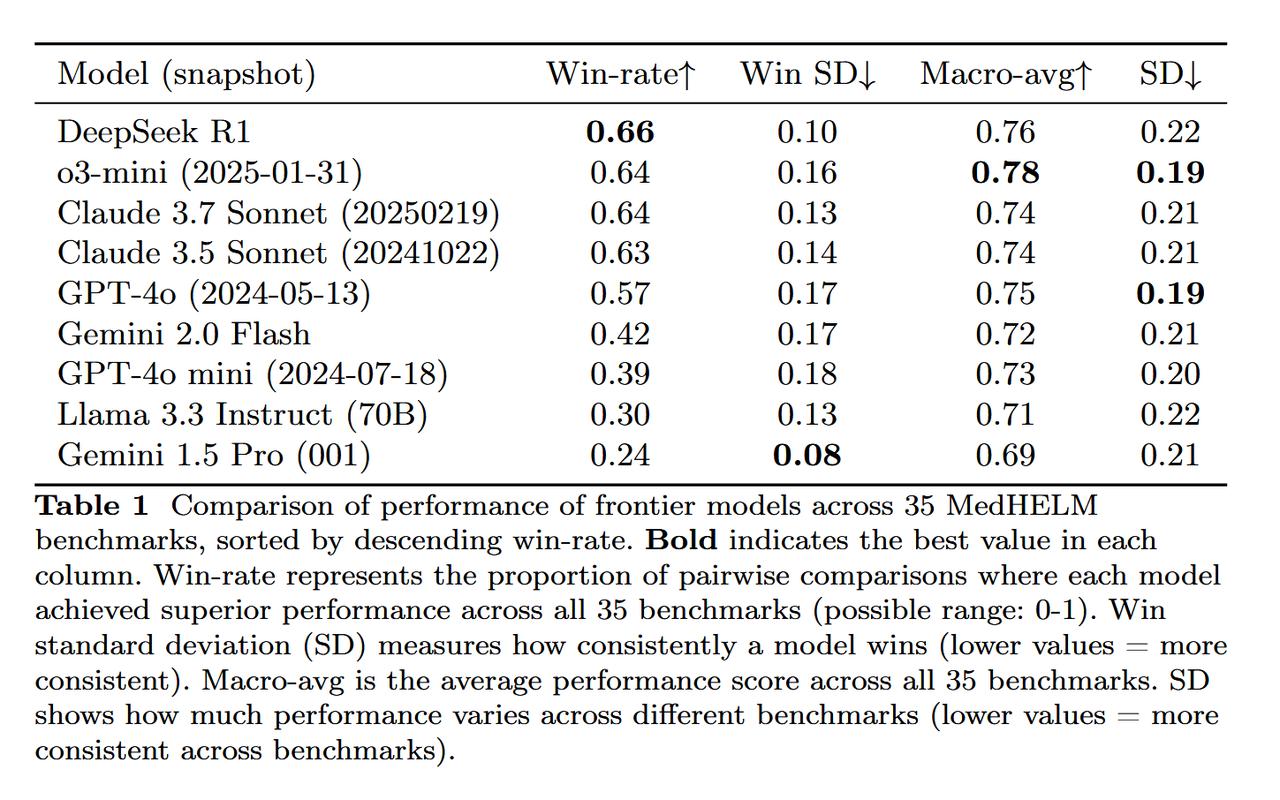
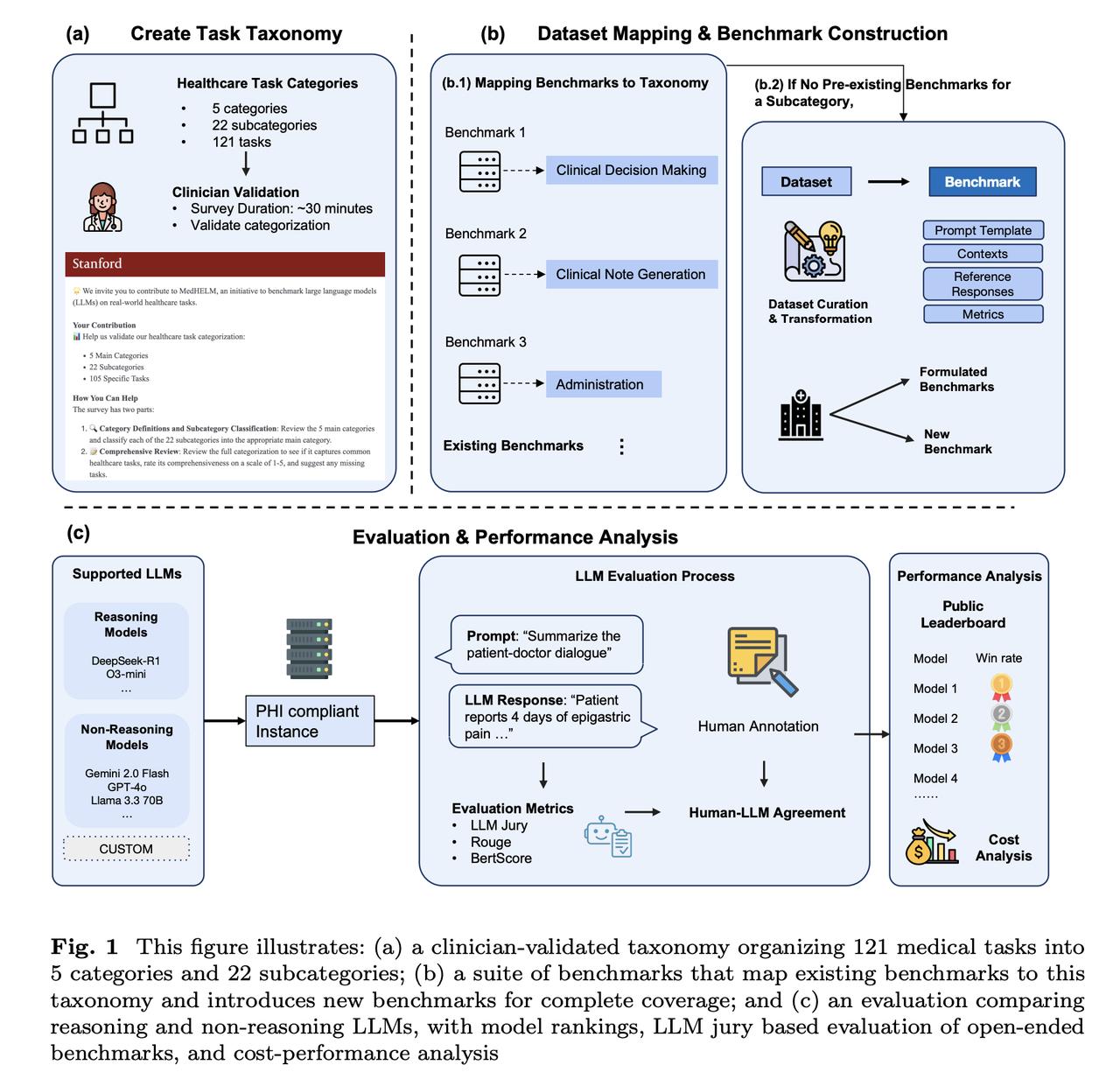
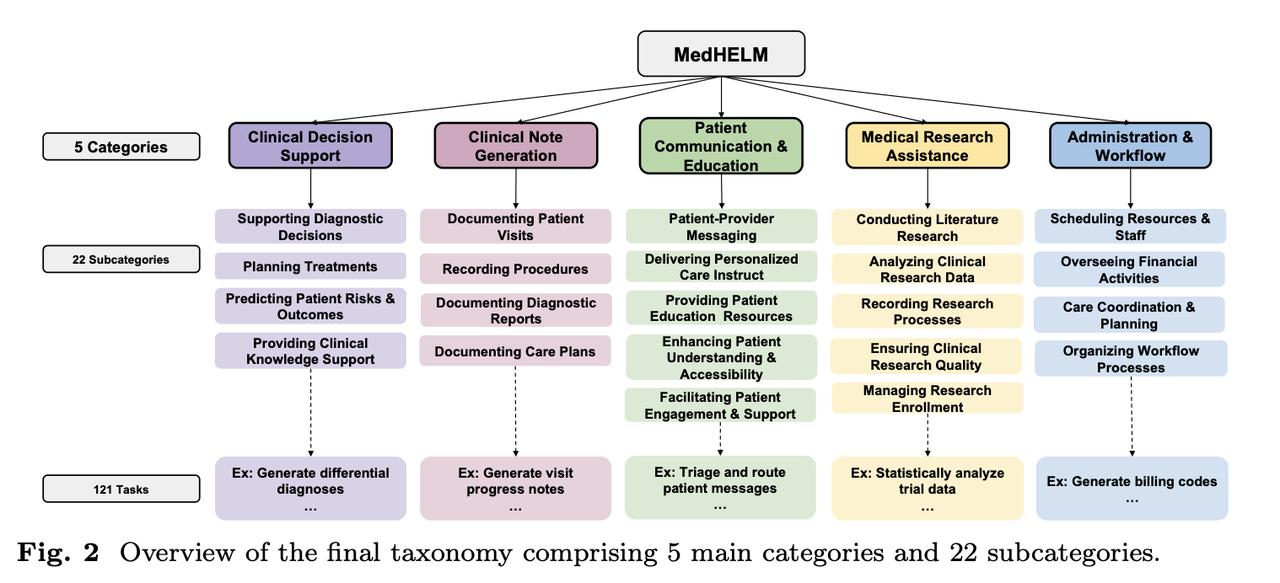
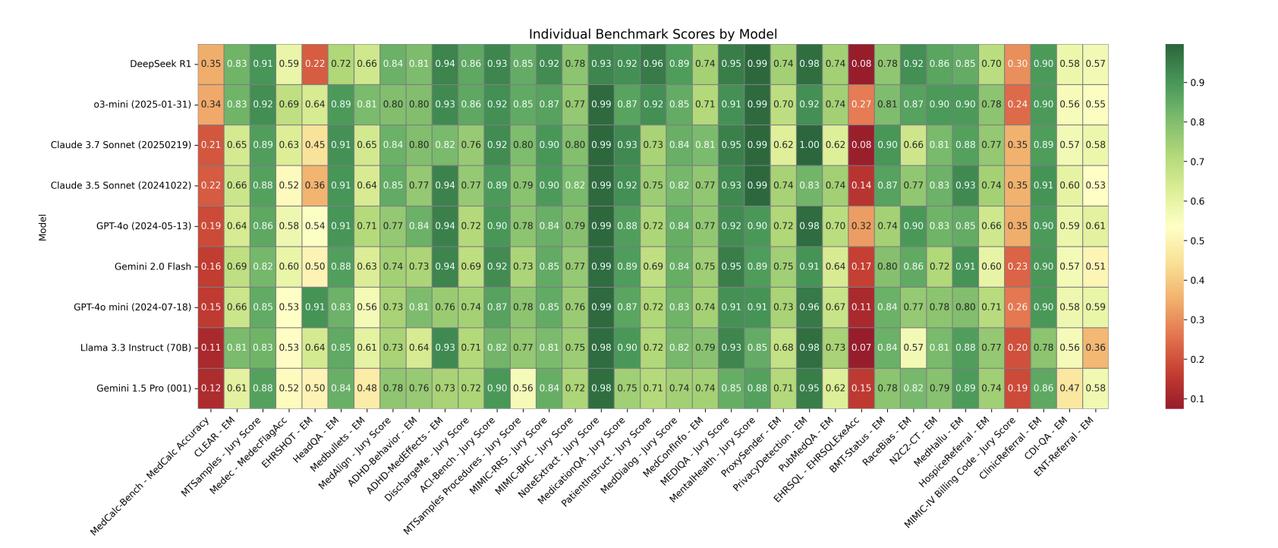
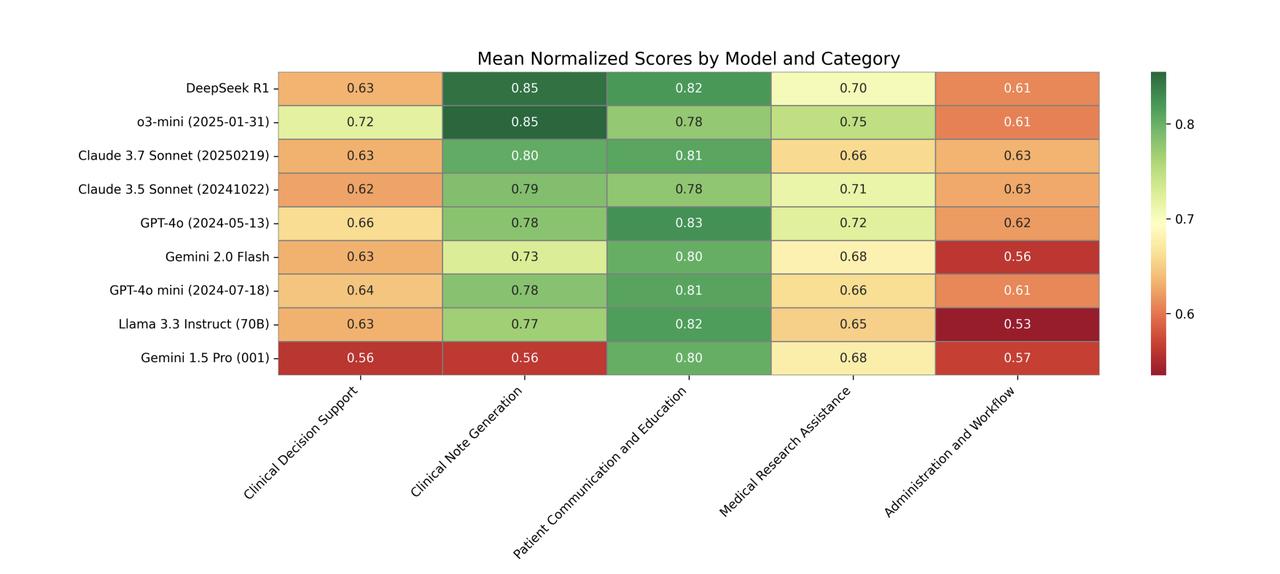
斯坦福团队大模型医疗应用评估,DeepSeek R1表现最佳!