毫无疑问,在AI技术爆发式增长的驱动下,企业数智化转型正迈入规模化“倍增创新”的阶段,特别是以DeepSeek、千问等为代表的AI大模型技术的持续突破,以及应用场景向产业纵深的加速渗透,都掀起了一场覆盖全产业链的智能化革命,这场变革不仅将AI创新触角延伸至社会经济的神经末梢,更重构着千行百业的底层商业逻辑,重塑数字经济时代的生存法则。
在此过程中,作为AI时代的关键底座,算力技术也在不断变化。一方面,万卡乃至十万卡量级算力集群的涌现,带来了极致算力使用效率的达成、海量数据的处理能力,以及超大规模集群的互联互通等方面的挑战。毕竟集群规模的线性增长并不等同于算力的同步线性提升,而要实现算力的高效发挥,就必须对卡间以及节点间的互联网络进行深度优化,同时在软硬件适配方面开展精细调优工作。
此外,超万卡集群迫切需要具备更为高效、快速且影响范围最小的自动断点续训功能,以此保障训练过程的连续性与稳定性。同时,进一步提升超万卡集群的运维效率,也是当前业界需要破解的关键问题。
另一方面,在企业级场景中,企业对数据隐私保护的严苛要求、对实时响应能力的高度重视,以及对定制化服务的迫切追求,也正在促使大模型从传统的“云端集中训练”模式,逐步向“本地私有化部署”方向转型,并催生出了大模型一体机的流行,但如何在单机硬件约束下实现与超大算力集群相近的性能要求,同样也成为大模型一体机未来技术发展道路上亟待攻克的核心挑战。
不仅如此,液冷技术、异构计算等技术创新也正快速融入智算中心的建设与运营之中,这也使得构建一套更为绿色、高效的算力供给体系成为当务之急。可以说,算力领域的每一次重大突破与创新,在为数字经济构筑起坚实底层支撑、推动其蓬勃发展的同时,也如同打开了“潘多拉魔盒”,带来了一系列前所未有的全新挑战。

也正因此,在近期举办的联想创新科技大会(LenovoTechWorld2025)上,联想基于对AI技术演进与产业变革的深刻洞察,正式发布六大创新技术与两大重磅升级。其中,面对AI技术迭代与用户需求变迁的双重挑战,联想从算力性能优化、核心算法突破、算力服务创新等维度发布六大创新技术,同步推出联想万全异构智算平台3.0版本,并实现计算力、存储力、运载力的全线升级,这一系列布局标志着联想正以“AI算力满天星”为愿景,构建出支撑千行百业智能化转型的数字基石。
正如联想集团副总裁、中国基础设施业务群总经理陈振宽所言:“此次六大创新技术的发布与两大重磅升级,是联想中国基础设施业务群坚持“一横五纵”战略布局的成果。未来,我们将继续深挖技术创新潜力,积极构建生态,通过打造持续迭代的混合式基础设施,致力于成为加速中国本地AI持续发展的技术引擎。”

联想集团副总裁、中国基础设施业务群总经理陈振宽
从这个角度来看,在这场AI驱动的产业重构中,联想正以创新者的姿态,通过构建更强大、更高效、更稳定、更绿色的混合式基础设施,书写出千行百业数智化转型的新篇章。
01.
异构智算平台再进化,
突破算力应用全新边界
众所周知,随着AI技术的不断发展,多种AI算力芯片的出现使算力基础设施面临异构化挑战,因此如何搭建智能异构算力平台、突破芯片算力适配度等关键技术的出现就显得至关重要。
在此背景下,联想于去年前瞻性的发布了联想万全异构智算平台。在联想中国基础设施业务群战略管理部总监黄山看来,如果说去年企业用户的核心诉求是聚焦于算力利用率的提升和大规模训练集群的稳定性,但随着今年DeepSeek等AI大模型的“横空出世”,则激发了千行百业数以万计用户投身AI应用开发的热情,而这一转变不仅催生了AI推理与后训练算力的井喷式需求,同时也给异构智算平台提出了更为严苛的要求。

联想中国基础设施业务群战略管理部总监黄山
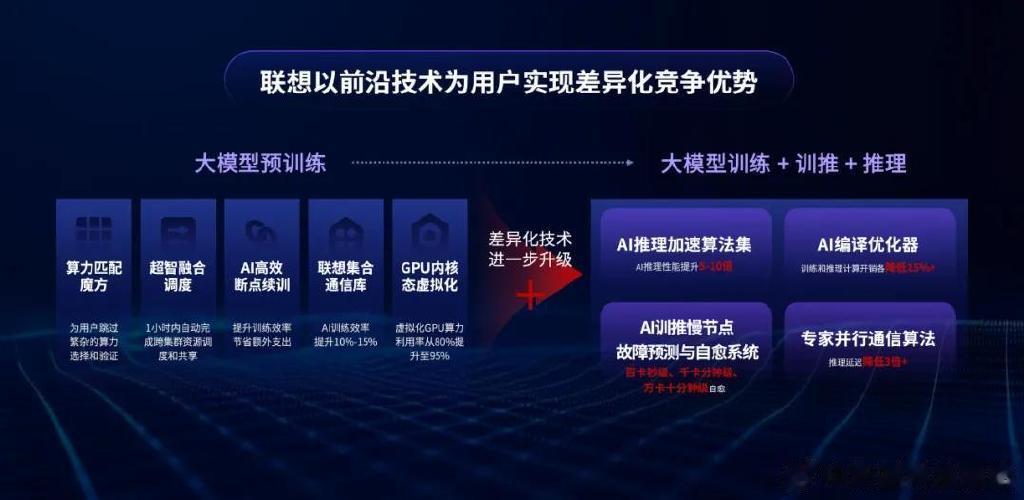
基于此,联想万全异构智算平台3.0版本“应运而生”,它以四大差异化技术创新优势,在AI预训练、后训练及推理过程中,能够帮助企业用户进一步构筑起高效稳定的算力基石。
一是,AI推理加速算法集,该技术突破了推理吞吐量与延迟瓶颈,实现了算力效率的指数级提升,同时可确保每位用户在AI交互中的极致流畅体验。AI推理加速算法集的研发,始于联想对MMA等业界前沿方法的工程实践落地,并融合了联想在混合精度量化、分布式并行等领域的深厚积累进行二次优化。目前,该算法集已将DeepSeek等大模型的推理性能提升5至10倍,并成功攻克千问3模型。在单台8KGPU的服务器上,采用该平台后,可支持190路用户同时使用DeepSeek满血版,较业界最优社区方案保持20%以上的性能优势。
二是,AI编译优化器,该技术从底层重构计算图,有效降低了分布式AI训推的计算开销。联想AI编译优化器在构建计算图时,采用临近算子融合、高效算子替代及等价简化计算路径等技术,大幅精简计算过程。其中,算子优化还融入了联想与GPU战略伙伴的联合研发成果。实践证明,经AI编译优化器优化的AI计算图,可使AI训练后推理的计算开销降低至少15%,且随着分布式训练或推理规模的扩大,优化效果将愈发显著。
三是,AI训推慢节点故障预测与自愈系统,能够主动防御GPU集群级故障,保障算力高可用性。在分布式训推过程中,如何确保算力的高可用性十分重要。为应对这一挑战,联想万全异构智算平台推出了AI训推慢节点故障预测与自愈系统,该系统基于联想在AI训推实践中积累的三年以上的故障特征库,并训练了故障预测模型,即利用AI模型预测AI故障。在预测到故障时,系统通过异步训练检查点或异步推理备份,准备好故障恢复所需环境。一旦故障发生,系统将自动定位并排除故障点,通过多机缓存急速读取和恢复训推环境。目前,联想万全异构智算平台在AI训推中的故障自愈时间已达到百卡集群故障秒级恢复、千卡分钟级恢复、万卡十分钟级以内恢复的业界领先水平。
四是,专家并行通信算法,则有效破解了MoE架构指数级通信瓶颈,最大化释放专家模型潜力。以DeepSeek为代表的AI大模型采用的MoE架构显著节省了模型训推算力开销,但也带来了新的挑战,即在MoE模型中,由于各专家间需不断通信、协同计算,导致多个GPU间频繁交互,这种通信方式称为“alltoall”,其通信量远超稠密模型,所以MoE模型训推优化的前提是全面考虑“alltoall”通信与数据网络的协同优化。基于此,联想研发了一种细粒度更高的专家并行通信算法,该算法在底层核函数层面实现了计算过程与通信过程的高度并行,使两者耗时尽可能相互掩盖,从而大幅提高推理响应速度,将推理延迟降低3倍以上,网络带宽利用率从50%提升至90%。
事实上,联想万全异构智算平台的这些技术创新成果并非是“一蹴而就”的,而是历经长期积累与实践沉淀而来,特别是相比业界其他平台方案,全新进化的联想万全异构智算平台更具备“碾压式”的技术优势。
从实际效果看,联想万全异构智算平台通过推理性能调优,让联想万全AI一体机以12000tokens/s的惊人速度刷新了业界的记录,而友商的产品则没有超过6000tokens/s;从具体应用场景看,联想万全异构智算平台也可同时支持60至150个客户稳定运行,且能确保每个客户都能获得近乎满血的性能体验,而目前市场上尚无其他友商能够提供“一台机器支持如此多用户满血运行”的解决方案。
黄山强调表示:“为满足不同规模用户的多样化需求,联想已做好充分准备。无论是用户希望在更大范围内全面铺开AI开发,构建集群化架构,还是总部为分支机构部署高性能服务,同时分支机构基于自身业务需求,利用合适的模型构建私有化一体机,联想都能提供适配的技术方案。”
不难看出,在AI浪潮汹涌澎湃的时代,智算能力的异构化挑战如同一座巍峨的山峰,横亘在行业发展的道路上,而联想万全异构智算平台从去年五大创新技术的集成,到今年3.0版本四大差异化技术创新优势的展现,通过不断突破算力应用的新边界,其价值远不止于为AI大模型的训练和推理筑牢坚实的算力根基,更一跃成为了推动行业和企业数智化转型的强大引擎,它犹如春风化雨般走进千行百业,真正为每一个组织、每一家企业注入源源不断的智算力。
02.
算力服务器家族升级,
满足AI全场景新需求
与此同时,数智化场景的爆发式增长与算法模型的迭代演进,也对支撑数字经济发展的底层算力基础设施形成了新的考验。根据IDC的报告显示,中国正引领全球人工智能市场创新,预计到2029年,加速计算市场规模将突破千亿美元大关,五年复合增长率超35%;按照IDC的预测,到2025年中国服务器市场中加速计算占比将超52%,至2029年这一比例有望突破70%。
加速计算服务器需求的持续攀升,背后也映射出AI技术在企业应用中的深度渗透,更标志着人工智能已迈入后训练时代,同样联想服务器也“与时俱进”顺应时代浪潮,实现算力架构的全面进化,并推出覆盖AI全场景的新一代服务器产品家族。

联想中国基础设施业务群服务器产品部总经理周韬
对此,联想中国基础设施业务群服务器产品部总经理周韬认为,目前行业用户从业务数据到智能服务的转化需经历三个关键阶段:数据准备阶段需整合公共数据与私有业务数据,构建高质量数据底座,此过程犹如燃料提纯,需依赖强大数据处理算力支撑;而模型训练阶段通过神经网络将海量数据转化为智能模型,此阶段如同燃料熔炼,需要AI训练算力的持续赋能;而模型优化阶段则需结合企业特性进行定制化调优,最终通过推理应用实现智能决策与端边协同,此过程需要推理算力的精准保障。最为关键的是,整个转化链条对算力的需求已超越单一硬件维度,而是涵盖数据处理、AI训练、推理应用的全栈算力解决方案。
据了解,联想新一代算力服务器家族的升级,除了遵循联想长期以来坚持的“三高一低”设计理念之外,同时在“更强大、更稳定、更高效、更绿色”方面也实现了重要突破,具体来看:

首先,在数据处理场景,数据处理对CPU算力要求高,设计上需注重密度,这对提升性能很关键,而联想新一代数据处理服务器在13U标准机柜中实现48节点高密度部署,单柜可配置12288个英特尔®至强®6性能核心与8800MHzMRDIMM内存,配合专利无滴漏不锈钢盲插系统与航空级防松连接装置,构建出全液冷高密度计算平台。该方案通过16节点全液冷设计,在Turbo模式下可大幅提升算力效率,同时消除风扇振动隐患,实现空间与能效的双重优化。
其次,在模型训练场景,最核心的还是在GPU的支持上,因此需要着重考虑功耗问题,因为GPU的功耗是远远大于CPU功耗的。为此,联想推出搭载双英特尔®至强®6处理器与8块GPU卡的AI训练服务器,通过OAM互联技术释放澎湃算力。同时,针对GPU与CPU功耗攀升趋势,联想还创新采用冷板式液冷方案,并为600瓦以上处理器提供浸没式液冷技术,构建绿色节能的算力底座。此外,依托联想万全异构智算平台,可实现异构算力智能调度与故障自愈,通过异步读写优化与实时故障感知,保障训练过程的连续性。AI编译优化器在训练过程中自动完成算子替换与路径优化,降低训练成本超15%。实测数据显示,8卡GPU服务器结合异构智算平台可实现每秒12000tokens的吞吐量,该纪录仍在持续刷新。
最后,在推理应用场景,其服务器要求会更多地考虑平台的通用性,既能够支持GPU,也要支持各种内存、网卡等等,因此联想新一代推理服务器搭载英特尔®至强®6处理器与主流PCIEGPU,每个CPU核心集成AMXBF16/INT16加速器,实现CPU与GPU的深度协同。与此同时,通过双子星、神盾、鹰眼等创新技术,联想服务器可靠性还获得了24万小时MTBF认证。除此之外,模块化设计配合BF智能运维模块,可根据负载动态优化资源配置,提供全液冷散热方案。结合处理器的能效优势,该系列服务器可实现2倍性能提升与4倍能效比。
由此可见,联想算力服务器家族直击行业AI应用落地的关键痛点,从算力优化到场景适配,从资源调度到应用部署,提供了“一站式”的解决方案,而在细节上,其“更强大、更稳定、更高效、更绿色”的四大特性,则能为企业AI应用落地提供坚实保障,助力企业在AI时代快速实现创新与发展。
03.
联想以创新者的姿态,
引领行业智能化迈向新高度
值得一提的是,在本次大会上,联想不仅推出了联想万全异构智算平台3.0版本,完成算力服务器家族的全面迭代升级,更以创新为引擎,以生态为纽带,以进化为使命,持续引领行业智能化迈向新高度。
第一,构建AI核心基础设施,筑牢全场景算力根基。当前,联想正深度构建以计算力、存储力、运载力为核心的AI基础设施,打造覆盖AI全场景、性能领先的AI算力产品组合。

在计算力层面,联想打造了多元且强大的AI服务器家族,包括针对AI训练场景,推出联想问天WA7880a家族等算力利器;数据处理环节,联想ThinkSystemSC750V4服务器高效支撑;推理应用领域,联想问天WA5480G5、WR5220G5,以及ThinkSystemSR650V4、SR650aV4、SR630V4等服务器精准发力,充分释放AI服务器的澎湃算力潜能。
存储力层面,联想凌拓开启数据管理与架构的全方位革新。从联想问天DXNAI存储解决方案、DXN2000系列、DXN全闪系列,到LenovoThinkSystemDE/DM/DG系列、NetAppASA/AFF/FAS系列,再到AIPodDeepSeek一体机,全新存储产品家族不仅为纯训练、训推一体、推理等场景提供综合架构方案,更与GPU企业紧密协作,加速技术产品落地,精准对接本地行业需求。
此外,运载力方面,联想凭借RoCE/IB多架构融合及低延迟优化技术,构建起适配不同规模AI算力集群的智能网络体系。最新发布的高密度400G交换机联想问天NE8770-64QC,专为AI场景深度定制,RDMA端到端无损转发实现微秒级传输延迟,硬件级冗余保护架构确保99.999%业务连续性。同期亮相的多业务核心交换机联想问天NE7550G-8C与新一代高性能核心交换机联想问天NE9770G-4C,也为网络性能提升注入强劲动力。
第二,通过跨领域合作,积极构建更加开放的AI生态。联想深知,AI技术的普惠与发展离不开生态的共建与共享。因此,联想也积极与合作伙伴携手,共同打造AI生态,实现从芯片、系统再到应用的全栈能力整合。
其中,联想与清华大学携手开展联合创新,在相变式浸没液冷技术领域取得突破,通过外部温控调节大幅提升散热效率,为数据中心节能降耗提供创新方案;在国产化芯片适配上,联想全面支持多种国产CPU和GPU,推动国产化算力基础设施蓬勃发展;大模型生态集成方面,联想万全异构智算平台与DeepSeek、千问等主流大模型深度融合,提供从硬件到算法的一站式解决方案,降低企业AI应用门槛。

第三,面对AI技术迭代与产业变革的双重挑战,联想也将持续以创新为刃,破局前行。比如,在国产化性能优化上,针对国产芯片与非国产化产品的性能差异,联想通过深度调优与合作研发,逐步缩小差距,提升国产化算力竞争力;而产品线扩展上,联想未来也将依托“1+3+N”战略,支持多类型CPU与GPU的灵活组合,满足从边缘计算到云端部署的多样化需求。
总的来说,在这场AI驱动的产业重构中,联想正以创新者的姿态,基于“AI算力满天星”,照亮产业新征程,持续为数字经济筑牢底层支撑,为千行百业注入智算力,进一步书写智能化转型的新篇章。