【图1】 回答医疗问题哪家模型强?这个问题还真不好说。虽然很多现有模型都能回答医疗问题,但《美国医学会杂志》指出: 大部分评估只基于标准化医学考试进行性能测试,很少用真实患者数据,就像用驾照笔试成绩来判断驾驶能力一样。 为了解决这个问题,斯坦福大学的研究团队最近又升级了一波早先推出的MedHELM评估框架。【图2】 这个新框架有以下特点: 1、医疗场景广泛 包含临床决策支持、临床病历生成、患者沟通教育、医学研究辅助、以及行政工作流的5大类、22子类和121项具体临床任务。经过29位执业医师验证,其分类体系非常符合临床实际。【图3】 2、基准测试套件全面 包含35个基准测试,涵盖了分类体系中的所有类别和子类别,其中包括17个现有基准测试、5个重新制定的基准测试和13个新基准测试。【图4】 3、评估更准确 使用由三个LLM组成的评审团LLM-jury对开放式基准测试进行评估,结果显示与临床医生的评分高度一致(ICC=0.47),甚至超过了临床医生之间的平均一致性。 利用这个新评估框架,研究团队再次测试了九个主流前沿大模型,结果如下: DeepSeek R1表现最好:在35个基准测试中,DeepSeek R1和o3-mini等推理模型表现出色,分别获得了66%和64%的胜率。 多数模型擅长病历和沟通:大多数模型在临床病历生成(0.73-0.85)和患者沟通教育(0.78-0.83)方面表现强劲。 研究辅助一般,决策和行政偏弱:在医学研究辅助方面表现中等,而在临床决策支持和行政工作流程任务中表现较弱。【图5】 推理模型虽然性能优越,但计算成本较高。Claude 3.5 Sonnet在较低的估计成本下提供了与顶级模型相当的性能。【图6】 项目主页: 论文地址: